大型语言模型如今被用在各种我们能想到的场景里。从生成简单的指令回答,到推理复杂的数学题,再到给机器人提供逐步动作指引,它们正在推动一场我们亲眼可见的技术变革。
这些模型的能力似乎没有边界。那么接下来还能走到哪里?
一个可能的方向,是为模型加入更多模态,让它不仅能用文本输入输出,还能处理更多形式的数据。通过让模型在训练中同时接触文本、音频、图像,我们可以把它的能力扩展到更多领域。用大模型生成图像并不新鲜,比如 BAGEL 或后来的 HunyuanImage 3.0 都做过。但这些技术大多还没有被真正用在更复杂的应用里。
智源悟界 Emu3.5 的出现改变了这一点。
它引入了“视觉引导 + 叙事生成”管线。使用 Emu3.5,我们不仅能生成文字指令,还能在回答中同时生成一组图像,组成一段视觉叙事,为任务提供可视化的步骤与指导。
这篇文章将全面介绍智源悟界 Emu3.5 的工作方式、它如何生成图像和文本,以及如何实际使用它。接下来我们会一起在 DigitalOcean 的 GPU Droplet 云服务器上完整跑一遍 Emu3.5。
Emu3.5:视觉引导管线
Emu3.5 最大的创新在于它的设计思路。模型本质上是一个“能在视觉与语言之间原生预测下一状态的大规模多模态世界模型”。
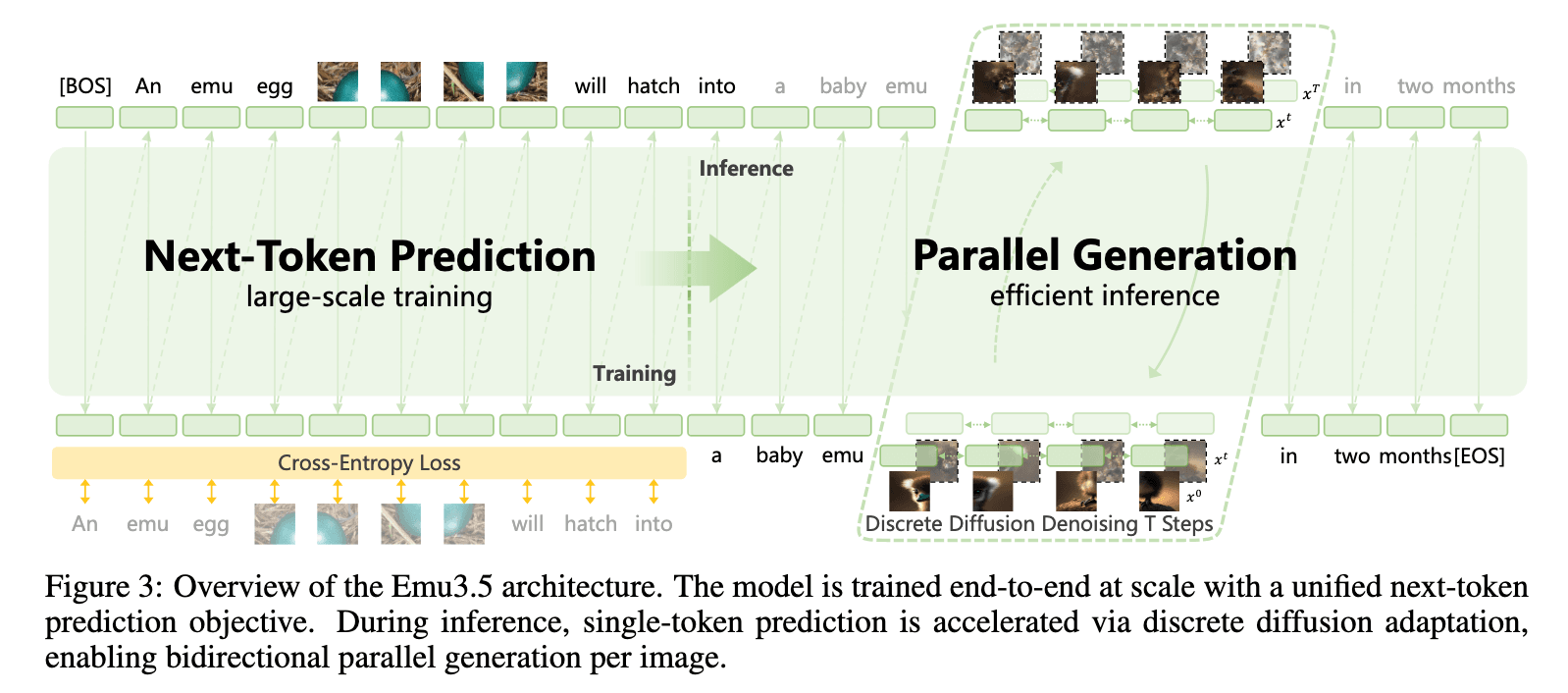
这意味着模型可以在图像与文本的生成过程中动态预测下一步,从而构建出“像在讲故事”或“像在做视觉指导”一样的生成体验。
要做到这一点,Emu3.5 本身既是强大的语言模型,也是优秀的图像生成器,同时还能做任意形式的图像编辑。
模型的预训练数据集非常庞大,由四类主要内容组成:
- 视觉–语言交错数据:带有逐段文字描述的视频
- 图像–文本对:图像与详细文字说明
- 任意到图像的数据:图像序列及描述图像变化的文字
- 纯文本数据:用于 LLM 训练
模型的训练流程分为四个主要阶段:
- S1 阶段:在 10 万亿 tokens 上进行初始预训练
- S2 阶段:再训练 3 万亿 tokens,用于提升分辨率、准确度等能力
- 监督微调阶段:让模型学会多模态任务,包括 any-to-any 和视觉引导
- 强化学习阶段:让模型更符合人类标准,提升泛化、任务表现与“一模型多任务”的统一能力
在 Gradient GPU Droplet 中启动 Emu3.5
要运行 Emu3.5,我们需要足够的 GPU 算力。建议至少使用 一块 NVIDIA H200。 你可以参考 DigitalOcean 中国区独家战略合作伙伴卓普云在其官网发布的 GPU Droplet 环境搭建教程,完成 AI/ML 环境配置:https://blog.aidroplet.com/tutorials/do-gpu-jupyter-dl-setup/
当然,DigitalOcean 还有其它型号的 GPU,同样可以运行 Emu3.5,例如 H100、MI325X、MI300X 等。如需了解详情,可咨询卓普云 aidroplet.com。
当 GPU Droplet 启动并通过 SSH 连接成功后,就可以继续下一步。
Emu3.5 视觉引导 Gradio Demo
在 GPU Droplet 中运行以下命令即可安装 Emu3.5:
git clone https://github.com/baaivision/Emu3.5
cd Emu3.5
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
pip install flash_attn==2.8.3 --no-build-isolation
mkdir weights
hf download BAAI/Emu3.5-VisionTokenizer --local-dir ./weights/Emu3.5-VisionTokenizer/
hf download BAAI/Emu3.5 --local-dir ./weights/Emu3.5/
hf download BAAI/Emu3.5-Image --local-dir ./weights/Emu3.5-Image/
这段代码需要几分钟,会完成所有环境准备。
安装完成后,可以用下面的命令启动内置 demo:
图像生成或图像编辑:
CUDA_VISIBLE_DEVICES=0 python gradio_demo_image.py --host 0.0.0.0 --port 7860
视觉引导和故事生成:
CUDA_VISIBLE_DEVICES=0 python gradio_demo_interleave.py --host 0.0.0.0 --port 7860
我们将在本文展示后者。当它启动完成后,按照设置教程中的说明,使用你的 VS Code/Cursor 应用程序内置的简单浏览器,在本地浏览器中打开输出的 URL。

现在,让我们看看应用页面。页面中央有一个“Generation Mode”选项,这里提供两个模式。选择“howto”即可启用视觉引导。接下来,我们可以输入希望模型演示的任务。例如,我们让模型展示在加州淘金热时期如何挖金。模型输出了一个由 5 个步骤组成的流程,展示了如何在溪流和河道中淘金,如下图所示。
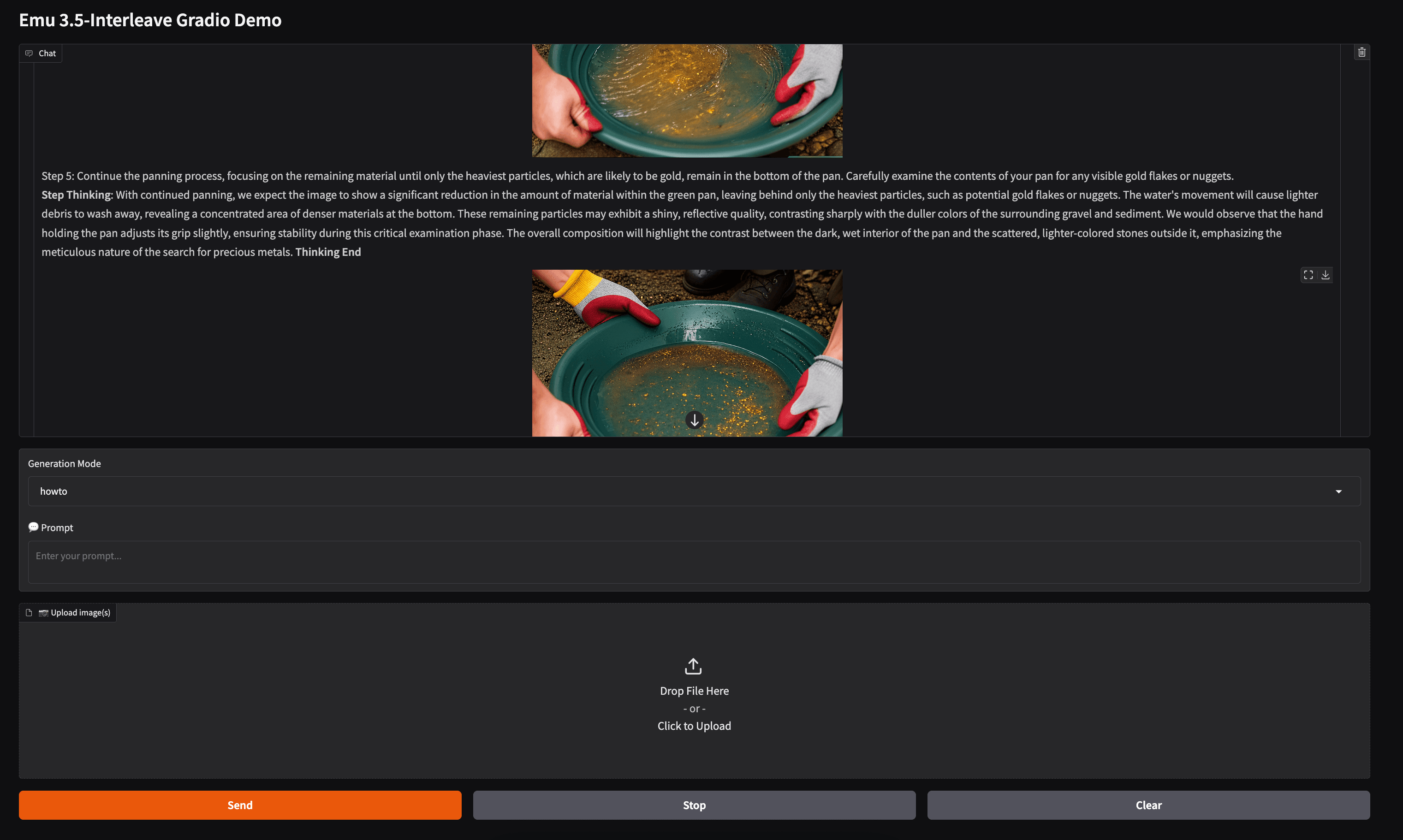
可以看到,指令细节丰富,配图对完成任务非常有帮助。我们还让模型执行了其他多种任务,例如展示如何装订一本书,以及如何进行 3D 建模并打印一个动作人偶,效果都很出色。总体来看,在 Emu3.5 中,视觉引导模型的 LLM 驱动指令生成能力非常强大。
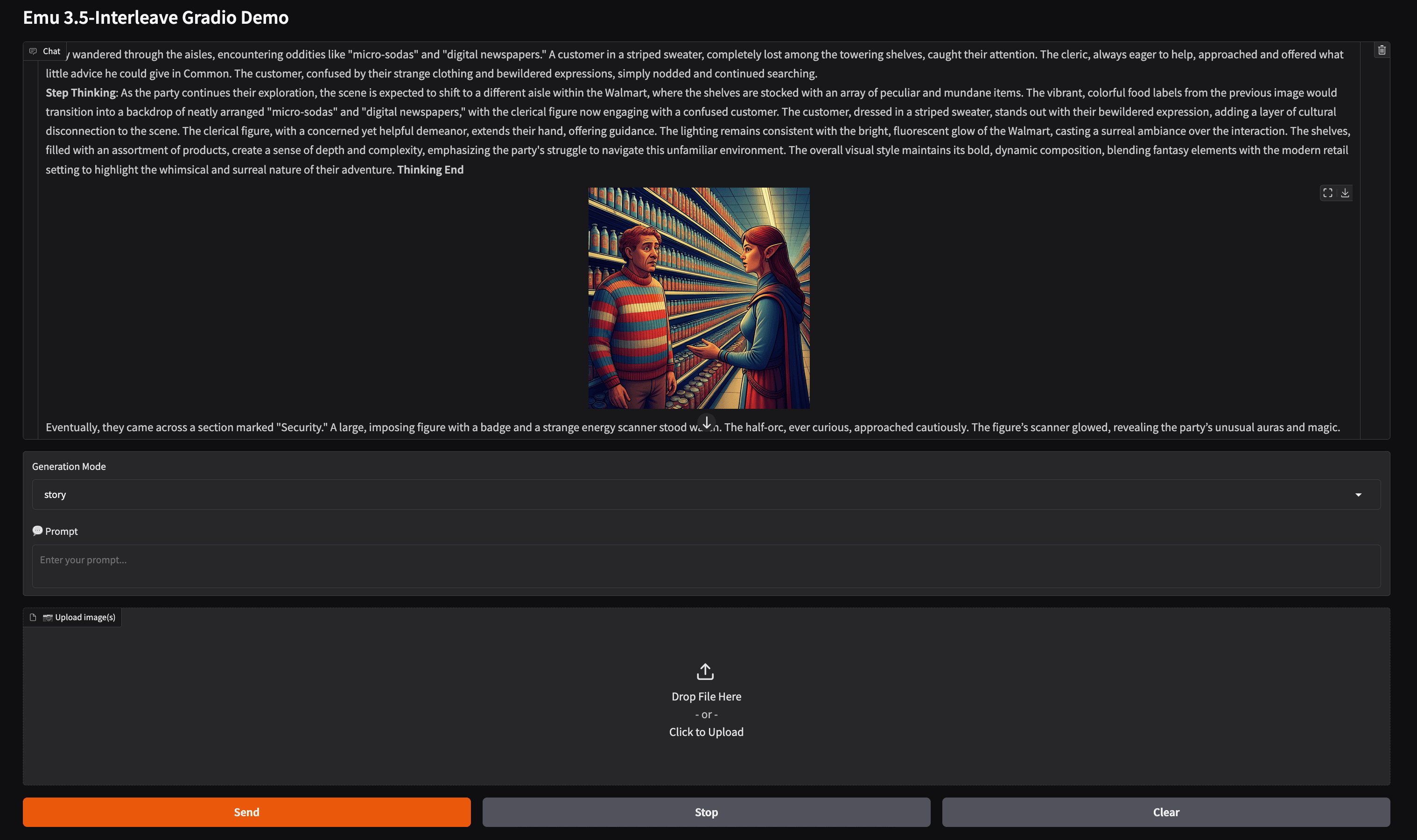
除了实用功能外,模型在讲故事方面也非常有趣。我们让模型讲述一个传统《龙与地下城》探险小队迷失在现代沃尔玛的故事,对于模型如何想象角色的行为方式,我们感到十分惊喜。

最后,我们来看另一个演示:图像生成与编辑 Demo。请看上面的示例。我们让模型把一张二维卡通恐龙的图画变成真实的三维效果。模型完成得非常好,几乎看不到任何瑕疵或二维原图的痕迹。这只是模型图像编辑能力的一个例子。总体来看,我们发现它比我们在图像编辑评测中测试过的许多模型都更强大、更灵活,甚至超过了 Qwen Image Edit。
总结
Emu3.5 可以说是近期图像生成领域最具突破性的技术之一。它能把图像和文本交替生成,组合成故事或操作指南,这让 LLM 与视觉能力真正集成到了可解决实际问题的方向。此外,Emu3.5 本身也是非常强大的图像生成和编辑模型。
我们非常推荐使用 Emu3.5 来创作视觉指导内容或图像编辑任务。它在多个维度上都领先于同类模型。