
基于语音的AI应用,我们已经见过很多了,我们最喜爱的应用场景之一就是利用AI做出逼真的虚拟角色,包括他们的样子和说话方式。你甚至可以与这些虚拟角色进行实时语音对话。
进行这些对话的最佳平台是 character.ai——目前已经是个2000万用户的平台。通过这个平台,你可以轻松地与你最喜爱的任何角色、历史人物等在片刻之间开始聊天。它不仅拥有现成的大型角色库供你选择,而且网站还能让你0门槛创建自己的角色AI。此外,他们甚至还有一个快速对话功能,可以实现与这些的角色进行实时语音对话,就像与AI Agent语音聊天一样。
但是,如果我们想更进一步呢?我们已经从这些模型中获得了定制的音频回复,那么下一步就是添加视频!现在,借助 LTX-2 的强大能力,这已经成为可能。
在本教程中,我们将展示如何使用 LTX-2 与一个由 AI 驱动的角色创建交互式对话视频。这个流程从在 character.ai 上生成文本/音频开始,然后展示如何使用 Qwen3-TTS 从源媒体或文本描述创建角色的语音,最后使用 LTX-2 为角色的静态图像添加动画,使其与生成的语音同步说话。请跟随我们,我们将提供完整的流程演练和演示,并对使用的技术进行简要介绍。
开发流程
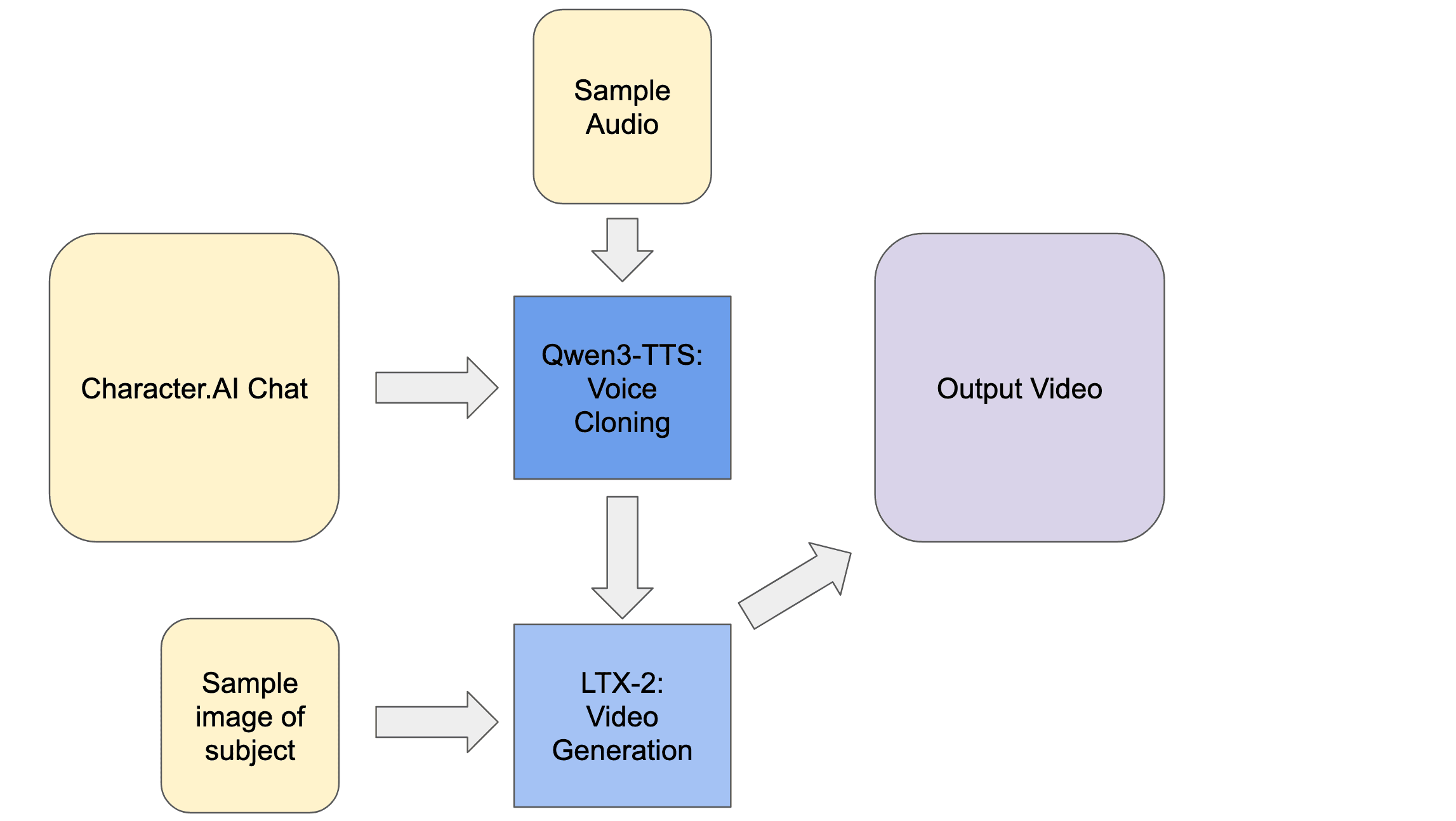
上图展示了创建视频的流程。首先,我们将使用 Character AI 生成输入内容,并从互联网获取其他资源。然后将这些内容输入到 Qwen3-TTS,接着输入到 LTX-2 以生成最终输出。请跟随我们,深入了解每个组件。
character.ai
要开始使用,我们需要在 character.ai 上与一个我们选择的角色聊天。这些由 LLM 驱动的角色是互联网上基于 GPT 的最佳对话代理之一!选择一个能引起你共鸣的角色,并且其语音要能从互联网获取到。选定了角色后,向模型输入你的请求。这将得到一个符合该角色语气和“知识”的回复。然后,我们可以将其作为下一流程环节——Qwen3-TTS CustomVoice 的输入。
Qwen3-TTS CustomVoice
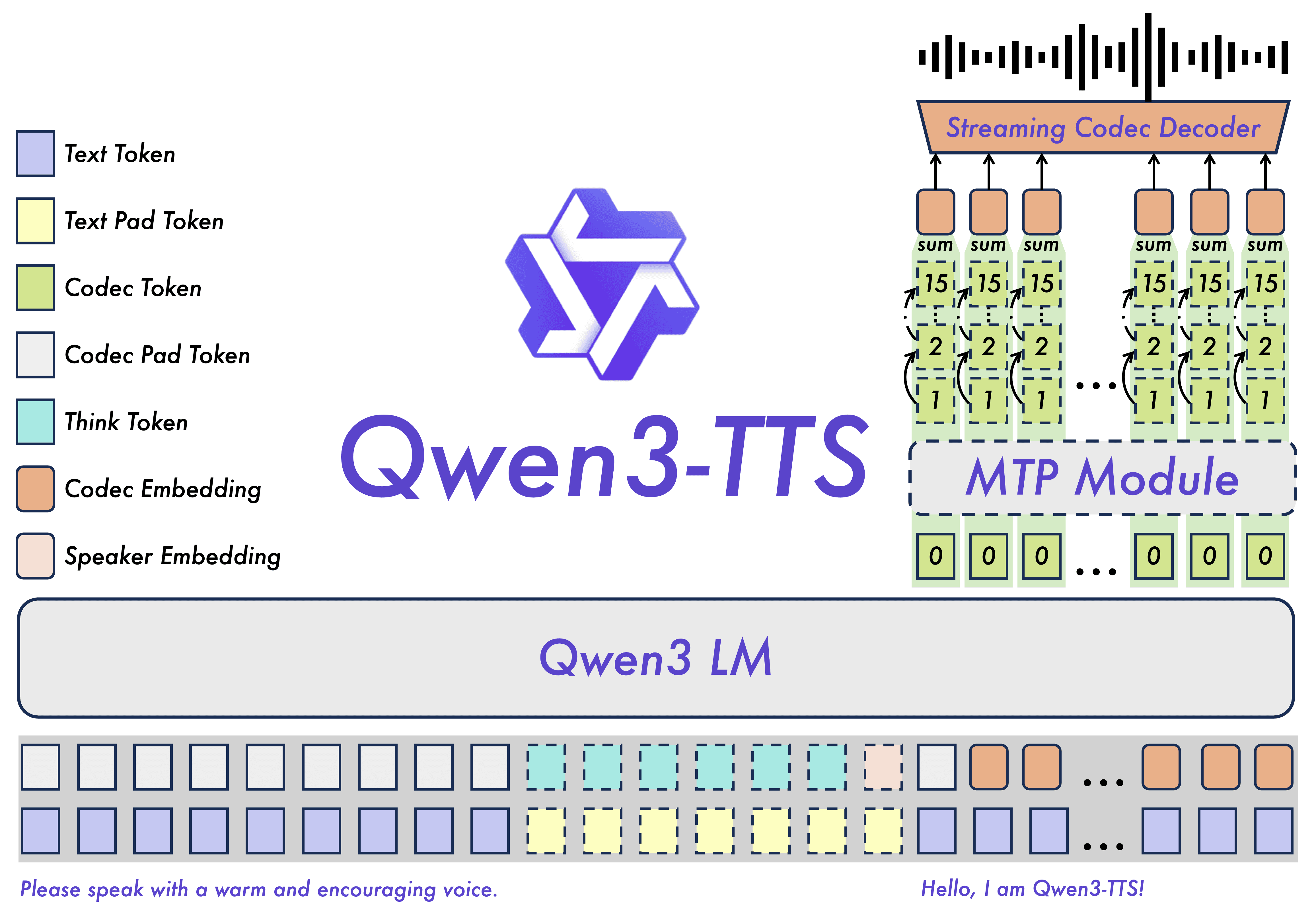 Qwen3-TTS 是一个支持十种主要语言和多种方言语音配置的多语言、低延迟文本转语音系统,专为具有强大上下文理解能力的全球实时应用而设计,能够从嘈杂的输入文本中动态控制语调、语速、韵律和情感表达。它基于 Qwen3-TTS-Tokenizer-12Hz 和通用的端到端离散多码本架构,保留了丰富的副语言学和声学细节,同时避免了传统语言模型+扩散变换器流程的瓶颈和级联错误,提供高效、高保真的语音生成。其双轨混合流设计允许单个模型同时处理流式和非流式合成,在单个字符后即可输出音频,实现端到端延迟低至 97 毫秒,同时自然语言驱动的语音控制确保输出逼真、与意图一致的语音。
Qwen3-TTS 是一个支持十种主要语言和多种方言语音配置的多语言、低延迟文本转语音系统,专为具有强大上下文理解能力的全球实时应用而设计,能够从嘈杂的输入文本中动态控制语调、语速、韵律和情感表达。它基于 Qwen3-TTS-Tokenizer-12Hz 和通用的端到端离散多码本架构,保留了丰富的副语言学和声学细节,同时避免了传统语言模型+扩散变换器流程的瓶颈和级联错误,提供高效、高保真的语音生成。其双轨混合流设计允许单个模型同时处理流式和非流式合成,在单个字符后即可输出音频,实现端到端延迟低至 97 毫秒,同时自然语言驱动的语音控制确保输出逼真、与意图一致的语音。
我们使用 Qwen3-TTS 来克隆我们创建的角色的声音。这就是 YouTube 和其他资源发挥作用的地方。可以在youtube搜索这个角色可以使用的声音,准备好一段清晰录音,以供下一步使用。
LTX-2
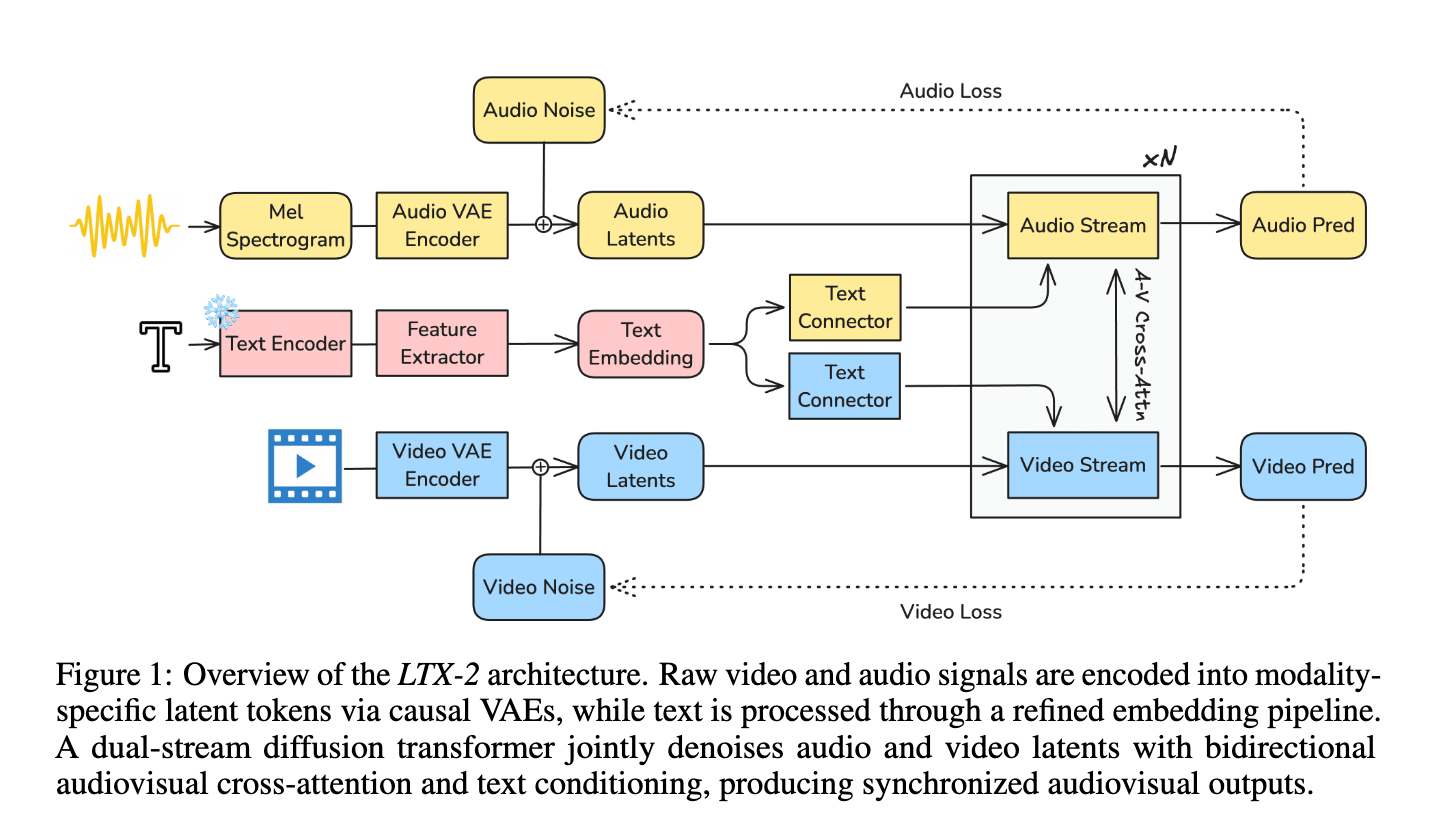
我们使用 LTX-2 作为这个流程的核心驱动。它的工作是为我们的角色静态图像添加动画,并将视觉效果与音频流匹配。最近的文本转视频的AI模型,如 Wan2.2 和 Hunyuan 1.5 都非常不错,但在这方面有所欠缺。我们指的是它们能够产生视觉上引人入胜的画面,但缺少同步的音频,省略了声音所提供的语义、情感和氛围。
为了填补这一空白,Lightricks 创建了一个新的旗舰基础模型:LTX-2。这是一个开源的基础模型,在单一的统一个框架内生成高质量的视听内容。LTX-2 围绕一个非对称的双流变换器架构构建。它由一个 140 亿参数的视频流和一个 50 亿参数的音频流组成,通过双向音频-视频交叉注意力层(cross-attention)相互连接。该交叉注意力层引入了时间位置嵌入以及用于共享时间步条件的跨模态 AdaLN。这种设计在保证高效联合训练与推理的同时,有意将更多模型容量分配给视频生成而非音频。
此外,系统采用了多语言文本编码器,以提升对不同语言提示词的理解能力,并引入了一种模态感知的无分类器引导机制(modality-aware classifier-free guidance,modality-CFG),用于增强音视频之间的对齐性与整体可控性。
除了语音合成,LTX-2 还能生成丰富、连贯的音轨,这些音轨反映了屏幕上的角色、环境背景、风格意图和情感基调,包括自然的背景环境和拟音效果。经验上,LTX-2 在开源模型中实现了最先进的视听质量和提示遵循度,提供了与专有系统相当的性能,同时所需的计算量和推理时间显著减少,所有模型权重和代码均已完全向公众发布。
Demo演示
现在我们已经概述了整体流程,可以开始进行演示了。首先,请按照 Kv中的说明完成环境准备。该教程详细说明了运行本次演示所需的全部配置步骤。
第一步,创建一台算力充足的 GPU Droplet,理想情况下选择 NVIDIA H200。随后,通过 SSH 从本地机器连接到这台 GPU Droplet,并使用终端以及 VS Code / Cursor 的 Simple Browser 功能进行访问。
当你的实例启动并可以正常使用后,继续阅读下一节。
为 LTX-2 设置 ComfyUI
将以下代码片段复制并粘贴到你的终端窗口中。请确保你首先在你选择的目录中!
git clone https://github.com/Comfy-Org/ComfyUI
cd ComfyUI
python3 -m venv venv_comfy
source venv_comfy/bin/activate
pip install -r requirements.txt
cd models/diffusion_models/
wget https://huggingface.co/Lightricks/LTX-2/resolve/main/ltx-2-19b-dev.safetensors
cd ../loras/
wget https://huggingface.co/Lightricks/LTX-2/resolve/main/ltx-2-19b-distilled-lora-384.safetensors
cd ../vae
wget https://huggingface.co/Kijai/LTXV2_comfy/resolve/main/VAE/LTX2_video_vae_bf16.safetensors
wget https://huggingface.co/Kijai/LTXV2_comfy/resolve/main/VAE/LTX2_audio_vae_bf16.safetensors
cd ../text_encoders/
wget https://huggingface.co/Kijai/LTXV2_comfy/resolve/main/text_encoders/ltx-2-19b-embeddings_connector_dev_bf16.safetensors
wget https://huggingface.co/DreamFast/gemma-3-12b-it-heretic/resolve/main/comfyui/gemma_3_12B_it_heretic.safetensors
cd ../checkpoints
wget https://huggingface.co/Kijai/MelBandRoFormer_comfy/resolve/main/MelBandRoformer_fp32.safetensors
cd ../..
python main.py
这个过程需要几分钟,完成后,你将得到 ComfyUI 的输出 URL。复制它,并粘贴到通过 SSH 连接到该机器的 VS Code/Cursor 的简易浏览器中。然后,点击简易浏览器右上角的箭头,在你本地机器的默认浏览器中打开 ComfyUI。最后,获取这个 JSON 文件模板,将其上传到 ComfyUI 以开始使用该模板。它看起来应该类似于这样:
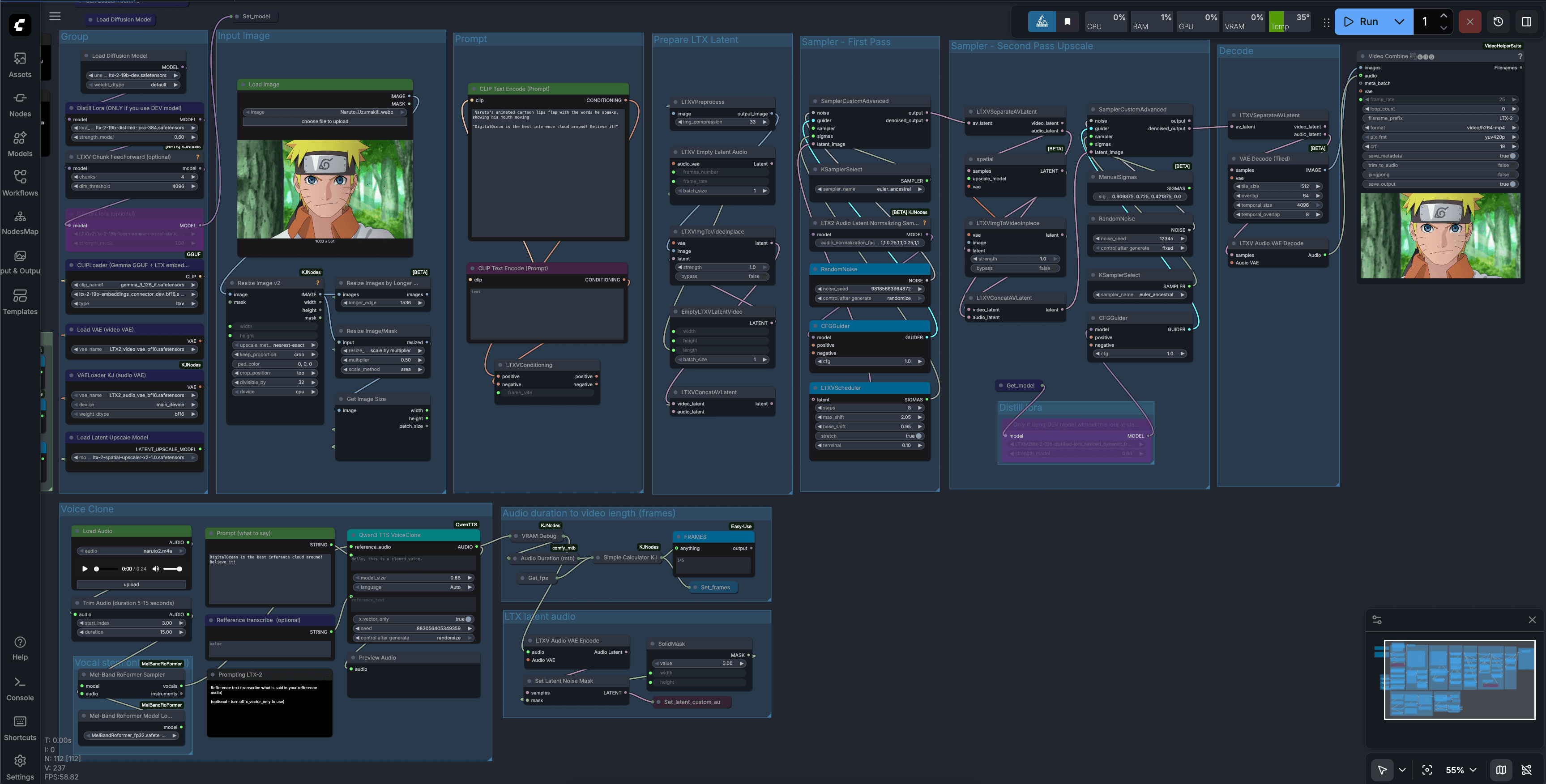
这个例子使用了一个流行的动漫角色,但你可以将其替换为你喜欢的任何角色。将你之前为克隆准备的声音样本、由 Character AI 生成的对你的问题的回复、你想用作视频基础样本的角色图像,用这些值填充模板。然后,点击运行来生成视频。
现在,你可以根据需要修改这个工作流程!这个流程非常灵活,能够处理各种声音,并为不同媒介(如动漫、卡通、艺术作品等)中的各种主题添加动画。这有多种用途,比如为采访创建可视化效果、为场景中的角色制作动画演讲等等!
结语
通过将 character.ai 富有表现力的实时对话、Qwen3-TTS 语音合成和 LTX-2 统一的视听生成功能结合起来,这个流程展示了角色对话如何能够快速从屏幕上的文本演变为完全动画化的、会说话的角色形象。过去需要复杂、定制的动画和音频工作流才能完成的事情,现在一个开发者凭借开源工具和一块 GPU 就能完成原型设计,为故事讲述、教育、娱乐和互动媒体开启了新的可能性。随着像 LTX-2 这样的视听基础模型不断成熟,与角色聊天和观看他们在屏幕上活灵活现之间的界限只会变得越来越模糊。


