DigitalOcean 开发者沙龙上海站落幕:五大硬核议题拆解 AIGC 落地的真实挑战
本次 DigitalOcean 开发者沙龙以完整的技术链路,呈现了 AIGC 落地过程中最重要关键技术与实践经验。

在 AIGC 从概念迈向大规模落地的当下,“如何优雅地玩转训练、推理与知识库”,已经成为一线工程团队绕不过去的问题。11 月 15 日,继 6 月北京站之后,DigitalOcean 开发者沙龙来到了上海,围绕算力、存储、知识基座与大模型推理优化等“硬核议题”,与现场开发者、架构师和技术管理者展开了一场深入而务实的技术对话。

本次沙龙延续了活动预告中的几大核心提问:
当 AMD ROCm 等开源生态迅猛发展,如何在复杂的硬件与软件选型中构建稳定且高效的 AI 算力底座?当模型与数据规模迈向数十 TB、PB 级别,存储系统是否还能跟上 GPU 的速度?当传统 RAG 面临知识“扁平化”的瓶颈,图技术能否成为 LLM 时代的“世界理解基座”?而在走向 DeepSeek 这类 MoE 大模型架构后,如何把推理性能真正“拉满”,突破延迟与成本的双重极限?
围绕这些问题,本次活动邀请到了来自 AMD、Juicedata、DigitalOcean、NebulaGraph、PPIO 等公司的技术专家,从开源 GPU 软件栈、云原生高性能存储、全球算力资源布局、图数据库与 RAG 演进、MoE 推理优化等多个维度,分享他们在一线实践中的真实经验与思考。下面,我们就通过五个精彩演讲,一起回顾这场围绕“如何优雅地玩转 AIGC”的深度技术沙龙。
AMD ROCm 开源软件及生态,赋能 AI 开发者

在此次演讲中,AMD 高级 AI 架构师李皓 向现场观众系统介绍了 AMD ROCm™ 如何实现“软件无处不在”,并重点展示了 ROCm 7.0 在生成式 AI 与大模型时代的全栈能力。他强调,从本地开发到企业级集群部署,ROCm 覆盖 AMD Instinct、Radeon AI GPU 等多种硬件平台,实现训练与推理的统一加速。
ROCm 的核心竞争力来自 开放性与广泛兼容性。ROCm 不仅支持主流 AI 框架,还包括 Mooncake、Torch Helion 等新兴生态。同时,ROCm 提供了专业的分析工具,包括 rocprofiler-compute 和 torchprofiler,使开发者能够更准确地定位性能瓶颈、优化大模型运行效率。

在部署方面,他介绍了 ROCm 在容器化和云端的完善布局:从 Docker、Kubernetes、Singularity,到 AMD Dev Cloud ,再到对 Llama.cpp HIP 加速的支持,助力开发者实现从本地开发、容器测试到云端扩展的灵活模型构建与迁移路径。
ROCm 不只是一个 GPU 软件平台,而是 AMD 构建 AI 开放生态的底座。
JuiceFS:AIGC 背后的存储挑战与 落地方案

在 Juicedata 解决方案架构师 蔡敏 的演讲里,他系统阐述了 AIGC 时代存储系统面临的挑战,并介绍 JuiceFS 在大模型训练、推理和多云部署中的落地实践。
AIGC 业务的多模态特征——从 LLM 文生文,到 Diffusion 文生图,再到音频与视频生成——带来了海量数据、巨量文件数与极端性能需求。典型大模型企业的数据规模可达数十 PB、文件数量超过百亿,业务吞吐量需要达到 400GB/s、IOPS 超过千万级,这对底层存储提出了前所未有的要求。
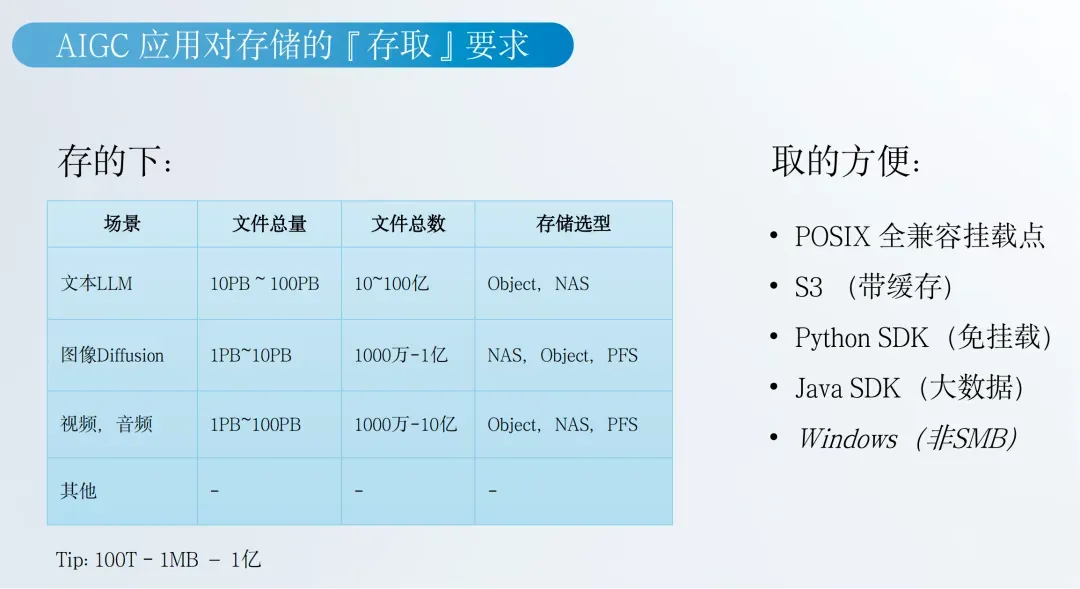
在剖析技术难点时,他详细比较了传统 NAS 与对象存储在 AIGC 场景中的局限,包括协议瓶颈、缺乏元数据语义、性能受限、无缓存机制等。随着模型规模和算力集群的不断扩张,企业急需一种既兼容 POSIX、又具备云原生特性的高性能分布式文件系统。
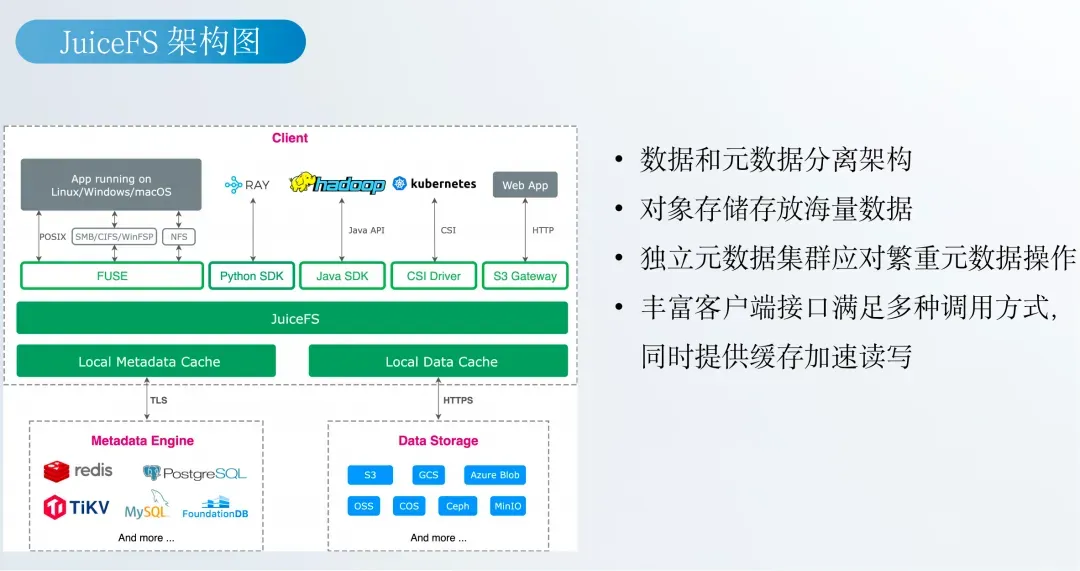
对此,他介绍了 JuiceFS 的技术架构:通过“元数据与数据分离”的方式,将大规模数据存于对象存储,并以独立元数据服务补齐语义能力,同时提供多级缓存与多种访问接口,以实现高吞吐、低延迟访问。针对超大规模 AI 训练场景,JuiceFS 还提供可扩展的分布式缓存集群与多种元数据引擎,以支持从数亿到千亿级文件规模。同时,他还分享了一些落地案例。
如何构建 AI 训练与推理的算力资源

DigitalOcean Cloud Solutions Expert、卓普云科技解决方案架构师 丁可 在演讲中,全面介绍了 DigitalOcean 在全球 AI 基础设施领域的最新布局,展示了 DigitalOcean 从 GPU 云、Kubernetes、存储到 GenAI 平台的一整套解决方案,帮助企业快速构建 AI 训练与推理平台。
丁可首先回顾了 DigitalOcean 十余年的云服务发展历程,并强调公司在收购 Paperspace、引入原 AWS 与 NVIDIA 高管 Bratin Saha 后,在 AI 产品路径与 GPU 云能力上实现了显著跃升。当前 DigitalOcean 已覆盖全球 16 个数据中心,为 63.8 万客户提供服务,是全球增长最快的中型云平台之一。
在算力方面,他重点介绍了 DigitalOcean 现阶段提供的多类 GPU,包括 NVIDIA H200/H100、L40S/RTX 系列、AMD MI325X 等,并透露 最新 Blackwell 架构的 GPU 与 MI350X 将在未来上线,继续完善从推理到大模型训练的全链路算力供应。部分 GPU 价格低至每小时 $0.76,大幅降低企业的 AI 部署成本。

丁可指出,AI 基础设施不止于 GPU。DigitalOcean 通过 Gradient AI Platform、托管 Kubernetes(DOKS)、一键部署模型、高性能推理镜像、对象存储与高性能 NFS 等产品,帮助企业以更低运维成本构建端到端的 AI 工作流。从 serverless 到多卡训练,从 Hugging Face 模型加速到多模态推理端点,整个流程可在数分钟内完成部署。
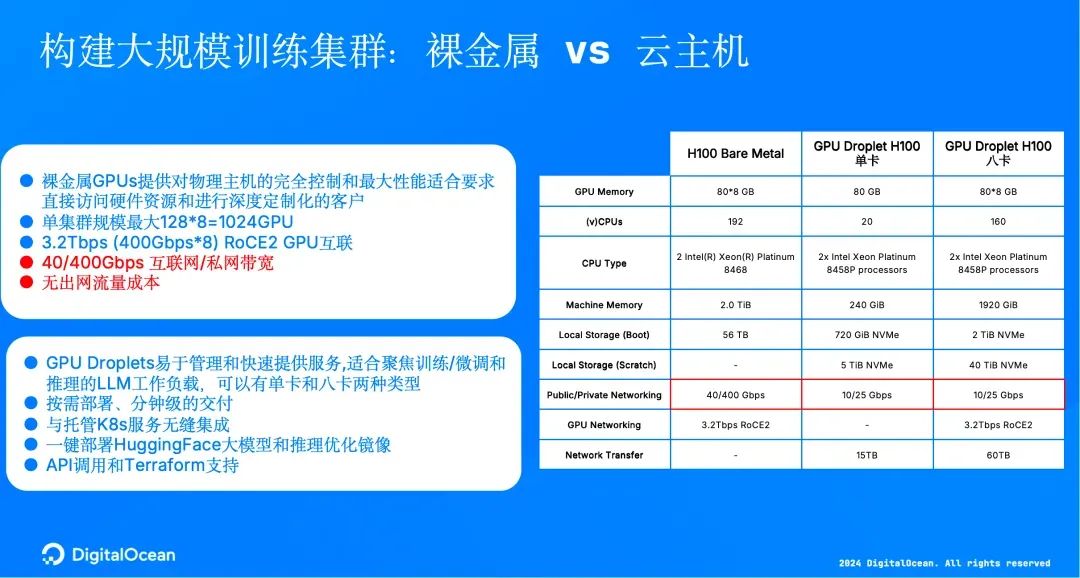
演讲也展示了 DigitalOcean 在训练场景中的竞争优势:
- 裸金属 GPU 集群支持 最高 1024 卡规模;
- GPU 间 3.2Tbps RoCE2 超高速互联,无 spine 架构、一跳通信;
- 无出网费用,使跨区域推理与数据流转更加经济可控。
此外,丁可介绍了多模态 Serverless 推理能力,包括文生图(SDXL、FLUX)、文生音、TTS 多语言等模型支持,并展示了 DigitalOcean 与 llm-d 等开源项目的深度合作,使企业能在 DOKS 上快速部署分布式推理框架。
图即基座:NebulaGraph 在 LLM 时代的角色

在 NebulaGraph GenAI 团队成员 尚卓燃 的演讲中,他深入剖析了传统 RAG 在 AIGC 时代遭遇的结构性瓶颈,并提出“图即基座”(Graph as the Foundation)这一全新范式,系统阐述了图技术如何成为大模型时代不可或缺的事实基座与推理基座。
他指出,当前主流 RAG 依赖文本分块与向量检索,本质上将知识“扁平化”,导致细粒度实体丢失、关系链断裂、多跳推理失效——尤其在面对“供应链中断是否导致某型号故障”这类需要跨时间、跨领域推理的问题时,表现乏力。
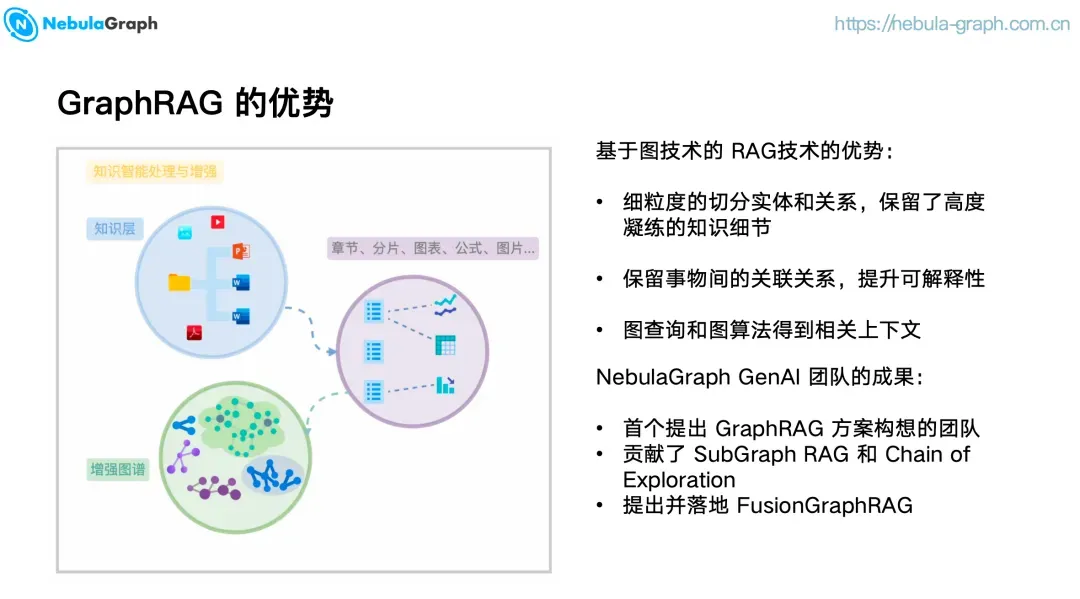
为此,NebulaGraph 团队率先提出并落地多项关键技术:SubGraph RAG、Chain of Exploration(CoE),以及 FusionGraphRAG。其中 FusionGraphRAG 可大幅降低建图成本(↓ 约 80%),综合准确率领先业界约 10%。
在工程层面,NebulaGraph 已深度集成向量、全文与图结构的混合检索能力,并贡献 LlamaIndex MCP ToolSpec 至上游社区,率先实践 Local MCP 范式,推动图成为大模型可直接调用的“原生工具”。最后,他还分享了其技术在工业与金融领域的解决方案。
破局大规模 LLM 服务:MoE 推理的性能优化之道

在 PPIO AI 推理加速高级算法工程师 金明熠 的演讲中,他聚焦大规模 MoE(Mixture of Experts)模型在线服务的工程挑战,系统剖析了千亿参数级模型在高并发推理场景下面临的延迟与资源瓶颈,并介绍了 PPIO 在 DeepSeek 等模型服务中落地的多项核心技术优化。
他指出,以 DeepSeek 为代表的现代 MoE 模型(如 256 专家、每次激活 8 个)虽提升了训练效率,但在实现最佳计算效率、高内存和通信压力以及处理模型动态和稀疏性方面带来了额外挑战:不仅需跨多卡加载海量参数,专家路由引发的动态 token 分发与 All-to-All 通信亦成为性能关键路径——若不加优化,ITL(Inter-Token Latency)可达 300ms 量级。
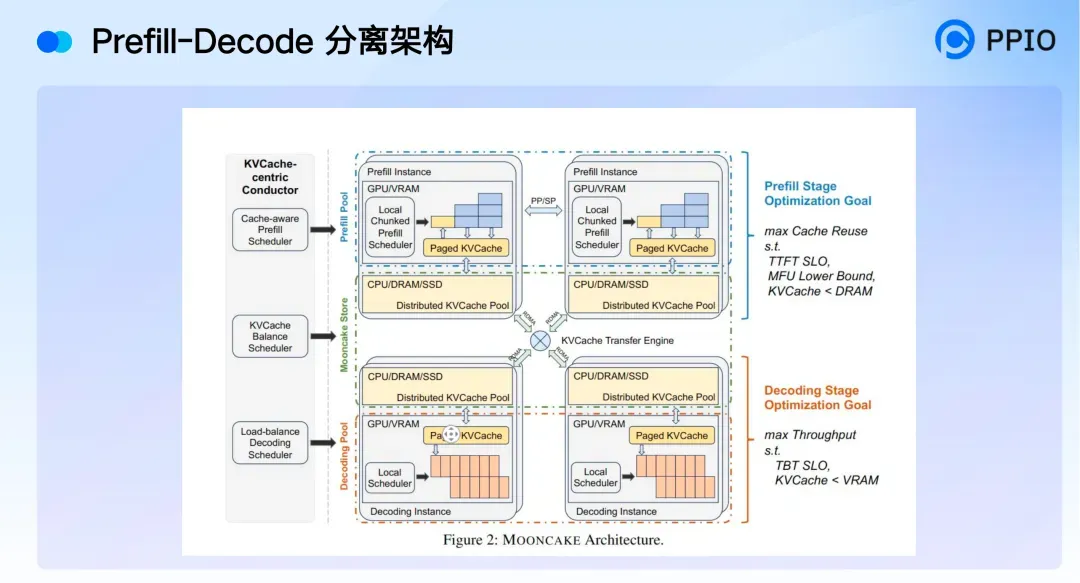
对此,PPIO 提出了多项核心优化策略:专家并行(EP)与专家负载均衡(EPLB)、计算-通信重叠(Computation-Communication Overlap)、Prefill-Decode 分离架构、Prefix Cache 分层缓存机制、多 Token 预测(MTP)集成。
写在最后
随着五位嘉宾的深度分享,本次 DigitalOcean 开发者沙龙以完整的技术链路,呈现了 AIGC 落地过程中最重要的四个底座:算力、存储、知识结构化与高效推理。从硬件到软件、从本地到云端、从模型工具链到工程优化,每一个环节都在快速迭代,而这也意味着企业与开发者正站在一个前所未有的创新窗口期。
无论是 AMD 推动的开源 AI 生态,JuiceFS 应对 PB 级数据的高并发挑战,DigitalOcean 打造的全球 GPU 云平台,NebulaGraph 构建的“图即基座”,还是 PPIO 在 MoE 推理上的极限优化,这些实践共同展示了 AIGC 的未来图景:更加开放、更具弹性、更注重工程效率,也更强调真实业务的落地价值。
DigitalOcean 未来将继续携手生态伙伴,把最前沿的算力产品、模型工具链与开发者平台带给中国企业出海用户与全球开发者,为 AI 的规模化落地提供稳健且具性价比的基础设施支持。至此,上海站的分享圆满落幕,但 AIGC 技术的探索仍在继续。下一站,更多关于训练、推理和知识系统建设的答案,将在实践中不断被刷新。如果你需要了解更多关于 DigitalOcean 云平台在 AI 方面的产品详情,可咨询 DigitalOcean 中国区独家战略合作伙伴卓普云 aidroplet.com。


