
DigitalOcean 全球负载均衡器(GLB)Beta版正式上线,该解决方案能给客户的跨区域业务带来更好的支持,可以增强应用程序的弹性,消除单点故障,并大幅降低终端用户的延迟。这是 DigitalOcean 负载均衡产品方案的一个里程碑。
DigitalOcean的托管负载均衡器产品(简称 DO-LB)让客户可以将流量传输到托管其应用的 Droplets (云主机)和DigitalOcean Kubernetes 节点,使他们能够轻松提高其基础设施的可扩展性和性能。在本文中,我们将介绍过去几年中 DigitalOcean 将负载均衡器扩展到超过100万个连接的迭代过程。
2018 年 DigitalOcean 负载均衡的架构实现
最初的负载均衡器(LB)架构(2018年发布)是使用我们称之为“负载均衡 Droplet” (以下简称:LB Droplet)的 Droplet 部署的。我们为 LB Droplet 附加了一个 reserved IP,以便在主节点出现异常时切换到另一个 Droplet。这使我们能够通过启动一个新的带有最新版本软件的 LB Droplet,并在其准备好后切换流量来执行负载均衡器的升级。这种方法的缺点是,在切换 LB Droplet 期间,所有现有连接将丢失,客户端需要重新建立与负载均衡器的连接。
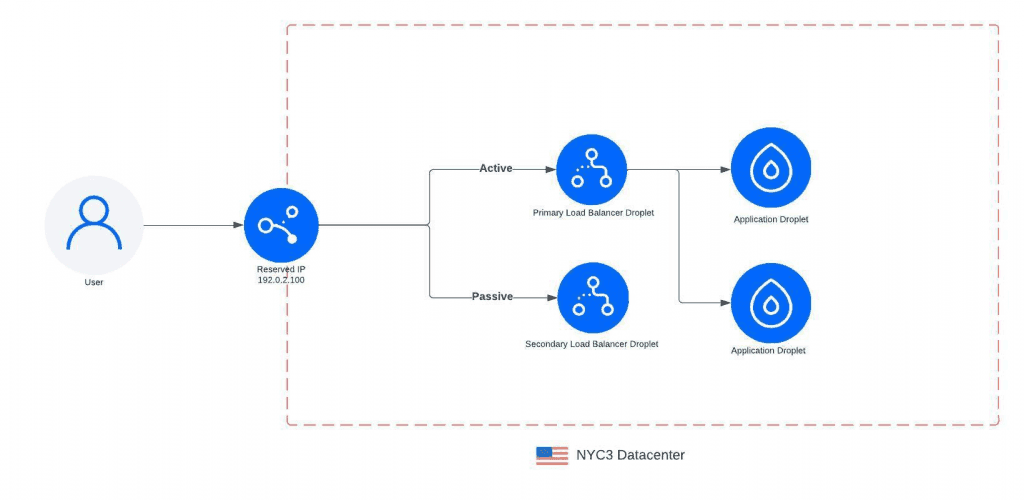 随着时间的推移,DigitalOcean 从客户那里了解到他们需要更高的扩展性,需要更多的连接或更多的吞吐量。DigitalOcean 在 2020 年推出了一个可调整大小的负载均衡器,有 S/M/L 尺寸,并垂直扩展了 LB Droplet。最初的负载均衡产品基于 1 个 vCPU 的 Droplet,M号和L号基于 2 个 CPU 和 4 个 CPU 的 Droplet。这些扩展的资源使 M号和L号负载均衡器能够处理更大的工作负载,让客户可以通过他们的负载均衡器承载更多的流量,并扩展工作负载。我们知道这不会解决所有客户的需求,但这是我们在扩展到更高和支持更高工作负载的过程中的第一个里程碑。
随着时间的推移,DigitalOcean 从客户那里了解到他们需要更高的扩展性,需要更多的连接或更多的吞吐量。DigitalOcean 在 2020 年推出了一个可调整大小的负载均衡器,有 S/M/L 尺寸,并垂直扩展了 LB Droplet。最初的负载均衡产品基于 1 个 vCPU 的 Droplet,M号和L号基于 2 个 CPU 和 4 个 CPU 的 Droplet。这些扩展的资源使 M号和L号负载均衡器能够处理更大的工作负载,让客户可以通过他们的负载均衡器承载更多的流量,并扩展工作负载。我们知道这不会解决所有客户的需求,但这是我们在扩展到更高和支持更高工作负载的过程中的第一个里程碑。
在 2021 年,开始设计下一轮迭代,产品团队列出了希望实现一些目标,包括:
- 扩展到100万+连接
- 高可用性,确保当单个 LB Droplet 不可用时,LB 不会下线
- 保持简单的定价
我们希望客户能够扩展他们的负载均衡,但会有一个固定的价格,这样他们就会预先知道月底的账单是多少。
考虑后续技术改进方案
我们考虑过迁移到一个部署在裸金属上的基于Kubernetes的解决方案,但这带来了许多挑战。例如:
1、我们的部署规模很大,以至于我们需要在每个数据中心部署和管理许多独立的集群。我们的团队需要管理 noisy neighbour 问题(当一个租户的性能由于另一个额租户的活动而下降时就会出现这个问题),以及管理多租户计算的许多复杂性。DigitalOcean 的其他团队已经为我们管理了这个问题,所以我们不用重复造车轮了。
2、LB Droplet 和 客户的 Droplet 之间的路径发生在他们的 VPC 网络上,由于 LB Droplets 位于客户的 VPC 内,我们可以管理它。我们需要基于这个裸金属 Kubernetes 集群构建一个新的 VPC 数据路径,以实现与客户 Droplets 的连接。每个 pod 都需要进入 VPC,这使 pod 生命周期变得相当复杂。我们需要为每个 Pod 从 VPC 分配一个 IP,它需要从 VPC 中添加/删除以形成 VPC 网格,我们需要支持 VPC 流量进出 Pod 的隧道。所有这些编排都需要在 Pod 启动和停止时进行。
我们最终放弃了使用 Kubernetes 的计划,转向了一个保留 LB Droplet 层的解决方案。这大幅减小了工作会涉及的范围,又能继续满足我们最初的设计目标。我们通过向我们的负载均衡器架构添加一个额外的层来实现这一点。这个新层利用了我们部署在裸金属上的直通式网络负载均衡器(network load balancer,NLB)。尽管我们需要部署一个类似于Kubernetes解决方案的裸金属层,但我们所需的计算资源要少得多,而不是像要移动整个L4/L7工作负载那么复杂。NLB 的计算需求比需要终止 TCP 连接、执行TLS握手、处理 HTTP headers 的 HTTP 负载均衡器要少得多。我们也不需要构建和管理一个新的 VPC 数据路径。
新的DigitalOcean负载均衡器的实现
在 NLB 上,我们利用 BGP(边界网关协议)和 ECMP(等价多路径路由)在每个数据中心部署的 N 台服务器上分散流量。我们还利用了一个开源项目 Katran,它让我们在多活架构(active-active architecture)中将连接路由到一个或多个负载均衡 Droplet。
BGP 是一种协议,允许我们配置数据中心内的网络结构,以确定流量应该路由到哪里。ECMP 是 BGP 的一个特性,让我们可以将流量分散到多个独立服务器上。这将每个负载均衡器 IP 变成了数据中心网络结构中的 anycast IP 。根据连接的来源,网络结构将对源 IP、源端口、目标IP、目标端口、协议进行哈希处理,以选择最近的服务器进行路由。每个服务器都部署在一个机架上,并连接到该机架上的ToR(顶部交换机)以及相邻机架上的一个 ToR。这确保了如果某个 ToR 出现故障或需要维护而下线时,系统具有冗余性。此外,我们还可以承受住一个或多个单独的服务器出现故障,因为流量会自动路由到其他健康的服务器上。
深入到这些裸金属服务器,这是我们运行 Katran 的地方,一个 eBPF 程序。这是一个XDP(快速数据路径)程序,位于NIC(网络卡)和内核网络堆栈之间的路径上。这允许数据包直接在 NIC 进行处理,从而实现高性能的负载均衡数据路径。我们的合成测试和真实流量显示,我们可以以极低的CPU使用率使50Gbps的NIC达到饱和。在我们每台服务器的 NIC 本身都是瓶颈。
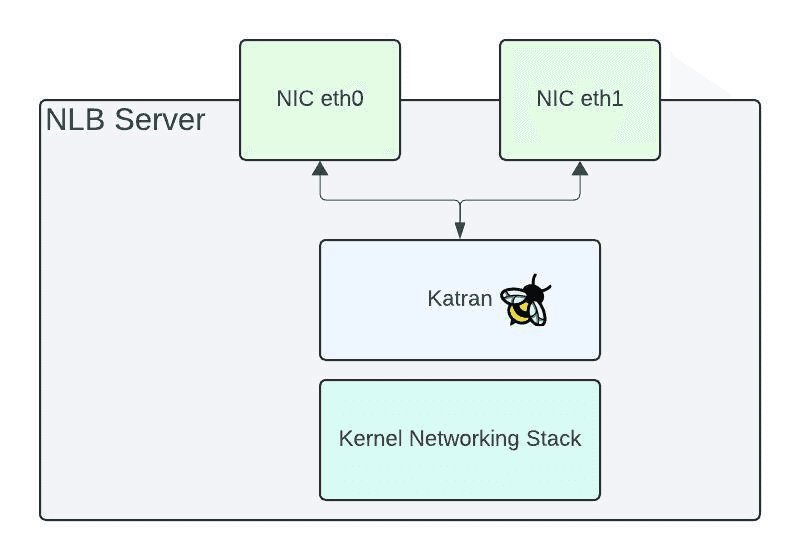
Katran 基于 Google 发布的 Maglev 论文实现,并已在整个行业中得到普及。Katran 基于连接表和/或每个数据包的一致性哈希。当数据包流经服务器时,连接表用于确定将每个数据包路由到哪个后端。如果没有表中的条目,Katran将对数据包执行一致性哈希以选择一个新的后端。然后将条目添加到表中,以便将来的数据包可以路由到同一个后端。网络结构的更改可能导致现有流被路由到完全不同的 NLB 服务器,这可能出于任何原因发生,例如添加/删除NLB服务器,无论是为了增加新容量还是进行维护。在这些事件中,我们将依赖数据包的一致哈希来确保即使流被重新路由到新的NLB服务器,也能保持稳定的路由。我们采取预防措施,确保LB Droplet维护和NLB服务器维护事件不会重叠,这最有可能引起连接重置。
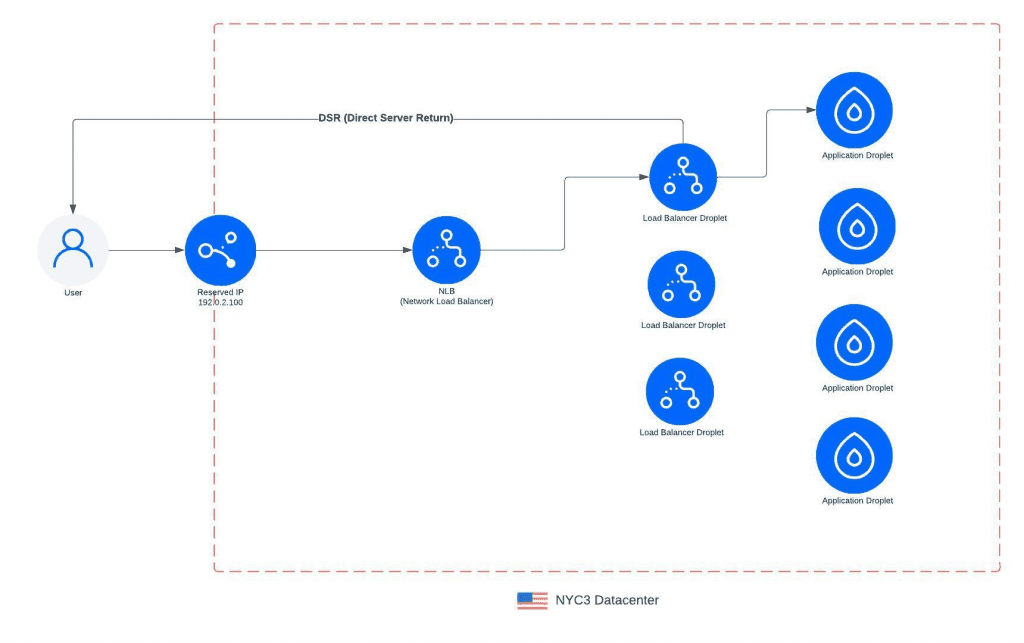
随着新的 NLB 架构的建立,我们将所有客户的负载均衡器迁移到这个新的数据路径,并通过它路由所有流量。NLB将 TCP/UDP 连接负载均衡到其中一个负载均衡器 Droplet。LB Droplet 将终止连接,然后通过其 VPC 将流量负载均衡到客户的应用程序 Droplet。我们还利用 DSR (Direct Server Return),使所有出口流量离开 LB Droplet 并直接返回到客户端。这减少了 NLB 层的负载,而且它只需要扩展到入口流量的大小,通常比出口流量要小得多。
这也使我们能够扩展/缩减 负载均衡 Droplet 容量,在软件升级等维护事件期间轮换 LB Droplet,并将流量转移到新的 Droplet 。我们现在还可以在关闭旧的 负载均衡 Droplet之前 draining 连接。
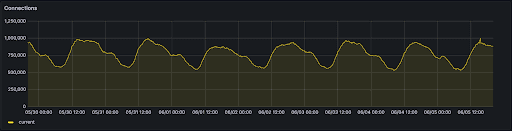
随着对 NetLB 的更改,我们用 size unit 替换了S/M/L尺寸,允许客户扩展 1-200 个节点。每个节点可以处理多达10,000 个连接和/或 10,000 个req/sec。扩展 1-200 个节点需要几分钟,但却可以让你的连接从 10,000个扩展到 200万个。每个节点也起到一种冗余的作用,因此添加更多节点可以增加您的负载均衡器的可用性。下面是一个示例,展示了使用这种新架构在生产环境中运行的负载均衡器,其连接峰值接近一百万,服务于真实的客户流量。
我们的目标是在架构升级以实现更大规模的同时,确保产品体验的一致性。这使得我们能够自动将客户的负载均衡器过渡到新架构,而无需任何停机时间或客户端的繁琐迁移。随着客户扩展其负载均衡器,我们提供了可预测的定价,并允许客户通过选择节点数量来选择冗余级别。
自负载均衡器产品首次发布以来,其产品架构已经历了多年的发展。它已从支持1万个连接和1万个每秒请求(RPS)扩展到支持200万个连接和高达200万个每秒请求(RPS)。我们仍在继续开发新功能和进行性能改进,以满足用户部署对高性能和高可用性的要求。
我们期待客户试用改进后的负载均衡器产品,也欢迎更多中国出海企业尝试全球负载均衡服务(DigitalOcean GLB)。如果你希望了解产品,可联系我们。
相关产品与选型


