AI 现已深度融入现代软件开发。各行各业的团队都在借助 AI 解决产品和流程问题。然而,构建生产级系统仍然复杂。部署 AI 最难的部分,往往不在模型本身,而在模型之外的一切。
更关键的是:不同技术栈之间的成本差异,往往并不体现在 GPU 或模型调用价格上。
在很多实际场景中,两种方案的基础设施和模型支出可能大致相当。但一旦将跨云架构带来的工程复杂性与人力投入计算在内,总体拥有成本(TCO)会迅速拉开差距。
当存储、计算、编排、网络、认证和推理分属不同系统、各自采用不同运维模式时,这种复杂性就会演变为“胶水代码”问题。工作流跨越的“接缝”越多,开发者就越难专注于构建产品逻辑,而不得不把时间花在“把系统拼起来”。
本文要回答的核心问题不是“哪家更便宜”,而是:为什么看起来成本相近的两种 AI 架构,最终总成本会完全不同?
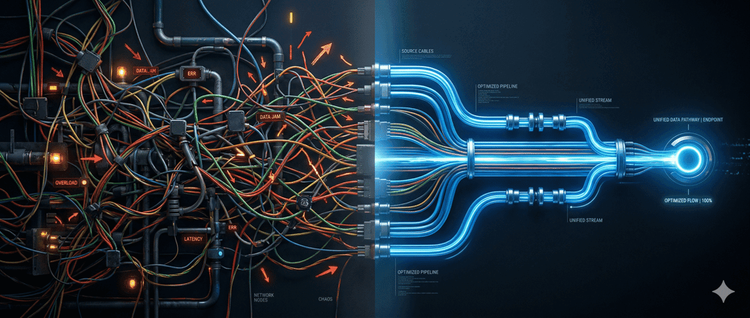
真正的问题是碎片化
来看一下当今 AI 部署的现状。AI 应用远不止依赖推理。真实的工作流涉及对象存储、计算、提示词转换、模型端点、持久化以及监控,每个环节都需要专门的运维知识。
而这些组件通常无法原生连接——这恰恰是当前的现状:产品、资源和服务各自为政,往往只能通过 API 相互连接。
结果是,开发者不得不花费大量时间建立和维护这些连接。填补不同云之间的鸿沟,需要大量人工操作。这种割裂系统在扩展、安全和调试方面都更加困难。
更重要的是,这些看似只是“工程复杂度”的问题,最终都会转化为成本——要么是更长的开发周期,要么是更多的人力投入。
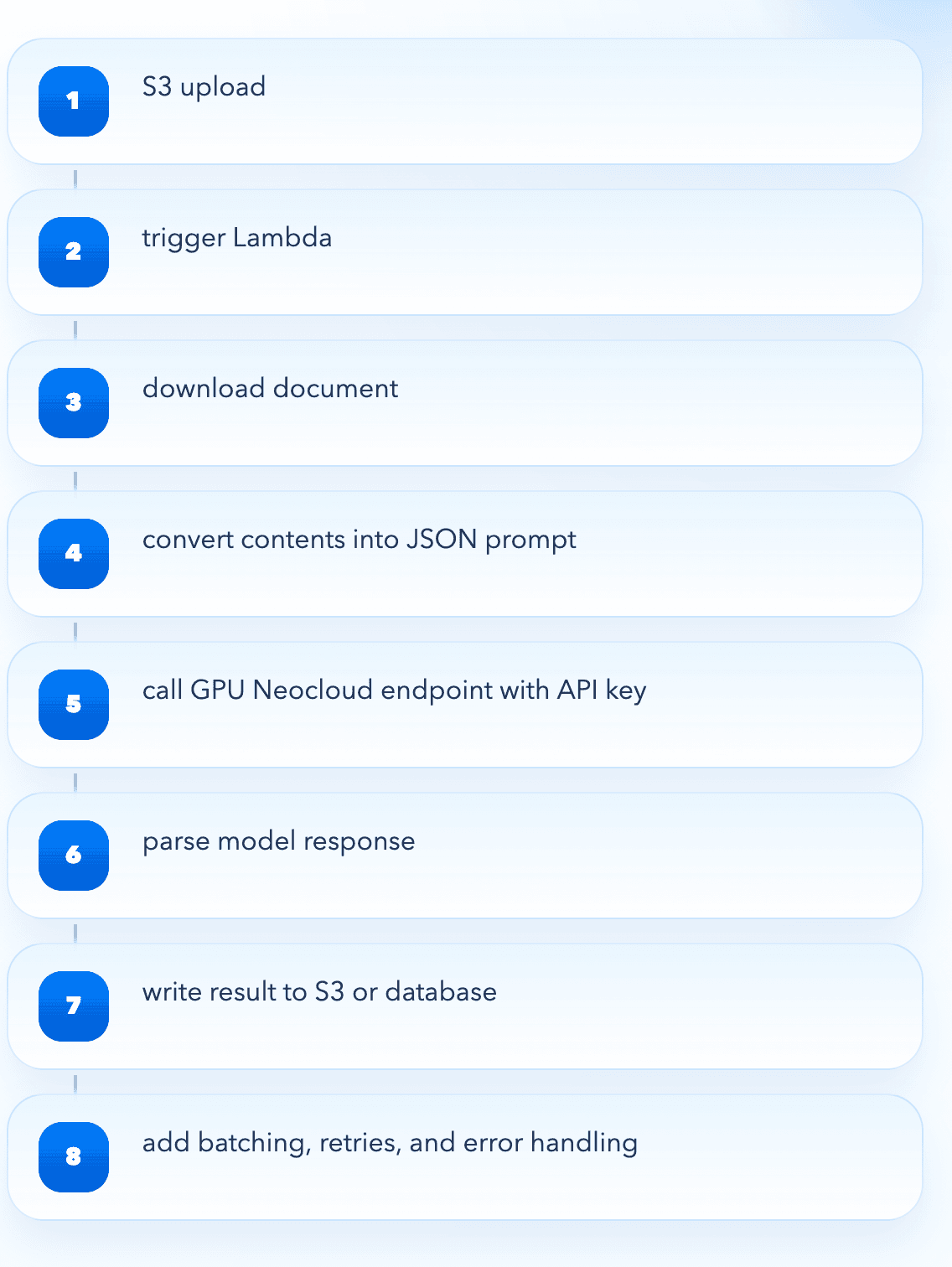 考虑这样一种组合:像 Baseten 或 Fireworks.AI 这样的新型云平台,搭配 AWS 这样的超大规模云厂商。在这种架构下,前者托管模型,而超大规模云厂商负责编排周边的应用或工作流。例如,一个处理用户上传文档并用大语言模型进行摘要的应用。开发者通常需要:
考虑这样一种组合:像 Baseten 或 Fireworks.AI 这样的新型云平台,搭配 AWS 这样的超大规模云厂商。在这种架构下,前者托管模型,而超大规模云厂商负责编排周边的应用或工作流。例如,一个处理用户上传文档并用大语言模型进行摘要的应用。开发者通常需要:
通过 API 密钥管理认证,而非使用共享的云身份原语。在 AWS 中,文件上传可通过 S3 事件触发 Lambda 函数。在这个例子里,Lambda 会下载文件,将其内容转换为 JSON 格式的提示词,然后使用 API 密钥通过 HTTP 请求发送到新型云平台的模型端点。模型返回响应,Lambda 解析响应并将其写回 S3 或数据库。
如果模型已缩容到零,请求可能会遇到额外延迟;而在处理大批量任务时,开发者必须自行实现批处理、重试和错误处理。新型云平台并不原生管理这一整套流程,开发者需要负责协调 AWS 各服务与外部推理层之间的每一个步骤。
这些工作并不产生业务价值,但必须存在。
本质上,这些“连接工作”,就是成本的开始。这种复杂性也直接推高了成本。
这对开发者意味着什么
这种运维上的复杂性,在规模扩大后会被放大。
首先,扩展变得更难。每增加一个服务集成点,就增加一个潜在故障点,同时也增加一段需要长期维护的代码。
换句话说:每一个“接缝”,不仅是系统风险点,也是一个持续消耗人力的成本点。
其次,网络问题更加棘手。模型通过公共 API 暴露,使其更像外部 SaaS,而非原生基础设施,带来安全、延迟和流量问题。
最后,数据管道缺乏集成。开发者必须自行搬运数据,并保证这些连接稳定运行。这进一步增加了工程负担。
在实践中,这会导致成本结构变得碎片化:
不同供应商、不同计费模型,使得成本难以预测、难以优化。
最终,团队不得不投入专门人力来维持系统运行。
胶水代码的隐性成本
一个典型的 AI 管道可能需要 5 到 10 个集成点,每个点都会引入延迟、故障风险和工程开销。在小规模时,这些问题尚可接受;但在规模扩大后,团队往往需要专职工程师来维护这些连接。这就是胶水代码的隐性成本变得无法回避的地方:在很多 AI 系统中,基础设施成本是可见的,但真正持续增长的,是工程人力成本。
一旦达到一定规模,推理服务最终需要从无服务器迁移到专用供应商。随着规模扩大,无服务器推理的效率可能会下降,因为你用简单性换来了对成本、性能和容量的控制力下降。它在低流量或不可预测流量场景下表现良好,但在高流量下,冷启动、并发限制、延迟波动以及按请求计费可能使其比专用基础设施更昂贵、更不可预测。专用供应商提供预留容量、更稳定的性能以及更大的 GPU 利用率优化空间——当推理成为产品核心且始终在线的功能时,这一点就至关重要。真正的专用服务通常集中在超大规模云平台上,这往往意味着开发者需要投入更多时间去学习、配置和管理它们的基础设施。这种额外的运维复杂性会显著增加开发者的负担,尤其是与最初让无服务器模式具有吸引力的简单性相比。
多云 AI 系统需要专门的专业知识来管理故障、重试、网络问题以及不同服务间的不一致行为。建立并留住能够运维这些系统的团队既昂贵又困难。在许多情况下,维护系统的成本甚至超过了运行系统的成本。
理想的 AI 云应该做什么
理想的 AI 推理云,不应只是托管模型,而应统一整个技术栈:
- 计算
- 存储
- 网络
- 推理
- 持久化
认证、权限、部署和日志应保持一致,工作流应成为平台能力,而不是开发者的负担。
垂直集成的价值,不在于“功能更多”,而在于:
减少开发者需要亲自连接的部分。
用 DigitalOcean 重新定义问题
为了更具体地理解这种差异,我们用同一个 AI 应用架构,对比两种实现方式:
- 方案 A:新型云 + 超大规模云(如 Baseten + AWS)
- 方案 B:一体化平台(DigitalOcean)
DigitalOcean 的AI推理云提供了一种切实可行的替代方案,它减少了开发者需要管理的“整合衔接”的数量。DigitalOcean 不依赖新型云平台(如上文提到的Baseten 或 Fireworks.AI )做推理、超大规模云厂商(AWS或GCP)做其他所有事情,而是将计算、存储和 AI 推理更紧密地整合在一个统一的平台模型之下。
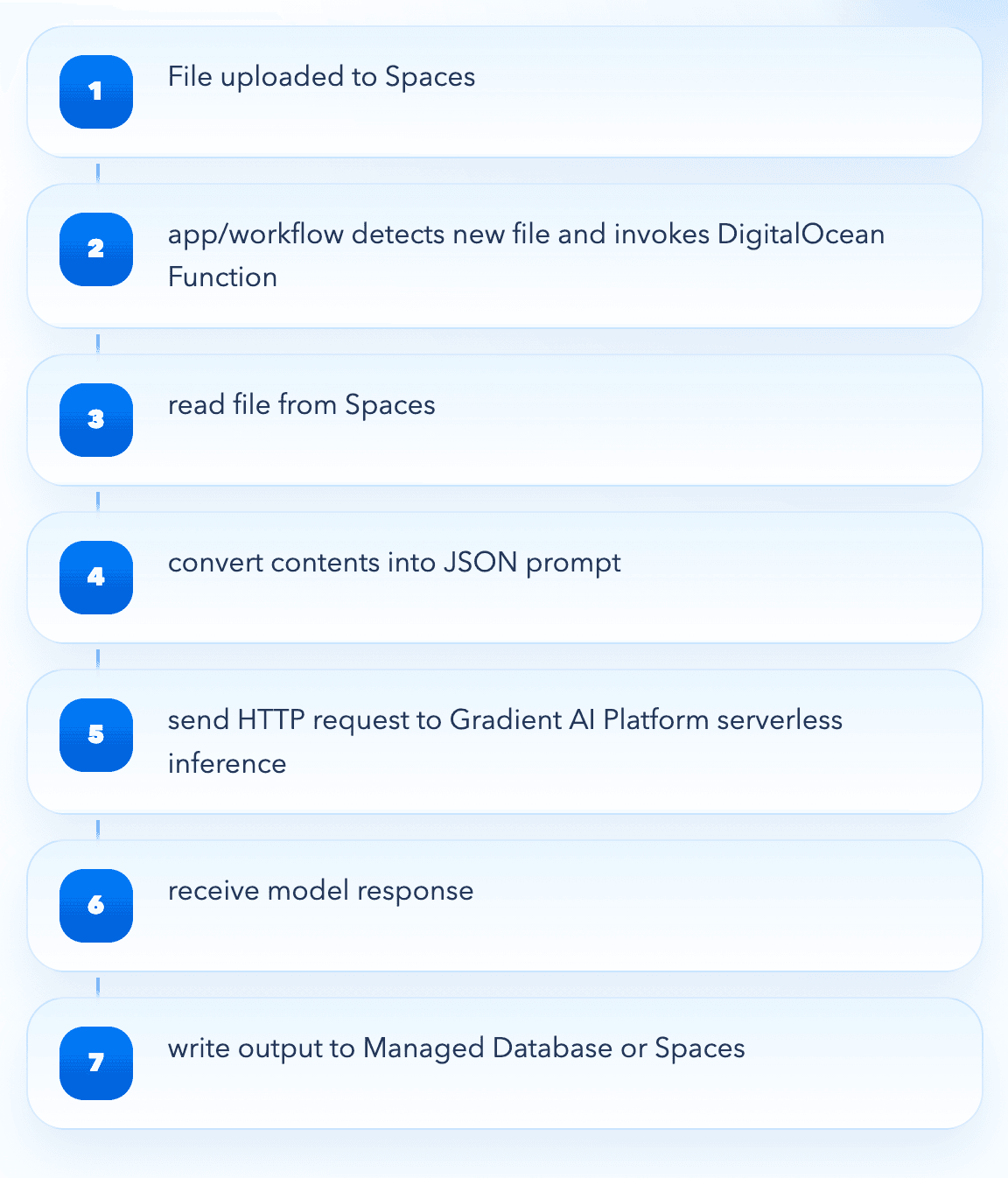
在 DigitalOcean 上,相同架构可以用更少组件实现:
- 文件存储在 Spaces对象存储
- 调用 Function(云函数) 处理数据
- 调用 Gradient AI 推理端点(支持Opus、Sonnet、Qwen、DeepSeek等)
- 结果写入数据库或存储
整个流程在同一平台内完成。
更少的集成点意味着更少的故障风险、更低的延迟、更清晰的成本可见性和更低的运维开销。最重要的是,再小的 AI 创业团队也可以构建和扩展 AI 应用,而无需投入工程师去维护胶水代码。
这种优势不仅仅是便利,更是一种杠杆。DigitalOcean 让开发者能够专注于构建智能应用,而不是维护“胶水代码”。
构建成本分析演示环境
为了验证上述架构,我们构建了一个演示项目(https://github.com/Jameshskelton/demo_do),并将其完全部署在 DigitalOcean 云平台上。目标是比较在集成平台(如 DigitalOcean)上大规模运行此应用的成本,与在碎片化技术栈(超大规模云厂商做基础设施 + 新型云做推理)上的成本。
在此次更新的分析中,我们采用更公平的模型比较:假设 DigitalOcean 上使用 openai-gpt-oss-120b,而推理供应商(如 Baseten)搭配超大规模云厂商也使用同一模型。其他工作流假设保持一致:
| 假设项 | 取值 |
|---|---|
| 每文档输入 token 数 | 10,000 |
| 每文档输出 token 数 | 500 |
| 每文档预处理耗时 | 约 2 秒(1 GB) |
| 每文档存储数据量 | 约 210 KB |
| 保留周期 | 30 天 |
| 所用模型 | gpt-oss-120b |
如果只看基础设施和模型调用成本,两种方案的差距其实非常有限。在所有规模区间内,差异基本维持在约 6% 左右。这意味着:单纯从“算力和模型价格”来看,两种方案几乎可以认为是持平的。但是,真正的经济差异体现在人力上。
成本分析(未计入人力开销)
| 月处理量 | DigitalOcean 方案 | Baseten + AWS 方案 | 模型 API 成本差异 | 差异百分比 |
|---|---|---|---|---|
| 100 万份摘要/月 | ~$1,391 | ~$1,306 | ~$85 | ~6% |
| 1000 万份/月 | ~$13,910 | ~$13,060 | ~$850 | ~6% |
| 5000 万份/月 | ~$69,550 | ~$65,300 | ~$4,250 | ~6% |
| 1 亿份/月 | ~$139,100 | ~$130,600 | ~$8,500 | ~6% |
举一个简单的例子:如果一家公司需要至少雇佣一名初级软件工程师(月薪约 7000 美元)来构建和维护创新的云平台+超大规模云厂商架构所需的集成工作,那么即使月处理量低于 5000 万份摘要,这笔人力成本也会轻易抹掉表面上的基础设施节省。而且随着系统变得复杂,这种负担会迅速放大。一个由四名初级工程师和一名月薪高出约 4000 美元的高级工程师组成的团队,其基础设施运维人力成本可能接近推理成本本身的一半。到那时,成本故事就不再只关乎 GPU 或 API 定价,而是你的平台为了系统运行需要消耗多少维护成本。
一个跨越新型云平台和超大规模云厂商的多供应商技术栈会引入真实的胶水代码问题:更多的连接代码、更多的集成点、更多的认证边界、更多的可观测面,以及跨供应商的更多故障模式。在企业级规模下,构建、维护、监控和演进这些“胶水工程”所需的工程努力本身就会成为一个真正的成本中心。相比之下,在像 DigitalOcean 这样单一集成平台上运行相同的业务,可以显著降低这些成本。存储、函数、托管数据库、应用托管和模型访问都位于同一环境内,这实质上降低了运维复杂性,从而降低了系统的长期人力成本。
因此,DigitalOcean 在原始使用量定价上具有巨大优势。而是:真正的差别是在人力成本上。当你需要额外 1–5 名工程师去维护跨云架构时,节省下来的基础设施成本会被迅速吞噬。这也是为什么:在账面价格相近的情况下,整体拥有成本却会出现显著差距,DigitalOcean 的集成平台在总体拥有成本上明显更便宜。
结论
现在的 AI 行业,模型访问变得更轻而易举,但围绕模型构建 AI 产品仍然非常关键。下一波 AI 平台的差异化重点将不是仅仅扩大模型目录或增加更多配置选项,而是谁能保证业务不断增长的同时,却投入了更少的工程维护成本,投入了更少的精力。
如果你希望更进一步了解DigitalOcean Gradient AI 推理云,欢迎咨询 卓普云(aidroplet.com)。
DigitalOcean目前可提供包括:
- GPU云服务器,如B300、H200、H100
- Gradient AI 无服务推理,支持GPT、Claude等模型调用
- NFS 网络文件存储
- Kubernetes 托管等。


