
在人工智能和深度学习领域,GPU 的性能直接影响模型的训练速度和推理效率。随着技术的迅速发展,市场上涌现出多款高性能的 GPU,尤其是英伟达的旗舰产品。本文将对比四款基于 2020 年后架构的显卡:NVIDIA H200、H100、A100、A6000、L40S和 AMD MI300X、MI325X。通过深入分析这些 GPU 的性能指标,我们将探讨它们在模型训练和推理任务中的适用场景,以帮助用户在选择适合的 GPU 时做出明智的决策。同时,我们还会给出一些实际有哪些知名的公司或项目在使用这几款 GPU。
主流几款 GPU 中哪些适合推理?哪些适合训练?
那么进行一下指标对比,在 NVIDIA H200、H100、A100、A6000、L40S和 AMD MI300X、MI325X,这几个GPU 中,分析哪些 GPU更适合 做模型训练任务,哪些 GPU 更适合做推理任务。
以下是 NVIDIA H100、A100、A6000、L40s的主要性能指标参数表:
| GPU 型号 | 架构 | FP16 性能 | FP32 性能 | 显存 | 显存类型 | 带宽 |
|---|---|---|---|---|---|---|
| H200 | Hopper | 1,979 TFLOPS | 60 TFLOPS | 141GB | HBM3e | 4.8 TB/s |
| MI325X | CDNA 3 | ≈2,600 TFLOPS | ≈82 TFLOPS | 256GB | HBM3e | 6.0 TB/s |
| MI300X | CDNA 3 | 1,307 TFLOPS | 61.4 TFLOPS | 192GB | HBM3 | 5.3 TB/s |
| H100 | Hopper | 1,671 TFLOPS | 60 TFLOPS | 80GB | HBM3 | 3.9 TB/s |
| A100 | Ampere | 312 TFLOPS | 19.5 TFLOPS | 40GB / 80GB | HBM2 | 2,039 GB/s |
| A6000 | Ampere | 77.4 TFLOPS | 38.7 TFLOPS | 48GB | GDDR6 | 768 GB/s |
| L40s | Ada Lovelace | 731 TFLOPS | 91.6 TFLOPS | 48GB | GDDR6 | 864 GB/s |
这个表格总结了每个GPU的架构、FP16/FP32计算性能、Tensor Core性能、显存大小、显存类型以及内存带宽,便于比较各个GPU在不同任务场景中的适用性。按照架构来讲,越新的架构肯定性能相对更好,这些架构从旧到新依次是:
- Ampere(2020年发布)
- Ada Lovelace(2022年发布)
- Hopper(2022年发布)
在选择用于大语言模型(LLM)训练和推理的GPU时,不同GPU有着各自的特性和适用场景。以下将对这些GPU进行分析,探讨它们在模型训练和推理任务中的优劣势,帮助明确不同GPU的应用场景。
1、NVIDIA H200
适用场景:
-
模型训练:H200 是 NVIDIA 在 Hopper 架构上的增强版本,核心提升集中在显存容量与内存带宽。单卡最高 141GB HBM3e 显存和约 4.8 TB/s 带宽,使其在训练超大参数模型(如百亿到万亿参数规模)时,显著减少跨节点通信和参数切分需求。对于需要长上下文或大 batch size 的训练任务,H200 能提供比 H100 更稳定的训练效率。
-
推理:在推理场景中,H200 的大显存优势尤为明显,能够容纳更大的模型或更多并发会话,适合高吞吐、低延迟的大模型在线推理服务。其整体定位仍偏向高端数据中心与超大规模集群,单卡成本较高,更常用于关键核心业务。
实际用例
NVIDIA 与云服务商: H200 被 NVIDIA 定位为面向下一代 AI 基础设施的核心产品,已被多家头部云厂商(包括 AWS、Google Cloud、Microsoft Azure)纳入新一代 AI 实例规划,用于支持更大规模的生成式 AI 训练和推理工作负载。
大型 AI 研究机构与企业用户: 多个从事前沿大模型研究的机构正在以 H200 作为 H100 的升级方案,重点用于长上下文模型、MoE 模型以及多模态大模型的训练与推理,以降低节点数量并简化系统架构。
2、AMD Instinct MI300X
适用场景:
-
模型训练:MI300X 是 AMD 面向生成式 AI 推出的高端加速卡,基于 CDNA 3 架构,最大的特点是单卡集成 192GB HBM3 显存和超过 5 TB/s 的内存带宽。在训练大模型时,它能够在更少 GPU 数量的情况下完成模型并行,特别适合显存受限场景下的超大模型训练。
-
推理:MI300X 在推理场景中具有明显的性价比优势。大显存使其能够在单卡上部署更大规模的模型,减少分片和通信开销,非常适合大语言模型、推荐系统和搜索相关的推理任务,尤其在批量推理和高并发场景中表现突出。
实际用例
已有2000万用户的AI虚拟角色生成平台 Character. ai 迁移至 DigitalOcean 云平台。Character.ai、DigitalOcean、AMD、三方紧密合作,基于 AMD Instinct™ MI300X 和 MI325X GPU 平台进行了深度优化,使 Character.ai 在成本降低的同时,推理吞吐量提升了 2 倍。
3、AMD Instinct MI325X
适用场景:
-
模型训练:MI325X 是 MI300X 的增强型号,同样基于 CDNA 3 架构,但显存容量提升至 256GB,并升级为 HBM3e,带宽达到约 6 TB/s。其设计目标是进一步降低大模型训练中对多卡并行和复杂通信的依赖,适合超大规模参数模型和高分辨率多模态模型的训练任务。
-
推理:在推理场景下,MI325X 能够在单卡或少量 GPU 上承载极大规模的模型实例,非常适合需要高密度部署的大模型推理集群。相较于同级别 NVIDIA 产品,其核心优势依然体现在显存容量和带宽,为推理系统提供更高的部署灵活性。
实际用例
AMD 官方合作伙伴与云厂商: MI325X 已被 AMD 定位为面向 2025 年 AI 数据中心的关键产品,多家云服务商和系统集成商已宣布将在新一代 GPU 实例和 AI 集群中引入该型号,例如DigitalOcean云平台,用于支持更大规模的生成式 AI 应用。
4、NVIDIA H100
适用场景:
- 模型训练:H100是目前NVIDIA最先进的GPU,设计专门用于大规模AI训练。它拥有超强的计算能力、超大的显存和极高的带宽,能够处理海量数据,特别适合训练GPT、BERT等大规模语言模型。其Tensor Core性能尤为出色,能够极大加速训练过程。
- 推理:H100的性能也能轻松应对推理任务,尤其在处理超大模型时表现优异。但由于其高能耗和成本,一般只在需要极高并发量或实时性要求下用于推理任务。
实际用例
Inflection AI: 在微软和 Nvidia 的支持下,Inflection AI 计划使用22,000 个 Nvidia H100 计算 GPU(可能与 Frontier 超级计算机的性能相媲美)构建一个超级计算机集群。该集群标志着 Inflection AI 对产品(尤其是其 AI 聊天机器人 Pi)扩展速度和能力的战略投资。
Meta: 为了支持其开源通用人工智能 (AGI) 计划,Meta 计划在 2024 年底前购买 350,000 个 Nvidia H100 GPU。Meta 的大量投资源于其增强先进 AI 功能和可穿戴 AR 技术基础设施的雄心。
5、NVIDIA A100
适用场景:
- 模型训练:A100是数据中心AI训练的主力GPU,特别是在混合精度训练中具有极强的表现。其较高的显存和带宽使得它在处理大型模型和大批量训练任务时表现卓越。
- 推理:A100的高计算能力和显存也使其非常适合推理任务,特别是在需要处理复杂神经网络和大规模并发请求时表现优异。
实际用例
Microsoft Azure: Microsoft Azure 将 A100 GPU 集成到其服务中,以促进公共云中的高性能计算和 AI 可扩展性。这种集成支持各种应用程序,从自然语言处理到复杂的数据分析。
NVIDIA 的 Selene 超级计算机: Selene 是一款NVIDIA DGX SuperPOD 系统,采用 A100 GPU,在 AI 研究和高性能计算 (HPC) 中发挥了重要作用。值得注意的是,它在科学模拟和 AI 模型的训练时间方面创下了纪录——Selene 在最快工业超级计算机 Top500 榜单中排名第 5。
6、NVIDIA A6000
适用场景:
- 模型训练:A6000在工作站环境中是非常合适的选择,特别是在需要大显存的情况下。虽然它的计算能力不如A100或H100,但对于中小型模型的训练已经足够。其显存也能支持较大模型的训练任务。
- 推理:A6000的显存和性能使其成为推理的理想选择,尤其是在需要处理较大的输入或高并发推理的场景中,能提供平衡的性能和显存支持。
实际应用
拉斯维加斯球顶巨幕:拉斯维加斯的球顶巨幕使用了 150 个 NVIDIA A6000 GPU,供其处理和渲染球顶巨幕需要显示的动画内容。

7、 NVIDIA L40s
适用场景:
- 模型训练:L40s为工作站设计,并且在计算能力和显存上有较大提升,适合中型到大型模型的训练,尤其是当需要较强的图形处理和AI训练能力结合时。
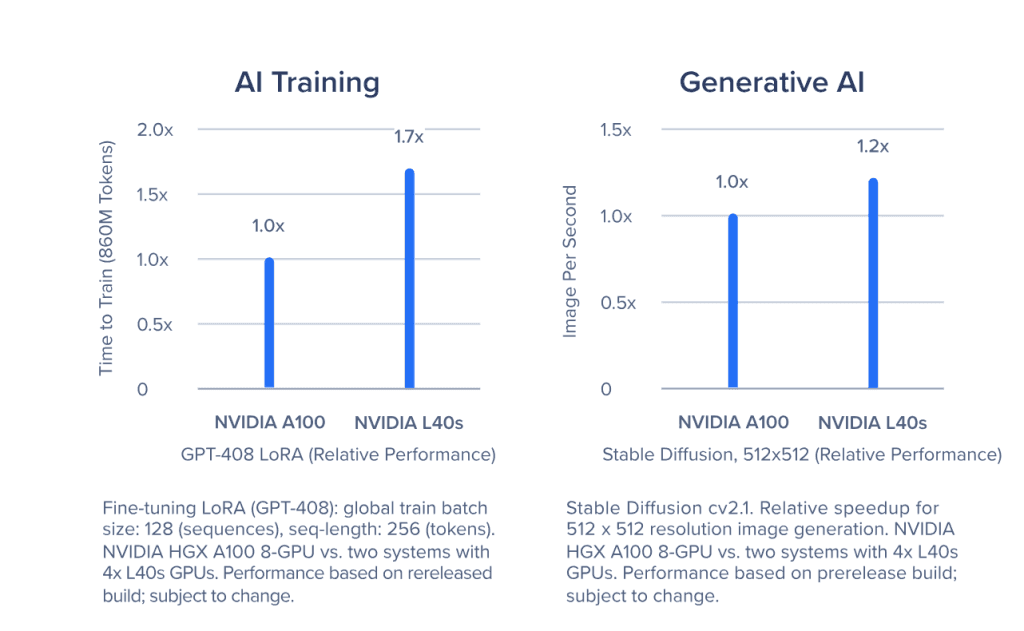
- 推理:L40s的强大性能和大显存使其非常适合高性能推理任务,尤其是在工作站环境下的复杂推理任务。如下图所示,虽然 L40s 的价格比 A100 要低,但是在文生图模型的测试中,它的性能表现比 A100 要高 1.2 倍,这完全是由于其Ada Lovelace Tensor Cores 和 FP8 精度所致。
实际用例
动画工作室: NVIDIA L40S 被广泛应用于动画工作室的3D 渲染和复杂视觉效果。其处理高分辨率图形和大量数据的先进功能使其成为媒体和游戏公司制作详细动画和视觉内容的理想选择。
医疗保健和生命科学: 医疗保健机构正在利用 L40S 进行基因组分析和医学成像。GPU 在处理大量数据方面的效率正在加速遗传学研究,并通过增强的成像技术提高诊断准确性。
结论
综合以上各代 GPU 的架构、算力指标、显存配置以及真实落地案例,可以看到,不同 GPU 在 模型训练 与 模型推理 场景中的优势并不相同,选型时需要结合模型规模、并发需求以及整体成本进行权衡。
更适合用于模型训练的 GPU
NVIDIA H200 / H100
这两款 GPU 代表了目前 NVIDIA 在数据中心 AI 训练领域的最高水平。
- H200 通过显存容量(141GB)和带宽(HBM3e)的大幅提升,更适合训练超大参数模型、长上下文模型以及 MoE 架构模型,能够有效减少节点数量和通信开销。
- H100 依然是当前大规模模型训练的事实标准,在算力、软件生态和成熟度方面具有明显优势,广泛应用于头部 AI 公司和研究机构。如果预算充足、追求极致性能和成熟生态,这两款卡依然是训练任务的首选。
AMD Instinct MI300X / MI325X
AMD 的 MI300X 和 MI325X 在训练场景中最大的优势在于超大显存和极高内存带宽。
- MI300X(192GB HBM3) 已经可以在单卡或少量 GPU 上完成原本需要多卡并行的训练任务,非常适合显存受限的大模型训练。
- MI325X(256GB HBM3e) 进一步将这一优势放大,更适合万亿参数级模型和高分辨率多模态模型的训练。在合适的软件栈和平台支持下,这两款 GPU 已成为 H100/H200 之外,极具吸引力的训练级替代方案。
NVIDIA A100
A100 虽然架构较老,但依然是当前大规模 AI 训练中的“中坚力量”。在混合精度训练、稳定性以及生态支持方面表现成熟,适合对性能要求较高、但不追求最新架构的训练任务。
-
NVIDIA A6000 / L40S(有限训练场景)
这两款卡并非典型的数据中心训练 GPU,但在中小规模模型训练或工作站环境中仍具备一定实用性。其中:- A6000 更偏向显存友好型训练;
- L40S 在 FP32 和部分 AI 负载上性能较强,但不适合复杂的大规模多卡训练。
更适合用于模型推理的 GPU
AMD Instinct MI300X / MI325X
在推理场景中,MI300X 和 MI325X 的优势尤为明显。
超大显存使其能够在单卡上部署更大模型或更多并发实例,减少模型分片和通信成本,非常适合大语言模型、搜索、推荐系统等高并发推理任务。在实际案例中,MI300X / MI325X 已经验证了在推理吞吐量和成本控制上的显著优势。
NVIDIA L40S / A6000
这两款 GPU 是当前性价比推理卡型的代表:
- L40S 依托 Ada Lovelace 架构和 FP8 Tensor Core,在文生图、视频生成和通用推理任务中表现突出,性价比优于 A100。
- A6000 在需要较大显存、但不追求极致算力的推理场景中依然非常实用,适合企业内部部署或云端中端推理负载。
NVIDIA A100 / H100 / H200(高端推理)
这些 GPU 在极高并发、低延迟或实时性要求极强的推理场景中表现出色,但由于其成本较高,如果仅用于普通推理任务,往往存在一定的性能浪费,更适合承担“训练 + 推理混合负载”或关键核心业务。
关于多卡训练与 NVLink 的补充提醒
在大模型训练场景中,多卡互联能力同样至关重要。NVIDIA 的 NVLink 技术主要存在于 H100、H200、A100 等数据中心级 GPU 上,而 L40S、A6000 等专业卡并不支持 NVLink,因此并不适合复杂的大规模多卡训练任务,更推荐用于单卡训练或推理场景。
综合建议
- 如果你的核心需求是超大模型训练,并且预算充足,H200 / H100 依然是最稳妥的选择。
- 如果你更关注显存容量、推理密度和整体性价比,MI300X / MI325X 是当前非常有竞争力的方案。
- 如果主要目标是推理部署或生成式 AI 应用落地,L40S、A6000 在性能与成本之间提供了良好的平衡。
最后需要强调的是,GPU 选型不能只看理论性能指标,还需要结合成本、部署灵活性以及实际业务需求。相比自购 GPU 搭建服务器,使用云 GPU 服务可以显著降低前期投入,并快速获得多种 GPU 型号进行验证和扩展。像 DigitalOcean 这样的 GPU 云平台,已经覆盖了 H200、H100、MI300X、MI325X 等主流型号,为不同规模的 AI 团队提供了更灵活的选择空间。
大家可以参考 DigitalOcean GPU 云服务器定价来看,DigitalOcean 部分型号既提供单卡也提供 8卡的配置。以下我们可以先参考DigitalOcean云平台上单卡GPU 按需实例的价格:
| GPU服务器型号 | GPU显存 (GB) | vCPUs | CPU RAM (GB) | 价格 (美元/每小时/GPU) |
|---|---|---|---|---|
| MI300X | 192 GB | 20 | 240 GiB | $1.99/GPU/小时 |
| H200 | 141 GB | 24 | 240 GiB | $3.44 /GPU/小时 |
| H100 | 80 GB | 20 | 250 GB | $3.39/GPU/小时 |
| RTX 6000 Ada | 48 GB | 8 | 64 GB | $1.57/GPU/小时 |
| RTX 4000 Ada | 20 GB | 8 | 32 GB | $0.76/GPU/小时 |
| L40S | 48 GB | 8 | 64 GB | $1.57/GPU/小时 |
| P4000 | 8 GB | 8 | 30 GB | $0.51/GPU/小时 |
| P5000 | 16 GB | 8 | 30 GB | $0.78/GPU/小时 |
| P6000 | 24 GB | 8 | 30 GB | $1.10/GPU/小时 |
| RTX4000 | 8 GB | 8 | 30 GB | $0.56/GPU/小时 |
| RTX5000 | 16 GB | 8 | 30 GB | $0.82/GPU/小时 |
| A4000 | 16 GB | 8 | 45 GB | $0.76/GPU/小时 |
| A5000 | 24 GB | 8 | 45 GB | $1.38/GPU/小时 |
| A6000 | 48 GB | 8 | 45 GB | $1.89/GPU/小时 |
| V100 | 16 GB | 8 | 30 GB | $2.30/GPU/小时 |
| V100-32G | 32 GB | 8 | 30 GB | $2.30/GPU/小时 |
| A100 | 40 GB | 12 | 90 GB | $3.09/GPU/小时 |
| A100-80G | 80 GB | 12 | 90 GB | $3.18/GPU/小时 |
DigitalOcean GPU 云服务是专注 AI 模型训练的云 GPU 服务器租用平台,提供了包括 H200、H100、MI325X、MI300X等强大的 GPU 实例,以及透明的定价,可以比其他公共云节省高达70%的计算成本。其中,DigitalOcean 的 MI325X GPU云服务器目前只提供预留实例,暂无按需实例,12个月预留合约价格为$1.69/GPU/小时。
另外,DigitalOcean 云平台还将在2026年年初上线基于 NVIDIA B300 GPU的服务器。如果你感兴趣,希望了解更多,可以联系卓普云。
参考资料:
- https://www.digitalocean.com/pricing/gpu-droplets
- https://docs.digitalocean.com/products/droplets/details/features/#gpu-droplets
- https://verda.com/blog/nvidia-b300-vs-b200-complete-gpu-comparison-to-date#performance-numbers-without-sparsity
- https://www.techpowerup.com/gpu-specs/b300.c4375
- https://www.techpowerup.com/327553/amd-launches-instinct-mi325x-accelerator-for-ai-workloads-256-gb-hbm3e-memory-and-2-6-petaflops-fp8-compute
- https://getdeploying.com/gpus/amd-mi300x-vs-nvidia-rtx-3050
- https://blog.aidroplet.com/news/DigitalOcean-AMD-GPUs-Delivers-2X-Performance-for-Character/


