
在前不久,阿里通义千问发布了一系列 Qwen 模型。其中,Qwen3-Coder 是一个智能体 (agentic) 的专家混合(Mixture of Experts, MoE) 模型,拥有 4050 亿总参数和 350 亿激活参数。它专为高性能编程辅助和多轮工具使用而设计。从 Kimi-K2 到 Qwen3-Coder,这两款模型在不到两周的时间内相继发布,这表明各团队正在积极地将专门的开源智能体编程模型推向开发者。Qwen3-Coder 的独特之处在于其较低的总参数量(例如,比 Kimi K2 的 1 万亿参数少)和令人印象深刻的基准测试表现。
Qwen3于今年五月发布,在其技术报告的结论中提到:“我们将致力于改进模型架构和训练方法,以实现有效的压缩、扩展至极长上下文等目的。此外,我们计划增加用于强化学习的计算资源,特别关注从环境反馈中学习的基于智能体的强化学习系统。”
七月发布的更新版Qwen3模型涉及预训练和强化学习(RL)阶段,它使用了修改版的群组 相对策略优化(Group Relative Policy Optimization , GRPO) ,称为群组序列策略优化(Group Sequence Policy Optimization, GSPO) ,以及一个可扩展的系统,能够并行运行 2 万个独立环境。
Qwen3 的部分特点:
- 4050 亿参数的专家混合模型,其中 350 亿为激活参数
- 160 个专家,每个 token 激活 8 个
- 25.6 万 token 的上下文长度,使用 YaRN 可扩展到 100 万
- 在长程任务上 SWE-bench 验证得分很高(在 500 轮中得分为 69.6%,而 Claude-Sonnet-4 在 500 轮中为 70.4%)
- 使用群组序列策略优化进行训练
- 较小的 30B A3B Instruct 变体可在单个 H100 GPU 上运行
- 通义千问 Code CLI 作为 Gemini CLI 的分支开源
接下来,我们快速了解一下 Qwen3-Coder 内部结构,然后动手部署,让Qwen3 Coder跑起来。
模型概述
- 专家混合(MoE) :MoE 架构可以在增加模型规模和质量的同时降低计算成本。它采用稀疏的前馈神经网络(FFN)层(称为“专家”),并辅以一个门控机制,将 token 路由到 top-k 个专家,从而只激活每个 token 的一部分参数。
- 4050 亿总参数,350 亿激活参数:由于 Qwen3-Coder 采用 MoE 架构,因此存在总参数和激活参数。“总参数”包含模型内的所有参数总和,包括所有专家网络、路由器或门控网络以及共享组件,无论在推理过程中哪些专家被调用。这与“激活参数”不同,后者是指用于特定输入的参数子集,通常包括被激活的专家和共享组件。
- 专家数量 = 160,激活专家数量 = 8:这非常有趣,因为(点击链接)……
- 上下文长度 = 25.6 万 token(原生),使用 YaRN 达到 100 万:YaRN(Yet another RoPE extensioN method) 是一种计算高效的方法,用于扩展基于 Transformer 的语言模型的上下文窗口。它在 Qwen3-Coder 中的使用将其上下文长度扩展到了 100 万。
- GSPO( 群组 序列策略优化) :在通义千问的最新论文中,他们介绍了 GSPO,结果表明其训练效率和性能优于 GRPO(群组相对策略优化)。GSPO 稳定了 MoE 强化学习的训练,并有可能简化强化学习基础设施的设计。
- 在基准测试中,Qwen3-Coder 的表现令人印象深刻,其在 SWE-bench 验证上的得分为 67.0%,在 500 轮后增加到 69.6%。500 轮的结果模拟了更真实的编程工作流——模型可以读取反馈(如测试失败),修改代码,重新运行测试,并重复此过程直到解决方案生效。
部署运行Qwen3
接下来,我们采用一个较小变体 Qwen3-Coder-30B-A3B-Instruct ,来进行部署。从这个变体的名称,我们可以了解到,它的总参数为 300 亿,激活参数为 30 亿。instruct 表示它是基础模型的指令微调版本。它具体特性是这样的:
- 参数数量:305 亿总参数,33 亿激活参数
- 层数:48
- 注意力头数(GQA) :Q 为 32,KV 为 4
- 专家和激活专家数量:128 个专家,8 个激活专家
- 上下文长度:262,144 个原生上下文(不使用 YaRN)
正如我们所见,这个特定模型的规格略有不同,但可以在单个 H100 GPU 上运行。
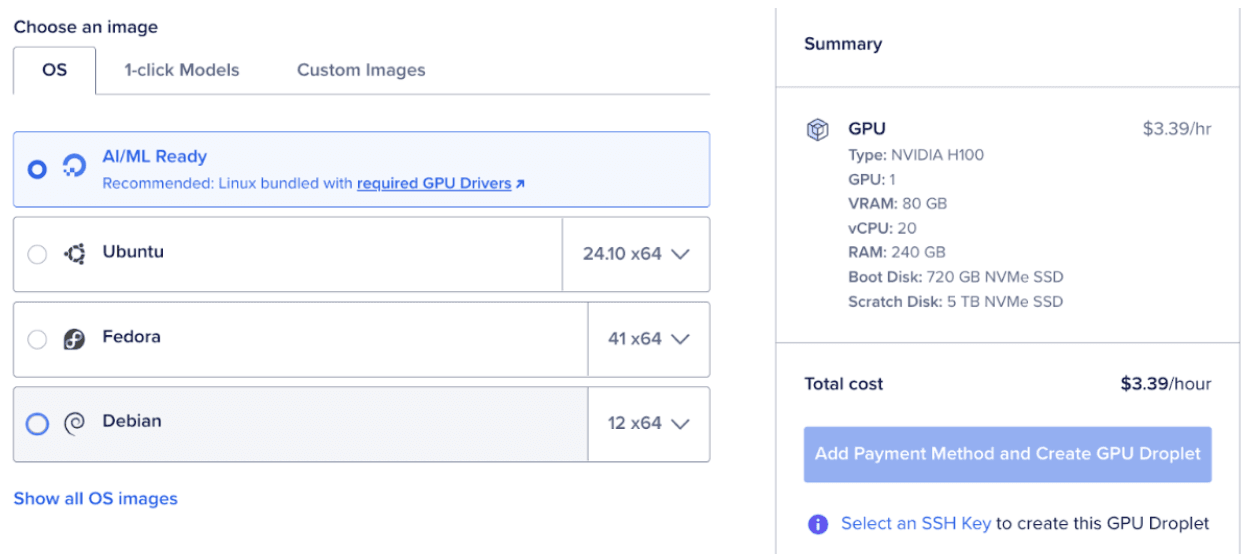
第 1 步:设置 GPU Droplet
首先设置一个 DigitalOcean GPU Droplet,选择 AI / ML 并选择 NVIDIA H100 选项。这里我们采用的是DigitalOcean 云平台的 GPU 服务器。目前在市场上,DigitalOcean 相对于其它大型云平台来讲,不仅 GPU 型号更加丰富,而且价格也相对更实惠。而且,DigitalOcean 云平台的产品更加简单易用。
运行 Qwen3-Coder-30B-A3B-Instruct 需要 80 GB 显存,所以你也可以选择 DigitalOcean 上的 A100 GPU。
另外,Qwen3 系列的旗舰版本Qwen3-235B-A22B,需要多卡并行才能完整运行,例如2-3张H100或1-2张H200显卡,如果你需要运行期间版本,那么也可以使用 DigitalOcean 上的H200 GPU,这些GPU都支持按需实例或裸金属服务器,详情可咨询 DigitalOcean 中国区独家战略合作伙伴卓普云aidroplet.com。
第 2 步:Web 控制台
GPU Droplet 加载完成后,你将能够打开 Web 控制台。

第 3 步:安装依赖
apt install python3-pip
pip3 install transformers>=4.51.0
第 4 步:运行模型
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-30B-A3B-Instruct"# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
通义千问 Code:开源CLI
通义千问 Code 是一个用于处理 Qwen3-Coder 模型智能体编程任务的开源命令行界面。它是 Gemini CLI 的一个分支,经过修改以与通义千问的能力无缝协作。
我们提供了安装 CLI、配置和使用 Qwen3-Coder 模型运行它的步骤。
第 1 步:安装 Node.js(20 或更高版本)
开始之前,请确保你的设备上安装了 Node.js 20+。
在你的终端中运行:
node -v
第 2 步:安装通义千问 Code CLI
Node.js 准备好后,全局安装通义千问 Code:
npm install -g qwen-code
这使得 qwen-code 命令可以在你系统的任何位置使用。
第 3 步:获取 API 密钥
从 openAI 获取一个 API 密钥。
export OPENAI_API_KEY="your_api_key_here"export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1 "export OPENAI_MODEL="qwen3-coder-plus"
第 4 步:Vibe Code
在终端中输入 qwen,你就可以开始编程了。
 对于使用 Qwen3-Coder 的其他方式,请查看通义千问 Coder 的博客文章。
对于使用 Qwen3-Coder 的其他方式,请查看通义千问 Coder 的博客文章。
最后思考
我们很高兴看到社区成员们玩转这些开源的智能体编程模型,如 Qwen3-Coder、Kimi K2、Devstral,并将它们整合到自己的工作流中。Qwen3-Coder 最令我们印象深刻的是其上下文窗口。它原生支持 25.6 万 token,并可扩展到 100 万,我们很期待看到该模型在实际软件工程用例中与其它开源模型相比有多有效。凭借其令人印象深刻的上下文窗口、可通过 Qwen3-Coder-30B-A3B-Instruct 访问的较小变体,以及通义千问 Code CLI 的推出,该模型有望为开发者提供强大的智能体编程辅助。
另外,你在DigitalOcean上,还可以通过“1-click model” 一键部署其他开源模型。如果你需要进一步了解DigitalOcean 上的 GPU或AI相关产品,可以咨询 DigitalOcean 中国区独家战略合作伙伴卓普云aidroplet.com。
相关产品与选型


