
随着大模型部署和推理变得越来越普及,开发者和企业对 GPU 的选择也越来越挑剔。特别是像 DeepSeek 这样的开源模型家族,从轻量级的 6.7B,到动辄上百亿甚至数百亿参数的超大模型,背后对算力和显存的要求各不相同。
最近,一则重磅消息在AI圈引起了轩然大波:连AI巨头OpenAI也在探索并计划使用AMD Instinct MI300x GPU! 这无疑是对AMD这款高性能GPU的巨大认可,也预示着它将在AI算力领域扮演越来越重要的角色。过去我们经常会围绕H100等NVIDIA GPU来分析它们适合什么AI 业务场景。而现在我们也要考虑考虑AMD这个性价比更好的选项。
如果你正打算在云端部署 DeepSeek 模型,那么一个绕不开的问题就是:到底是用 AMD 的 MI300X,还是 NVIDIA 的 H100?
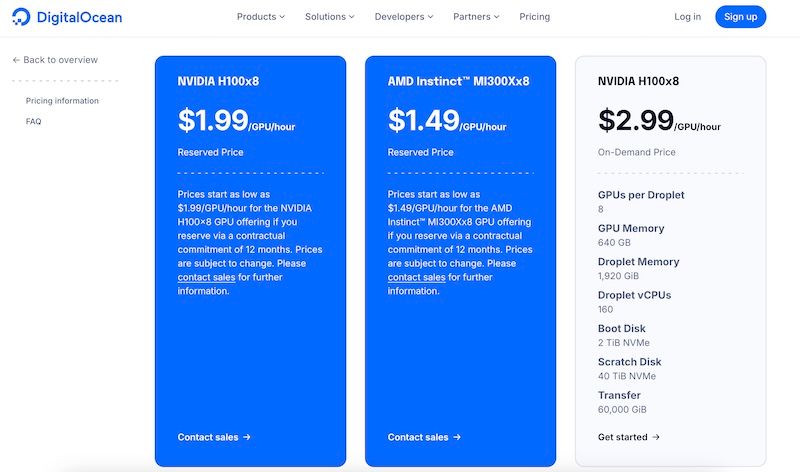
这两款顶级 GPU 均可在 DigitalOcean 云平台租用,并有明确的价格标准。在 DigitalOcean 上,MI300X 的按小时价格为 $1.99(年合约价低至 $1.49),而 H100 则是 $3.39(年合约价可低至 $1.99),且都提供单卡和 8 卡型号。虽然 DigitalOcean 的 MI300X 看起来价格更低,但部署模型需要综合考虑性价比。
我们接下来就从 DeepSeek 不同版本的实际资源需求出发,结合这两款 GPU 的性能和定价,来分析一下在哪些使用场景下选择 MI300X 更划算,而哪些情况下用 H100 更值得。
MI300X vs H100:显存与算力的博弈
先简单了解一下这两款卡的硬件规格。MI300X 搭载了 192GB 的 HBM3 显存,内存带宽高达 5.3 TB/s。这一点对大模型推理来说非常重要,因为很多模型在部署时首先卡的就是显存限制——不是推不动,而是装不下。而 H100 的单卡显存为 80GB,虽说也不小,但在面对上百亿参数的模型时就不那么“宽裕”了。
不过,H100 的优势则在于其算力。通过 Tensor Core 的加持,它在 FP16 和 INT8 精度下都拥有压倒性的性能,尤其适合大规模训练和高效微调。如果你的工作负载是密集计算型,或者需要极致的低延迟响应,H100 的训练和推理速度会有明显优势。
如果我们把两个GPU的一些基本参数列出来,可能大家能有更直观的感受。
| 参数 | MI300X | H100 (SXM) |
|---|---|---|
| 显存容量 | 192 GB | 80 GB |
| FP16 理论算力 | 383 TFLOPS | 1979 TFLOPS(含 TensorCore) |
| HBM 带宽 | 5.3 TB/s | 3.35 TB/s |
| 架构优势 | 高显存支持大模型 | 更成熟的软件生态 |
MI300X vs H100:不同 DeepSeek 模型对资源的需求
DeepSeek 系列覆盖了多个场景和模型尺寸。比如 DeepSeek-Coder 是专为代码生成优化的,有多个参数级别,最小到 6.7B,大到上百亿。而 DeepSeek-VL 则是多模态的语言-视觉模型,显存需求相对更高。DeepSeek-R1 是目前最重磅的系列,从 67B 到 761B 都有。
不同模型在部署时的“胃口”也完全不同。6B 左右的模型,用一张 24GB 显存的卡也许就能跑,但想要部署 67B、236B 甚至 761B 的版本,往往需要多卡并行,或者干脆上集群。
这就让 MI300X 的显存优势变得尤为突出。比起 H100 多出的 112GB 显存意味着什么?意味着你可以部署更大的模型,使用更大的 batch size,也更容易实现高吞吐推理。尤其是在推理任务中,对显卡主频或 TFLOPS 的要求远不如对显存的依赖。
| 模型版本 | 参数量 | 推荐显存 (推理) | 推荐 GPU |
|---|---|---|---|
| DeepSeek-MoE-16B | 16B | ≥40 GB | MI300X/H100 均可 |
| DeepSeek-Coder-6.7B | 6.7B | ≥24 GB | MI300X 更具性价比 |
| DeepSeek-VL-7B | 7B | ≥32 GB + 多模态支持 | MI300X 更适配多模态 |
| DeepSeek-R1-67B | 67B | ≥80–100 GB | 需要分布式 GPU,MI300X 优势明显 |
| DeepSeek-R1-236B | 236B | ≥160–200 GB | 多卡部署,MI300X 显存为关键 |
| DeepSeek-R1-761B | 761B | ≥512 GB+ | 多节点部署,MI300X 成本更优 |
DeepSeek 推理 vs 微调:用 MI300x 还是 H100?
如果你的业务主要是推理,比如上线一个问答机器人、代码补全服务,或者提供 API 接口调用大模型,其实更关注的是吞吐量和单位时间成本。这种场景下,MI300X 几乎是天然的性价比之选。它不仅显存大,还便宜,跑同样一个模型,MI300X 不仅能装得下,还能一次跑更多样本,整体来看吞吐比 H100 更划算。
但如果你要做的是微调(fine-tuning)或者 LoRA 微调,尤其是在开发迭代周期比较短、模型需要频繁调优的场景下,H100 的表现就更胜一筹。它的 Tensor Core 和 CUDA 生态,使得主流深度学习框架(比如 PyTorch 和 DeepSpeed)在训练速度上占据优势。举个例子,同样是对 DeepSeek-Coder 做一次 LoRA 微调,H100 可能只需 5 小时,而 MI300X 可能得跑 7 小时以上,长远看下来时间成本也转化为金钱成本。
总个结一下:
- 以推理为主:选择 MI300X 更具性价比
- DeepSeek-Coder/DeepSeek-VL/DeepSeek-R1 小模型;
- 单卡显存高、支持更大 batch size;
- 成本节省明显($1.49/hr vs $1.99/hr);
- 支持高吞吐量部署、多实例并发运行。
- 以微调为主:H100 更高效
- DeepSeek-Coder 精调(如函数补全、代码生成任务);
- Tensor Core 适配主流深度学习框架(PyTorch、Megatron)更成熟;
- 微调速度快,整体训练成本反而更低;
- 软件栈生态更完善,部署配置更轻松。
- 多卡 大模型 推理/推理微调混合场景:MI300X 多卡部署更经济
- DeepSeek-R1-67B、236B、761B 需 2–8 GPU 部署;
- MI300X 的 192GB 显存使得横向扩展更灵活;
- 性价比优于 H100(尤其在年合约下)。
MI300X与H100的多卡部署,大模型的性价比战场
当模型参数量突破 100B 的关口,单卡算力已然捉襟见肘,此时多卡部署成为必然选择。以 DeepSeek-R1-236B 和 761B 这样的超大规模模型为例,它们对显存的需求是巨大的,这就使得“单位显存成本”在多卡部署场景中变得至关重要。
在 DigitalOcean 云平台上,我们可以清晰地看到两款 GPU 在年合约价下的显存成本差异:
- DigitalOcean MI300X: 年合约价每小时 $1.49,配备 192GB HBM3 显存。
- DigitalOcean H100: 年合约价每小时 $1.99,配备 80GB HBM3 显存。
由此可见,在 DigitalOcean 上,MI300X 的每 GB 显存成本显著低于 H100,在单位显存上更具性价比。
更具决定性意义的是 MI300X 的巨大显存容量优势。每张 MI300X 提供 192GB 的 HBM3 显存,远超 H100 的 80GB。这意味着在部署像 DeepSeek-R1-236B 这样对显存要求极高的大模型时,MI300X 能够提供更高的单卡承载能力。根据独立分析,对于大规模模型和高并发推理工作负载,MI300X 在高并发场景下能实现更高的峰值系统吞吐量,并带来更低的每 token 成本。其大显存不仅显著提升了多卡部署的灵活性,能够以更少的卡数满足模型显存需求,从而简化部署复杂性并有效降低总体基础设施成本。这使得 DigitalOcean 的 MI300X 成为大规模模型推理,尤其是追求极致性价比和效率的首选。
小结
在这个参数爆炸、成本内卷的时代,聪明的 GPU 选型已经不再只是“多快好省”的选择题,而是一场关于资源利用率和业务目标的策略战。如果你正在用 DeepSeek,也在纠结部署在哪张卡上,不妨用今天这些数据和分析,算一笔明白账。
| 任务类型 | 推荐 GPU | 说明 |
|---|---|---|
| 单卡推理 | MI300X | 显存大,成本低 |
| 多模态推理 | MI300X | 更高 HBM 带宽处理图像更好 |
| 精调/LoRA 微调 | H100 | 更快训练速度 |
| 大模型并发部署 | MI300X | 每卡成本低,更适合 scale-out |
| 极限推理延迟优化 | H100 | 高性能适配低延迟需求 |
综上,MI300X 和 H100 并没有绝对的优劣,真正的选择标准取决于您的使用场景。如果您计划在 DigitalOcean 上部署轻量级 DeepSeek 模型,主要用于推理并希望压缩成本,那么选择 DigitalOcean MI300X 更具性价比,它不仅价格实惠,显存也更大,运行更稳定。如果您在 DigitalOcean 上进行模型微调,且对训练速度有严格要求,那么选择 DigitalOcean H100 会更高效,因为它能节省大量时间。 对于深度混合型业务,例如同时进行推理和 LoRA 微调,并需要兼顾吞吐量和训练时效的场景,您可以在 DigitalOcean 云平台上灵活组合选型,将推理任务部署在 MI300X 上,而训练任务交给 H100。
充分利用 DigitalOcean 的弹性租用机制,您可以做到‘哪款 GPU 适合哪种任务,就让它专门负责哪种任务’。更重要的是,DigitalOcean相对于AWS、谷歌云服务等一线平台来讲,价格更加透明,计费规则更简单。如需了解更多,可联系DigitalOcean中国区独家战略合作伙伴卓普云AIDroplet咨询更多 GPU 服务器选项,在海外部署稳定可靠且低成本的GPU服务器。


