自从 DeepSeek 问世以来,大语言模型甚至 AI Agent 领域更卷了。每个月我们都能看到新版本的大语言模型,还有新的 AI 工具。当然,能为 AI 业务提供助力的 GPU 服务器也是如此。在去年,各大 AI 企业讨论和使用更多的是 NVIDIA H100 ,而近期,NVIDIA H200 与 AMD Instinct MI300X 这样的新一代 GPU 也已开始成为企业们的可选对象。
要知道,原版 DeepSeek R1 671B 版本大小高达 720GB,非常庞大,就连NVIDIA DGX H100(8xH100)这样价值 20 万美元的庞然大物都装不下。然而,由于AMD Instinct MI300X 有 192GB VRAM ,让我们只需使用一台 MI300X 即可部署它。
由于这三款GPU在架构、性能和成本上各有优势,但实际应用中如何根据不同场景(例如大模型训练和AI推理)来选择最合适的产品,是每位企业技术负责人必须思考的问题。所以我们将通过本文对产品规格、训练与推理表现等方面的数据进行比较,帮助大家全面了解 NVIDIA H200、H100 与 AMD Instinct MI300X 三款 GPU 的特点,为服务器选型提供决策依据。本文中引用的数据均来源于公开报道和权威测试报告。
Tips:目前,DigitalOcean 的 GPU 裸金属云服务器已经支持的GPU型号包括 NVIDIA H200、 NVIDIA H100 和 AMD Instinct MI300X。如需要咨询价格,请联系我们 。
产品规格对比
先给大家一个直观的数据表,对比一下基本的规格,我们把详细的分析放在后面。
| 指标 | H100 | H200 | MI300X |
|---|---|---|---|
| 单 GPU 功耗( TDP ) | 700W | 700W | 750W |
| 系统总功耗(每块 GPU ) | 1275W | 1275W | 1275W |
| 显存 容量( GB ) | 80GB | 141GB | 192GB |
| 显存 带宽( GB /s) | 3352 GB/s | 4800 GB/s | 5300 GB/s |
| FP16 / BF16 算力 ( TFLOPS ) | 989 | 989 | 1307 |
| FP8 / FP6 / Int8 算力 ( TFLOPS ) | 1979 | 1979 | 2615 |
注:所有FLOPS为密集计算性能(dense FLOPS)。
AI大模型训练各GPU的表现如何?
NVIDIA H100/H200在训练任务中的优势
在大模型训练任务中,NVIDIA 的H100和H200凭借成熟的CUDA生态、丰富的软件库以及稳定的驱动支持,使得其在实际训练过程中的表现更为稳定。据SemiAnalysis的基准测试显示,在单节点训练场景中,H100/H200的矩阵乘法(GEMM)吞吐量和整体训练效率均优于MI300X,且在经过开箱即用测试时,NVIDIA 平台基本不存在软件漏洞。此外,H200作为H100的升级版本,在内存带宽和容量方面的提升使得它在大批量数据输入时能够保持较高的计算效率,对于大语言模型训练尤为重要。
AMD MI300X在训练场景中的现状
虽然AMD MI300X在理论上具备更高的内存带宽和容量,能够支撑更大规模的模型,但目前在实际训练测试中,其表现受限于软件优化不足。测试结果显示,在实际使用公开稳定版本软件时,MI300X的训练吞吐量仅达到H100的约85%甚至更低。有分析指出,这主要与AMD软件栈中存在的诸多bug和环境调优复杂性有关。尽管在部分经过定制优化的开发构建版本中,MI300X的性能有一定提升,但这需要额外的工程资源进行调优。为了在 MI300X 上提供最佳的开箱即用体验,SGLang(一个高性能的开源 LLM 和 VLM 服务框架)发布了预构建的 docker 镜像和 docker 文件。这些资源可用于生产部署,并可作为根据用例特定要求定制自定义镜像的起点。
训练工作负载的适用场景建议
对于需要高效稳定训练大模型的企业而言,目前NVIDIA 的H100/H200凭借其成熟生态和易用性,仍是较优选择。而对于预算较为紧张、对TCO要求较高的场景,且具有较强自主调优能力的企业,则可以关注AMD MI300X的发展,等待其软件生态进一步完善后再逐步部署。总体来看,在大规模训练任务中,稳定性和易用性往往优先于理论规格,NVIDIA 平台目前更符合企业级生产需求。
AI 推理与文生图场景的GPU表现
低精度推理算力
MI300X 在 FP8/INT8 精度下提供 2615 TFLOPS 的算力,明显高于 H100/H200 的 1979 TFLOPS,意味着在部署量化后的 LLM(如 GPTQ/LLM.int8)时,MI300X 推理吞吐量更高,适合 Token Streaming、RAG、Agent 类实时服务。
内存带宽优势在文生图中的体现
在文生图任务(如 Stable Diffusion XL、Sora 等)中,显存带宽直接影响 latent 编码、解码时的性能。MI300X 提供 5300 GB/s 的带宽,能够支持更快的模型参数访问,缩短推理延迟。
根据 Stability AI 提供的社区 benchmark,使用 SDXL 推理时,MI300X 单卡平均生成延迟比 H100 低 12%-18%。
多模态模型推理优势
大模型的发展正快速走向多模态方向(文+图、文+音),这类模型体积大,对显存和带宽要求更高。MI300X 的 192GB 显存可容纳如 Flamingo、MM1 等巨型模型单卡部署,减少跨卡通信。
DeepSeek-R1 优化成果案例
尽管 ROCm (AMD推出的一个开源高性能计算软件平台)在整体生态上仍略逊于 CUDA,但一些新兴框架如 SGLang (一个高性能的开源 LLM 和 VLM 服务框架,AMD 也是其贡献者)已开始填补这部分空白。SGLang 在 MI300X 上进行了深度优化,具备以下特点:
- 原生支持 ROCm,无需依赖 CUDA;
- 实现 FlashAttention-2 与高效调度,优化推理性能;
- 在 DeepSeek-R1 模型上实现最高 4 倍性能提升;
- 支持长文本、多轮对话的流式推理需求。
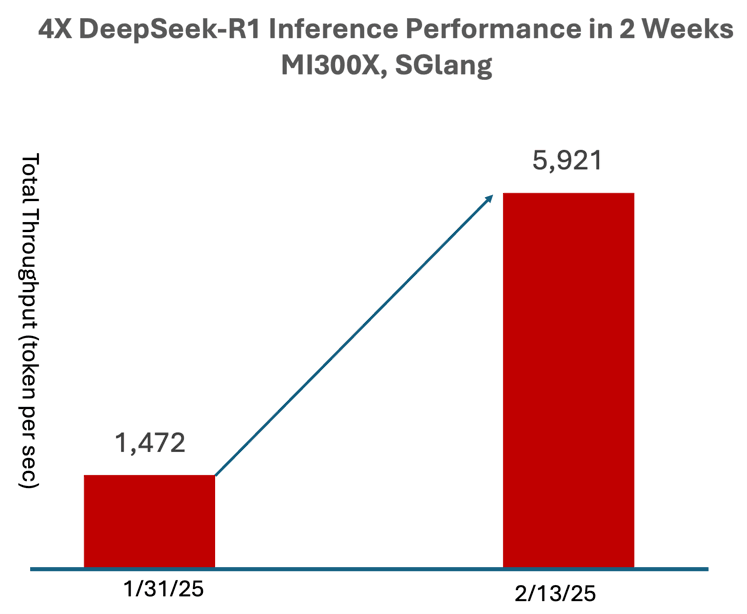
对于希望在 AMD 平台上部署私有 LLM 服务的企业来说,SGLang 是值得关注的新兴生态工具。实际上,AMD博客就表示,他们在短短两周内,使用 671B DeepSeek-R1 FP8 模型(而不是较小的提炼版本)实现了高达 4 倍的推理性能提升,并将其优化也都上传到了 SGLang。
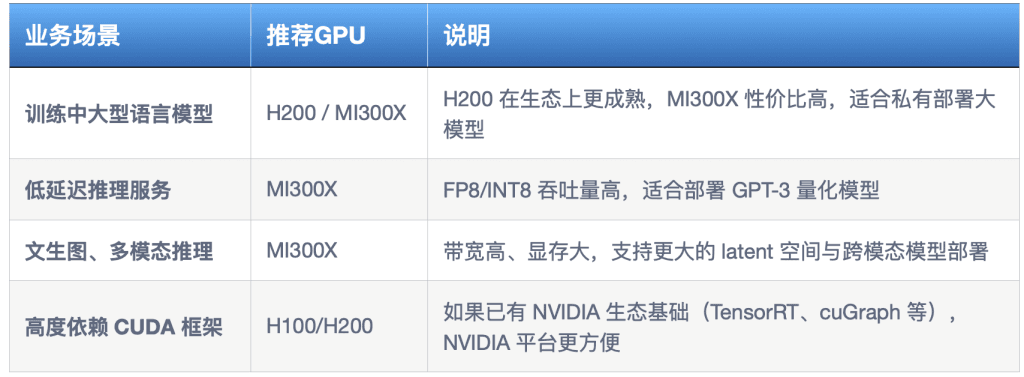
以下是为不同业务场景推荐 GPU 的总结建议:
✅ MI300X 的相对关键优势在于:
- 显存 最大:192GB 显存可单卡支持 LLaMA2-70B、文图多模态大模型。
- 带宽最高:5.3 TB/s HBM3e,显著优于 H100/H200,推理延迟更低。
- 推理 算力 强:2615 TFLOPS(FP8),部署压缩模型效果优异。
- 功耗相同:与 H100/H200 系统总功耗一致,具备良好 PPA(性能/功耗比)。
- 实际案例验证:DeepSeek-R1 在 MI300X 上实现 4 倍推理性能提升,支持复杂任务单节点部署。
- 新生态工具支持:SGLang 框架原生兼容 ROCm,优化推理性能,助力企业快速部署 LLM。
- 硬件成本更低: 相对于H200、H100,AMD MI300X的硬件成本更低。
要注意:
- ROCm 生态尚未与 CUDA 等量齐观,需评估框架兼容性。
- 驱动、监控工具、分布式支持仍在持续完善中。
总结
面对 AI 模型规模日益扩张,GPU 服务器选型已经成为决定业务效率的关键环节。NVIDIA H100/H200 凭借成熟生态依然是主流之选,而 AMD MI300X 则以超强硬件规格在推理和大模型场景中展现出巨大潜力。企业在采购时,应根据自身业务需求、部署环境和成本预算,做出有前瞻性的技术判断。
对于大多数AI企业技术负责人来说,如果追求整体稳定性、成熟生态以及较低的开发风险,NVIDIA 的H100和H200依然是较优选择;而如果预算有限、对TCO要求严格且具备较强自主优化能力,则可以关注AMD MI300X的发展动态,待其软件生态进一步成熟后再考虑逐步引入。
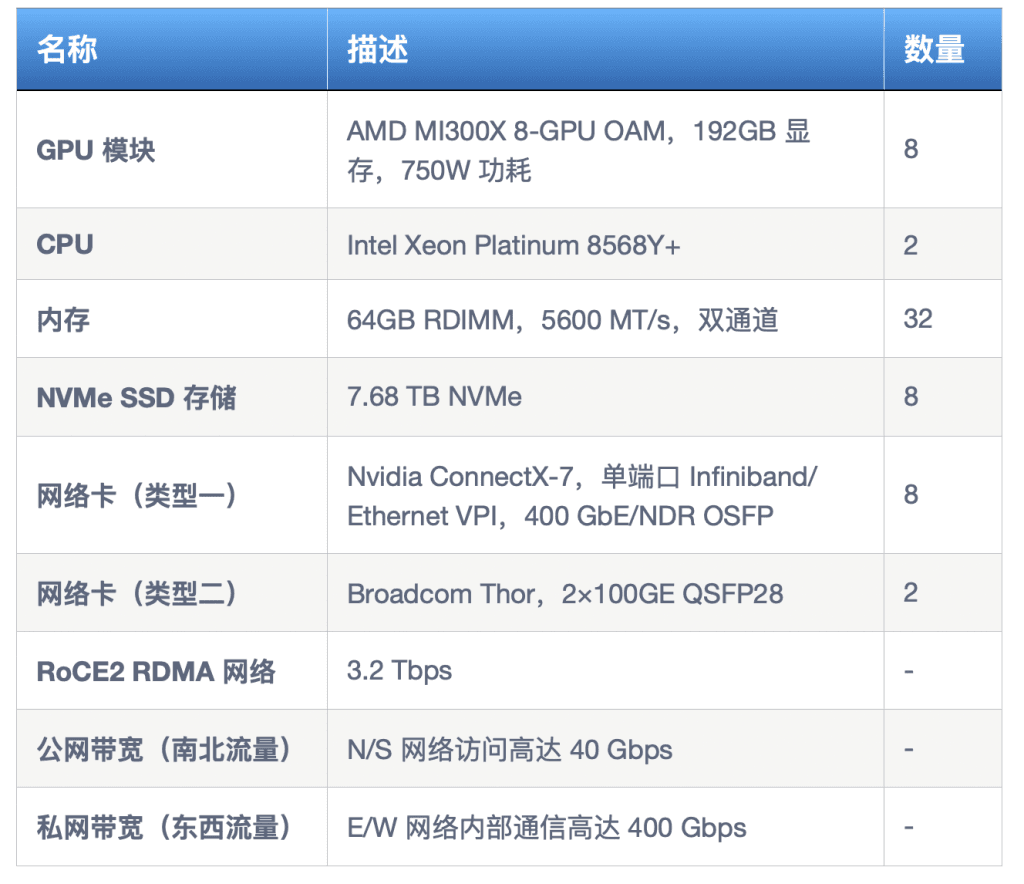
目前,DigitalOcean 的 GPU 裸金属云服务器已经支持的GPU型号包括 NVIDIA H200、 NVIDIA H100和 AMD MI300X, 其中,MI300X 裸金属云服务器的配置如上图。如需要咨询价格,请联系我们。


