Hugging Face 的生成式 AI 服务(HUGS)让部署和管理大语言模型(LLMs)变得更加简单和快捷。现在,借助 DigitalOcean 的一键部署功能,你可以在 GPU Droplet 云服务器上轻松设置、扩展和优化 LLMs,这些 Droplet (DigitalOcean 的云主机)专门针对高性能业务场景进行了优化。本文将一步步带领你完成在 DigitalOcean GPU Droplet 上部署 HUGS 并集成 Open WebUI 的步骤,过程只需要 5 步,完成后你就能理解为什么说一键部署可以让 LLM 推理模型的使用更流畅、可扩展。
准备工作
- 一个 DigitalOcean 云服务的账户,免费注册,注册后还可获得 200 美元使用额度。
- 在 DigitalOcean 后台开启一个已经部署并运行的 GPU Droplet服务器,以及另一个用于部署和运行 Open WebUI Docker 容器的 Droplet服务器。
- 你需要对 SSH 和基本 Docker 命令有所了解。
- 一个用于登录 Droplet 的 SSH 密钥。
第一步 – 创建并访问你的 GPU Droplet
1、设置 Droplet:
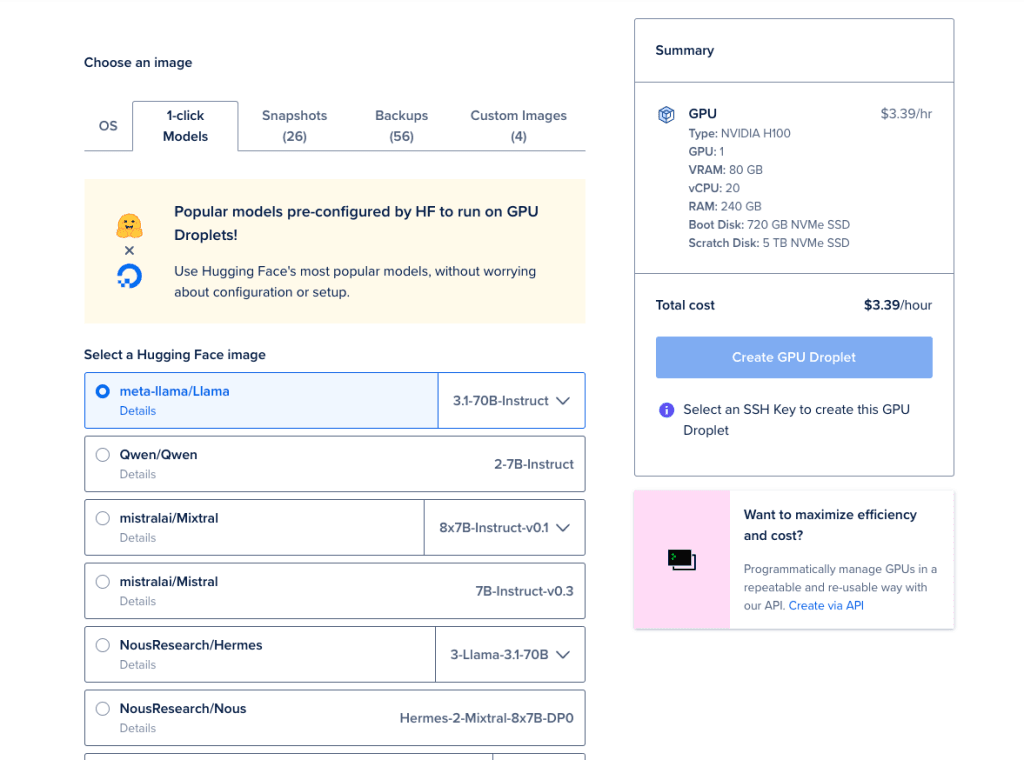
前往 DigitalOcean 的 Droplets 页面,创建一个新的 GPU Droplet。在 “选择镜像” 选项卡下,选择 1-Click Models,并使用其中一个可用的 Hugging Face 镜像(比如图中的 meta-llama/Llama)。
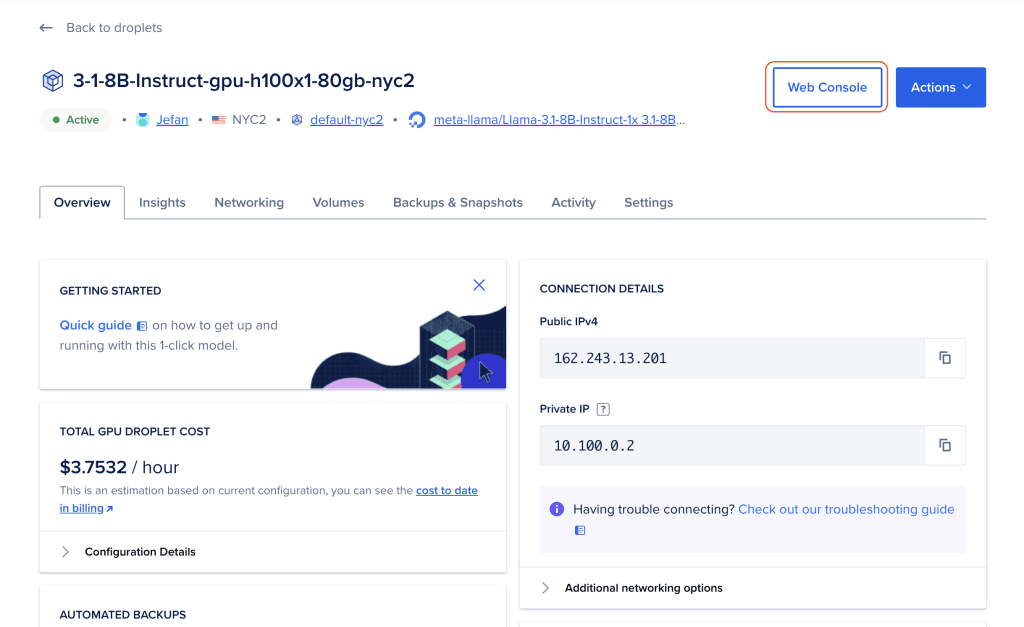
2、访问控制台(console) :
当你的 Droplet 准备好后,点击 Droplets 部分中的你刚刚创建的 Droplet 的名称,然后选择 “启动 Web 控制台” 。
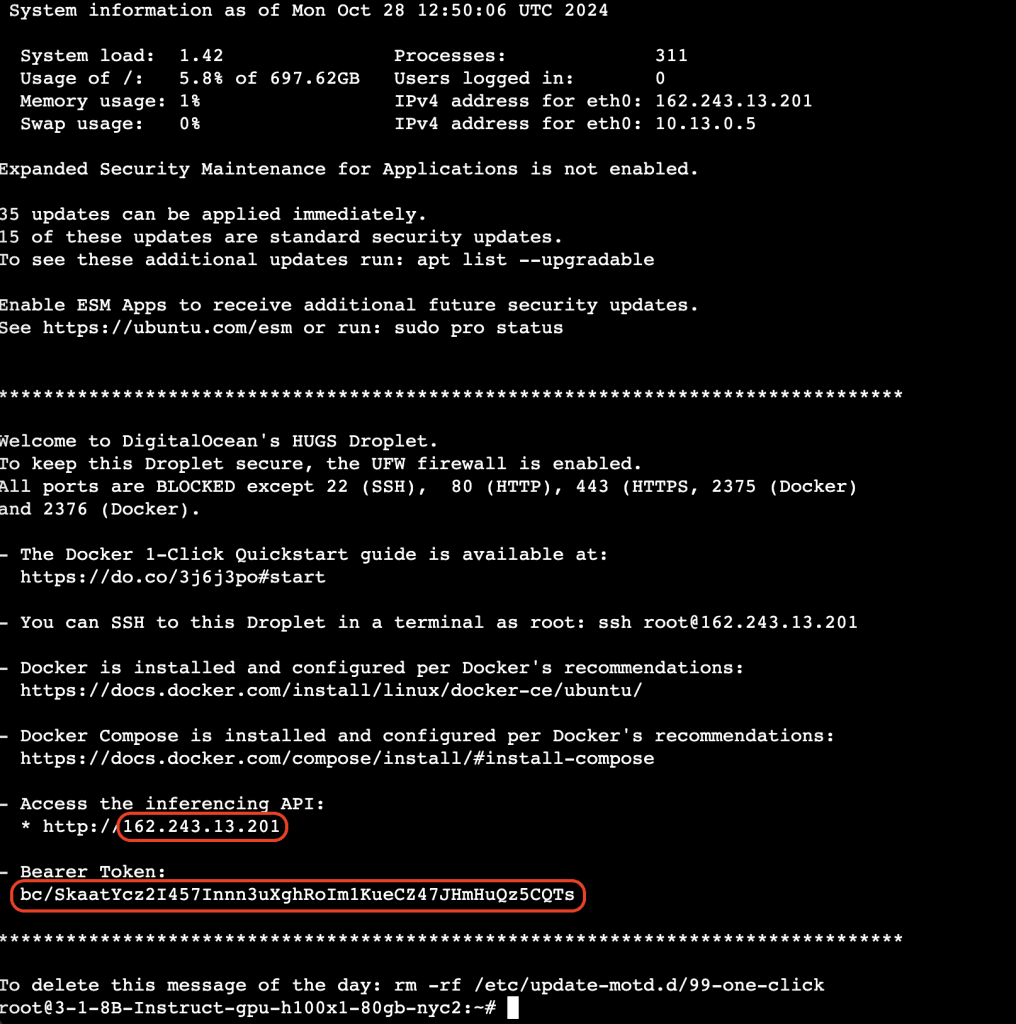
3、请注意“今日消息”(Message of the Day, MOTD):其中包含用于 API 访问的 bearer token 和推理端点(inference endpoint),稍后会用到。
第二步 – 启动 Hugging Face HUGS
Hugging Face HUGS 在 Droplet 设置完成后会自动启动。要验证是否启动成功,可以检查管理推理 API 的 Caddy 服务状态:
sudo systemctl status caddy
输出示例:
● caddy.service - Caddy
Loaded: loaded (/lib/systemd/system/caddy.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/caddy.service.d
└─override.conf
Active: active (running) since Wed 2024-10-30 10:27:10 UTC; 2min 58s ago
Docs: https://caddyserver.com/docs/
Main PID: 8239 (caddy)
Tasks: 17 (limit: 629145)
Memory: 48.8M
CPU: 73ms
CGroup: /system.slice/caddy.service
└─8239 /usr/bin/caddy run --config /etc/caddy/Caddyfile
等待 5-10 分钟,让模型完全加载。
第三步 – 启动 Open WebUI
在另一个 Droplet 上使用 Docker 启动 Open WebUI。请使用以下 Docker 命令运行 Open WebUI Docker 容器:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
当 Open WebUI 运行后,可以通过 http://<your_droplet_ip>:3000 访问它。
第四步 – 将 HUGS 与 Open WebUI 集成
1、打开设置:
在 Open WebUI 中,点击左下角的用户图标,然后点击 “Setting” 设置。
2、导航到“Admin”管理:
转到“Admin”管理选项卡,然后选择Connections。
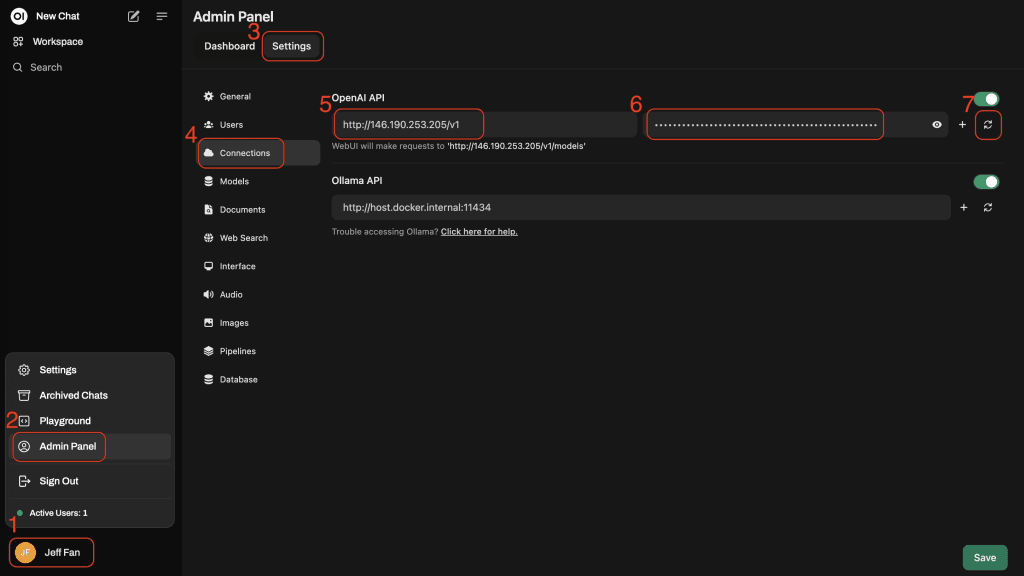
3、设置推理端点:
在 API 链接字段中,输入你的 Droplet IP 地址,后面加上 /v1。如果有特定的端口,也一并包括,例如 http://<your_droplet_ip>/v1。
使用 MOTD 中提供的API Token进行身份验证。
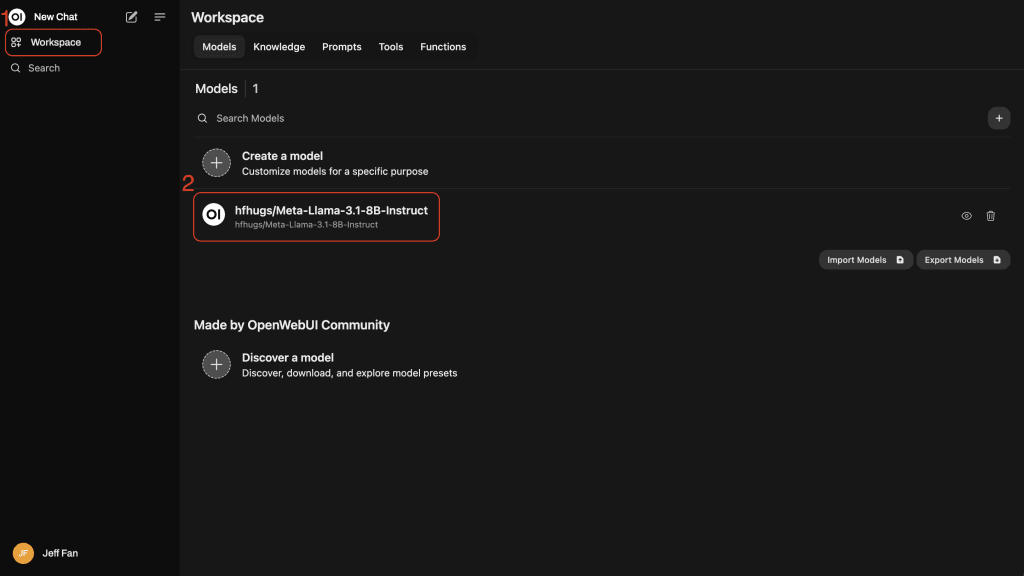
4、验证连接:
点击“验证连接”。绿色指示灯表示连接成功。Open WebUI 将自动检测可用模型,如 hfhgus/Meta-Llama。
第五步 – 开始与模型对话
将 HUGS 集成到 Open WebUI 后,你就可以与 LLM 互动了:
例如,提问“什么是 DigitalOcean?”。
监控容器的日志会回答后续问题:“DigitalOcean 是否提供对象存储?”
sudo docker ps
sudo docker logs <your-container-ID> -f
就是这么简单。
自己部署 HUGS vs.使用 DigitalOcean 的一键部署
Hugging Face HUGS(Hugging Face Hub)的部署虽然相对简化了许多过程,但对于一些用户来说,特别是那些对云端部署和服务集成不熟悉的人,可能会遇到一些麻烦。如果是选择自己来部署 Hugging Face HUGS ,可能会面对一些挑战:
1. 资源要求和计算能力
- 硬件要求:部署和运行大型预训练模型(如 GPT-3 或 BERT)通常需要强大的硬件支持,尤其是 GPU 或 TPUs。如果你没有相应的硬件资源,本地部署会非常吃力。虽然 Hugging Face 提供了云端推理服务,但如果要自己搭建环境,硬件资源可能成为一个瓶颈。
- 云服务 选择:选择适合的云平台(如 AWS、GCP 或 Azure)并配置相应的硬件(如 GPU、TPU)可能需要一定的学习和实验。用户需要对云计算有一定的了解,包括实例选择、价格计算、成本控制等。尤其是有些云服务的使用会非常复杂,而 DigitalOcean 则是以简单易用而受到全球 60 万用户的青睐。
2. 环境配置和依赖管理
- Python 环境管理:部署过程中,确保依赖库的版本匹配非常重要。Hugging Face 依赖很多外部库(如
transformers,datasets,torch等),这些库的版本更新较快,可能会造成版本冲突。如果不同环境之间的依赖库不同,可能会导致部署失败或不稳定。 - Docker 使用:如果通过 Docker 部署 Hugging Face,初学者可能会觉得 Docker 配置和管理较为复杂。正确构建 Docker 容器并确保容器内外的环境一致,需要一定的技术能力。
3. 模型优化和调优
- 模型大小:大型模型往往需要大量的存储空间和内存,因此部署时必须考虑如何优化这些模型。比如,如何减小模型体积、提高加载速度、进行量化或知识蒸馏等。如果你部署的是较大规模的 Transformer 模型(如 GPT-3),模型的加载速度和推理延迟可能会很高。
- 模型微调:如果需要在自己的数据上进行微调,部署和训练可能会更加复杂。微调过程需要处理数据集的准备、超参数的调优、训练时长的计算等。
4. API和服务接口集成
- API 部署:部署 Hugging Face 模型并提供推理 API 可能需要与 web 框架(如 FastAPI、Flask、Django)或微服务架构结合。虽然 Hugging Face 提供了预定义的
transformersAPI,用户仍然需要自行配置 API 服务、请求参数的验证、响应的处理等。 - 负载均衡 和并发处理:如果模型部署后需要处理高并发请求,部署时可能需要配置负载均衡和流量管理系统,确保系统的可扩展性和高可用性。
5. 模型版本控制和更新
- 版本控制:Hugging Face Hub 提供了模型版本控制功能,允许用户管理不同版本的模型。如果你在不断更新和优化模型,需要考虑如何有效地使用版本控制来管理模型的不同版本,并确保每次更新后系统正常工作。
- 更新模型:有时候,新的模型版本会在 Hugging Face Hub 发布,如何快速更新自己部署的模型,同时保持向后兼容和不影响服务的稳定性,是一个技术挑战。
6. 安全性和隐私问题
- API 安全性:如果部署了 Hugging Face 的 API,必须确保其安全性,避免恶意访问。例如,设置认证和授权机制,限制访问权限,保护 API 免受滥用。
- 数据隐私:如果你的模型处理敏感数据(如个人数据),需要确保部署环境遵循相应的隐私保护政策,如 GDPR 或 CCPA。确保数据在传输和存储过程中得到加密,并采取适当的安全措施防止数据泄露。
7. 集成与自动化
- CI/CD 集成:对于需要定期更新和迭代的项目,部署过程的自动化(通过 CI/CD 管道)是必要的。初学者可能会觉得设置自动化测试、持续集成、自动部署等环节比较复杂。
- 多模型部署:如果需要同时部署多个不同的模型,如何管理不同的模型版本,确保每个模型在特定的场景下运行稳定,可能是一个复杂的任务。
8. 日志和监控
- 日志管理:部署后需要监控系统的运行状态,检查模型的输出和推理性能。如果模型推理出现异常,如何查看日志并进行诊断是一个必不可少的步骤。
- 性能监控:部署后的性能监控同样非常重要,确保模型响应时间、吞吐量等满足需求。如果出现瓶颈,需要对资源进行优化和调整。
然而如果选择 DigitalOcean GPU Droplet 的一键部署,你可以跳过以上大部分的后端难题,DigitalOcean 已经在云环境中帮你提前解决了。在 DigitalOcean 上使用 HUGS 的优势在于:
简单部署和简化管理
使用DigitalOcean的一键设置部署HUGS非常简单。无需手动配置——DigitalOcean和Hugging Face会处理后端工作,让您专注于扩展。
针对大规模推理的优化性能
在DigitalOcean GPU上部署的HUGS确保了最优的性能,能够在GPU硬件上高效运行大型语言模型(LLMs),无需手动调整。
可扩展性和灵活性
DigitalOcean的基础设施支持可扩展部署,并配备负载均衡器以实现高可用性,让您能够以低延迟为全球用户提供服务。
通过在DigitalOcean GPU Droplets上使用Hugging Face HUGS,您不仅可以从高性能的大型语言模型推理中受益,还可以轻松地扩展和管理部署。这种优化硬件、可扩展性和简单性的结合,使得DigitalOcean成为生产级AI工作负载的极佳选择。
小结
通过在 DigitalOcean 的 GPU Droplet 上部署 HUGS 并集成 Open WebUI,你可以高效地管理、扩展和优化 LLM 推理。这种设置消除了硬件优化的烦恼,提供了一个随时可扩展的解决方案,能够快速、可靠地响应来自多个地区的请求。
DigitalOcean GPU 云服务是专注 AI 模型训练的云 GPU 服务器租用平台,提供了包括 A5000、A6000、H100 等强大的 GPU 和 IPU 实例,以及透明的定价,可以比其他公共云节省高达70%的计算成本。即日起到 2024 年 12 月 31 日,DigitalOcean GPU Droplet H100 与 H100x8 服务器正在限时优惠,最低仅需 2.5 美元/GPU/小时。如需了解详情,可联系DigitalOcean 中国区独家战略合作伙伴卓普云(aidroplet.com)。