
DeepSeek官方近期公布的推理服务数据,为我们揭示了其在硬件选型、资源调度和盈利模式方面的诸多关键信息,其盈利能力更是让人关注。同时,这背后也引发人们的思考,如果自己的公司同样部署了DeepSeek模型,那么是否也能复刻同样或相近的利润率呢?
成本控制与盈利模式的核心要素
根据DeepSeek公布的数据,其模型推理服务日均成本为8.7万美元,理论收入56.2万美元,成本利润率高达545%。这一数字背后隐藏着三个核心逻辑:
第一,混合精度计算的效率革命 通过将矩阵计算(FP8)与注意力机制(BF16)分离,DeepSeek在保证效果的同时降低算力消耗。FP8相比传统FP16减少50%显存占用,而BF16保留核心计算精度,这一组合使得单GPU吞吐量提升30%以上。
第二,动态资源调度的“时间 套利 ” 白天集中资源服务高峰流量,夜间释放算力用于训练,资源利用率从静态100%提升至动态90%+。按峰值278节点、均值226.75节点计算,闲置资源再利用率达18.4%,相当于日均节省51节点(约合7.8万美元)。
第三,KVCache缓存的价值链重构 56.3%的输入token命中缓存,意味着近半数请求跳过了耗时的预处理环节。以H800单卡14.8k tokens/s的解码速度计算,缓存机制每天节省1.2万GPU小时,相当于降低18%的边际成本。
上述分析揭示了DeepSeek成本控制的技术本质。但同行业的AI创业者门可能更关心的是:现在部署DeepSeek模型的AI企业还有希望么?这套方法论能否复制?如果选择第三方云服务商, 成本结构 会发生什么变化?
市场窗口期——为什么“现在不上车就是放弃红利”?
当前DeepSeek公布的545%成本利润率,本质上是技术红利、资源调度红利和市场早期红利的叠加。但这一窗口期正在快速关闭:
- 技术红利 衰减:混合精度优化、KVCache缓存等方案已被头部企业广泛采用,后发者难以形成差异化优势。
- 硬件资源紧张:随着H200等高性能GPU需求激增,云服务商的GPU服务器资源可能会被提前入场的企业抢占,晚进场的企业会需要比现在更长的时间等待空余或新增的资源。
- 市场饱和风险:若未来12个月主流AI模型均采用类似架构,单位token收入可能下降50%-70%(参考ChatGPT API价格变化曲线)。
“等等党”的代价——以代码生成赛道为例
对于那些选择“等等”的企业而言,晚入场一年所付出的代价是沉重的。以代码生成赛道为例来说明:
- 2025年Q2入场:按照DeepSeek当前模型,单用户日均成本为0.12美元,客单价为0.8美元,利润率高达567%。在这个窗口期,企业可以轻松实现高利润。
- 2026年Q2入场:由于竞争加剧,企业不得不采用更大规模的模型(例如将上下文长度从4k提升至8k),硬件成本上升到0.21美元/用户,同时客单价可能被压至0.5美元。结果,利润率骤降,仅为138%。
这意味着,如果企业晚入场一年,就需要覆盖2.3倍以上的用户量,才能达到与早期入场相同的利润规模。所以,要想获得较高的利润率,第一前提就是尽早入场,先借助DeepSeek这只船起航。
其他AI创业企业应该怎样优化成本策略?
对于计划借助DeepSeek模型开展业务的AI创业企业而言,硬件选型和资源调度无疑是成功商业化的重要保障。企业在制定成本优化策略时应从以下几方面入手。
- 动态资源调度
- 弹性伸缩:根据实际流量需求,设置动态调度机制。像DeepSeek一样,在白天高峰时段全力部署推理服务,夜间负载较低时减少推理节点,将空闲资源转用于研究或训练任务,既保证服务质量又避免资源浪费。
- 按需计算:利用自动监控与调度系统,实时调整节点数量,确保在流量高峰时资源充足,在流量低谷时降低运行成本。
- 高效缓存策略
- 优化KVCache:DeepSeek报告中56.3%的输入token通过硬盘缓存命中,这显著降低了计算压力。其他企业可以进一步优化缓存设计和命中率,减少重复计算,从而降低GPU负载和成本。
- 智能预取与调度:通过算法预测用户请求,提前加载相关数据到缓存中,提高整体系统响应速度。
- 精度与硬件利用
- 统一精度设定:保持推理服务与训练时一致的精度(例如FP8与BF16),不仅能保证模型效果,也可以充分发挥硬件(如H100x8 GPU)的性能,避免因精度切换带来的额外开销。
- 硬件选择:选择性能和成本匹配的GPU,评估是否采用租赁或自建机房等不同模式,找到最佳性价比。如果你的业务侧重于灵活扩展、快速部署与成本透明,H100x8 服务器是一个不错的选择,而且要选择价格相对实惠的,比如DigitalOcean的H100x8服务器预留实例仅需2.5美元/小时(2025年年初价格);而如果你需要更高的计算密度、专属硬件资源以及极致性能,且预算和业务模型允许长期合约,那么选择H200裸机服务器可能会带来更好的性能优势和更高的性价比,比如DigitalOcean的H200裸机服务器。
- 定价与收入模型优化
- 灵活定价策略:根据市场需求和不同服务的价值设定不同的定价,避免过低定价导致收入不足,同时兼顾用户接受度。
- 分时段收费:考虑白天与夜间的不同负载和成本,推出分时段优惠或附加值服务,让客户在不同时间段都能体验服务,进而提高整体收入。
- 多任务协同与资源复用
- 多用途资源配置:在低负载时段,除了用于模型训练和研究,还可以考虑将部分资源用于内部测试、模型优化或新产品研发,最大化每块GPU的利用率。
- 异构工作负载管理:合理区分prefill任务和decode任务,根据各自的吞吐特性进行资源分配,确保每个任务都能在最合适的硬件上运行,提升整体效率。
最后,合理的价格谈判与长期合作策略同样不可忽视。大规模使用GPU资源的企业可以通过签订长期租赁合同或采用预付费模式获得价格优惠,同时根据市场动态灵活调整合同条款,以确保在技术更新换代时及时优化硬件结构。DigitalOcean云平台目前在美国、欧洲等数据中心都可提供基于H100或H200GPU的云服务器和裸机服务器,相关优惠可联系我们进行商洽。以上多重策略的协同作用,将有助于企业在使用DeepSeek模型时实现成本控制与盈利能力的双重提升。
H100 vs H200GPU平台硬件对比:数据一览
在当前AI算力需求日益增长的背景下,硬件选型成为企业面临的关键决策问题。除了DeepSeek目前使用的H100x8 GPU之外,用户也可考虑基于NVIDIA H200的服务器。
以下我们基于DigitalOcean云平台的两款机型,总结了核心硬件参数和价格,帮助读者直观了解各自的特性:
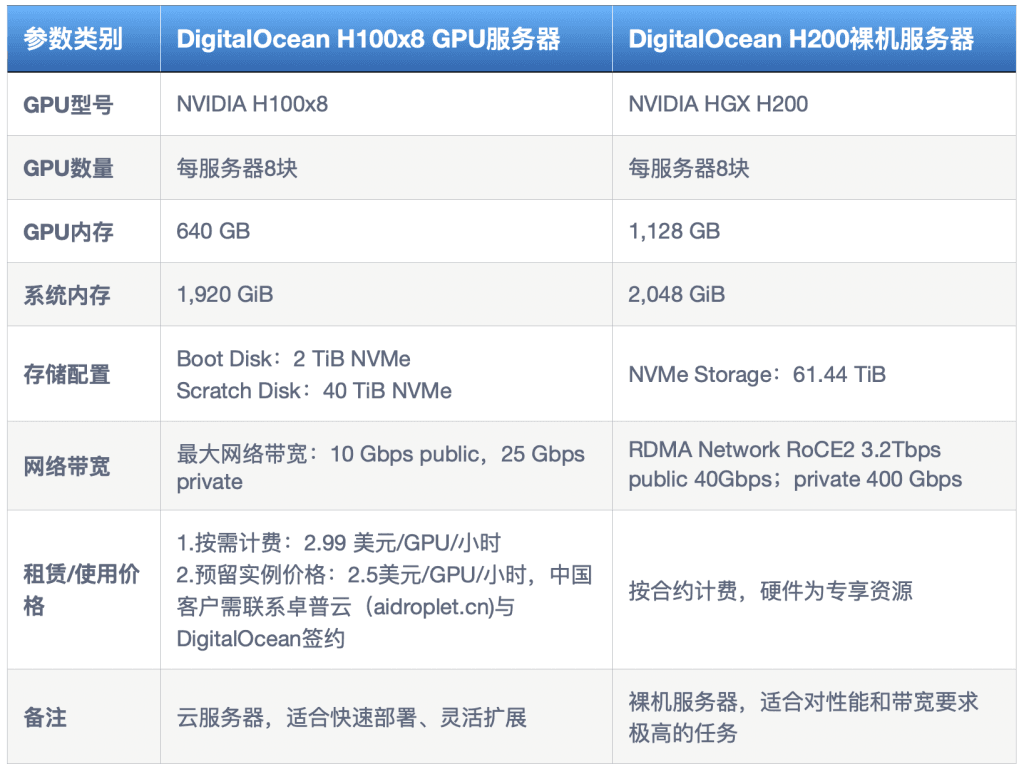
通过上述表格,我们可以清晰地看到,在GPU型号、内存、存储、网络和价格上的差异。H100x8服务器支持两种不同的计费方式,适合不同开发阶段和用量需求的企业;同时,H200裸机服务器则凭借高性能配置和专享硬件资源,尤其是极为强劲的网络带宽(RDMA Network RoCE2 3.2Tbps; public 40Gbps; private 400 Gbps),可能在单位算力成本上更具竞争力,特别适合对数据吞吐量和延迟要求极高的企业应用。
在此基础上,我们还应关注使用DigitalOcean的H200或H100服务器能给企业带来的独特优势。
首先,H200裸机服务器凭借更高的GPU内存(1,128 GB)和更大的系统内存,加上其超强的网络带宽能力——RDMA Network RoCE2 3.2Tbps、public 40Gbps和private 400 Gbps——能够大幅降低数据传输延迟并提升任务处理效率。这对那些需要实时响应和大规模数据处理的DeepSeek模型应用来说,意义重大。
其次,H100云服务器具备成熟的云端管理平台和灵活扩展能力,使得企业能够快速部署并根据业务需求动态调整资源,提升整体运营效率。此外,DigitalOcean平台提供的丰富监控和自动调度工具,也有助于企业在资源利用上更加精细,从而进一步降低系统运营风险。
综上所述,采用DigitalOcean的H200或H100服务器,不仅在硬件性能上为企业提供了更高的保障,同时也在网络传输、数据处理和系统扩展性等方面带来了显著优势,为采用DeepSeek模型的AI创业企业在竞争激烈的市场中争取先机创造了有利条件。
结论与未来展望
综上所述,DeepSeek公布的推理服务数据和盈利模型为我们展示了一个高度优化的AI服务示范。DeepSeek的高利润率故事揭示了一个深层真相:在AI算力成本战中,硬件选择只是冰山一角。真正的胜负手在于三个“不可见维度”:
- 算法-硬件协同设计:如FP8/BF16混合精度,可产生20%以上的边际成本优势
- 系统级创新:KVCache硬盘缓存的效率提升,相当于硬件迭代1.5代
- 动态资源编排:时空复用的收益远超单纯追求GPU利用率
对于AI创业者而言,与其纠结于H100还是H200,不如在以下方向构建护城河:
- 模型轻量化:通过蒸馏、量化将模型压缩30%-50%,直接减少算力需求
- 缓存算法优化:提升KVCache命中率至70%以上,复制DeepSeek的成本杠杆
- 弹性架构设计:实现秒级资源伸缩,将闲置成本转化为训练产能
最后,在算法、动态资源编排、轻量化模型的同时,作为AI创业者,还应该考虑进一步降低云基础设施的使用成本,与其选择隐藏成本高、计费规则复杂的传统云服务,不如考虑计费透明、价格实惠且服务稳定的云平台,比如DigitalOcean。毕竟,在AI的战场上,真正的成本杀手从来不是硬件参数表上的数字,而是架构师脑海中那些将技术与商业完美融合的奇思妙想。


