
近日,“杭州深度求索”推出了其最新的大型语言模型DeepSeek V3,这是一款强大的专家混合(Mixture-of-Experts, MoE)架构语言模型,总参数量达到671B,每个token激活的参数量为37B。经过综合测试它的性能已经比肩GPT-4o、Claude。这个消息在AI圈像一个新年烟花一样炸开。
本文将来看看这个新的模型的特性,以及与其它模型的指标对比。然后在最后,我们在 H800 GPU上运行 DeepSeek v3,让我们来体验一下。
什么是 DeepSeek v3?
DeepSeek v3 是一个强大的自然语言生成模型,专为生成高质量内容(如代码、文档或回答问题)而设计。其模型参数经过优化,可以利用 NVIDIA H100 GPU 实现极高的推理性能。为了实现高效的推理和成本效益高的训练,DeepSeek V3采用了多头潜在注意力(Multi-head Latent Attention, MLA)和DeepSeekMoE架构,这些技术已经在前代产品DeepSeek V2中得到了充分验证。
同时,DeepSeek V3在负载均衡方面开创性地引入了无需辅助损失的策略,并设定了多token预测的训练目标以提升性能表现。该模型在14.8万亿个多样且高质量的token上进行了预训练,随后通过监督微调(Supervised Fine-Tuning)和强化学习阶段进一步挖掘其潜力,确保模型能够更好地服务于各种应用场景。
官方模型托管在 Hugging Face 平台: DeepSeek v3 模型仓库
DeepSeek v3横向对比
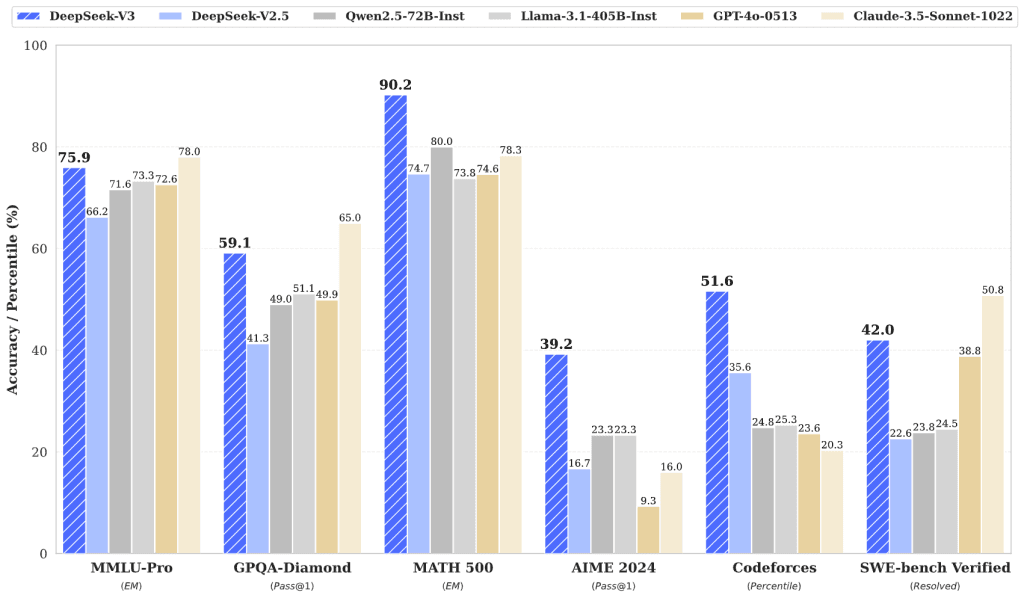
根据官方的介绍,训练成本为 557.6万美元,远低于 GPT-4o 、Claude等闭源模型的 1亿美元。该模型在多项评测中超越对手,例如如 Qwen 和 Llama 等顶尖开源模型。不仅如此,相较于GPT-4o、Claude等闭源模型,DeepSeek的成本和开源特性让开发者们更容易接触并使用。
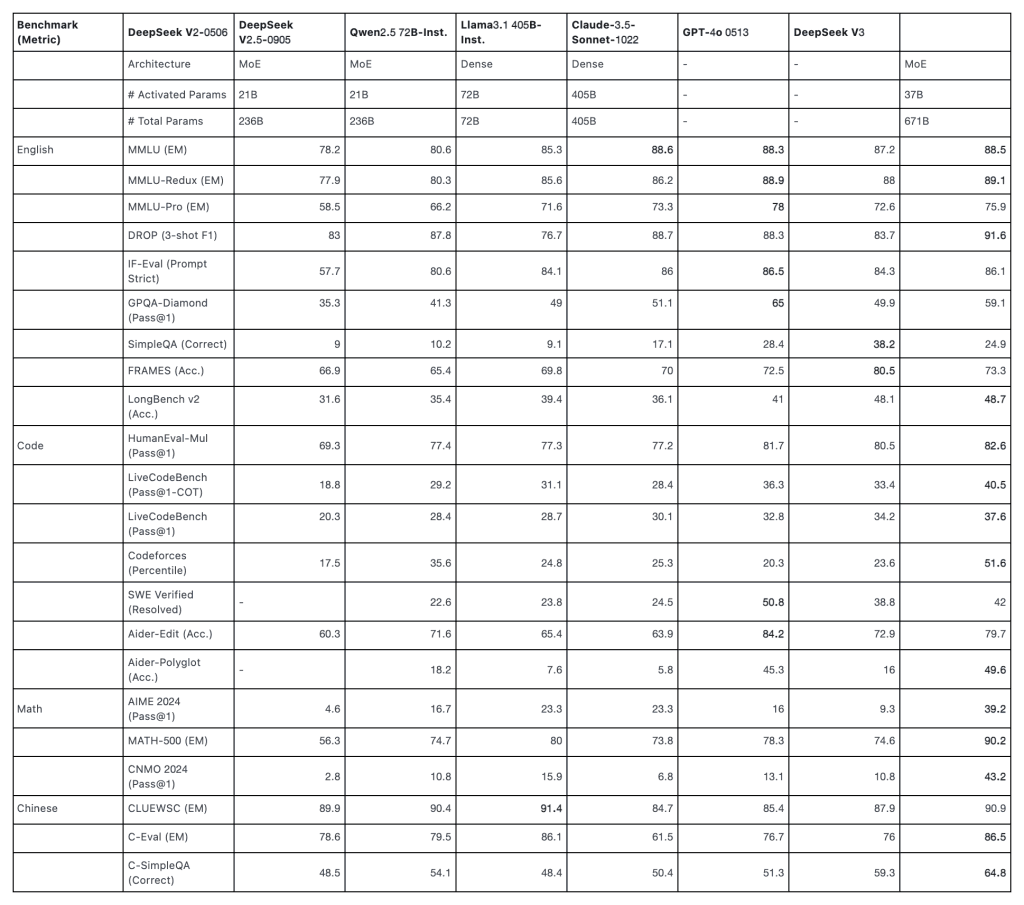
综合评估结果显示,DeepSeek V3的表现超越了其他开源模型,并达到了与领先闭源模型相媲美的水平。值得注意的是,尽管DeepSeek V3拥有出色的性能,但其整个训练过程仅需2.788M H800 GPU小时(如果使用单个H800 GPU来训练DeepSeek V3,那么完成整个训练过程将需要2,788,000小时)。此外,DeepSeek V3的训练过程异常稳定,在整个过程中没有出现任何不可恢复的损失峰值或需要回滚的情况。
运行 DeepSeek v3 的前提条件
部署前,请确保您具备以下条件:
-
基本 Python 编程经验,以及对 Hugging Face 的
transformers库的了解。 -
支持的硬件和环境:
-
GPU:NVIDIA H100 或 H100x8。
-
操作系统:Ubuntu 20.04 或更高版本。
-
环境需求:
- Python 3.8 或更高版本。
- Hugging Face Transformers 和 PyTorch。
-
-
合适的GPU与设备。在本文中,为了低成本快速体验该模型,我们选择DigitalOcean 的GPU Droplet服务器。
DigitalOcean GPU Droplet 配置概览
DigitalOcean 提供两种 GPU Droplet 配置,基于 NVIDIA H100 GPU:
-
单 GPU 配置(H100)
- GPU 数量:1× NVIDIA H100
- 显存:80 GB VRAM
- vCPU:20
- RAM:240 GB
- 存储:2 TB NVMe(引导盘)
-
多 GPU 配置(H100x8)
- GPU 数量:8× NVIDIA H100
- 显存:640 GB VRAM
- vCPU:160
- RAM:1920 GB
- 存储:2 TB NVMe(引导盘) + 40 TB NVMe(高速缓存盘)
在 DigitalOcean 上创建GPU Droplet
步骤 1:登录到 DigitalOcean 控制台
进入 DigitalOcean 控制台,并点击 Create Droplet。
步骤 2:配置 Droplet
- 操作系统:选择 Ubuntu 20.04 ( LTS ) 。
- GPU 类型:选择 NVIDIA H100(单 GPU)或 NVIDIA H100x8(多 GPU)。(目前按需价格仅需2.55美元/小时/GPU,详情可咨询DIgitalOcean中国区独家战略合作伙伴卓普云)
- 区域选择:选择支持 GPU 的数据中心区域(如纽约或法兰克福)。
- 尽管DigitalOcean支持一键部署Huggingface上的模型,但是由于撰写本文的时候DeepSeek -V3才上线没多久,所以暂时在后台还不支持一键部署。后面我们会讲怎么部署。
步骤 3:设置身份验证
- 推荐使用 SSH Key 登录 Droplet,确保安全性和便捷性。
步骤 4:启动 Droplet
点击 Create Droplet,等待系统启动。完成后,记录 Droplet 的公共 IP 地址。
配置 Droplet 环境
使用 SSH 登录 Droplet:
ssh root@<Droplet_IP>
更新系统软件包:
sudo apt update && sudo apt upgrade -y
安装基础工具:
sudo apt install -y build-essential wget curl git
检查 GPU 驱动是否安装: DigitalOcean 的 GPU Droplets 预装了 NVIDIA 驱动和 CUDA 工具,但建议确认:
nvidia-smi
安装必要的软件和库
安装 Python 和 pip:
sudo apt install -y python3 python3-pip
创建 虚拟环境 (推荐) :
pip3 install virtualenv
virtualenv deepseek_env
source deepseek_env/bin/activate
安装 PyTorch 和 Hugging Face Transformers:
- 使用 PyTorch 官方提供的 CUDA 版本安装:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
- 安装 Hugging Face Transformers:
pip install transformers
安装其他依赖库:
pip install numpy pandas
加载并运行 DeepSeek v3
在 Droplet 中创建一个测试文件(如 deepseek_v3_test.py),DeepSeek V3 已在 Hugging Face 上开源,开发者可以通过以下步骤快速集成和使用:
from transformers import AutoModelForCausalLM, AutoTokenizer
### 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-V3")
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3")
# 输入文本
input_text = "生成一段Python代码,实现一个简单的计算器。"
# 生成代码
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
# 输出结果
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
测试 DeepSeek v3
自定义生成任务: 修改代码中的 input_text 为您希望生成的内容,例如:
- 文本生成:
"写一篇关于人工智能的短文。" - 代码生成:
"生成一个实现二叉树遍历的Python代码示例。"
结语
通过本教程,您已成功利用 DigitalOcean 的 GPU Droplets 部署并运行了 DeepSeek v3。在 NVIDIA H100 或 H100x8 的强大计算能力支持下,DeepSeek v3 可以高效完成自然语言生成任务。
附加资源
如果在使用中遇到问题,请随时参考以上资源或联系技术支持进行排查。如果你的团队需要H100 GPU请联系我们。
相关产品与选型


