
大语言模型(LLM)在推理能力方面正在迅速进步,但长上下文推理仍然是最棘手的挑战之一。尽管预训练已经将上下文窗口扩展到数十万 token,真正面向超大文档的后训练推理技术仍然相当不成熟。
阿里通义实验室发布的 QwenLong-L1.5 正是为了解决这一空白,提出了一套完整的后训练方案,结合了:
- 长上下文数据合成
- 面向超长序列设计的强化学习
- 一个超越模型物理上下文窗口的内存管理框架
在本文中,我们将探讨:
- QwenLong-L1.5 有哪些与众不同之处
- 它的“记忆增强推理”架构
- 如何在 DigitalOcean GPU Droplet 上运行 QwenLong-L1.5
- 面向长上下文任务的实用推理代码
什么是 QwenLong-L1.5?
QwenLong-L1.5 是一个基于 Qwen3-30B-A3B-Thinking 构建的长上下文推理模型。它通过先进的后训练技术,对基础模型进行了扩展,使其能够在远超 256K token 的超大文档上进行推理,支持跨全局分布信息的多跳推理,并在极长输入序列下依然保持稳定的训练过程。
为什么长上下文后训练如此重要
大多数大语言模型失败,并不是因为缺少信息,而是因为它们:
- 无法持续跟踪早期事实
- 难以完成多跳推理
- 在长序列强化学习中出现梯度崩塌
QwenLong-L1.5 的核心创新
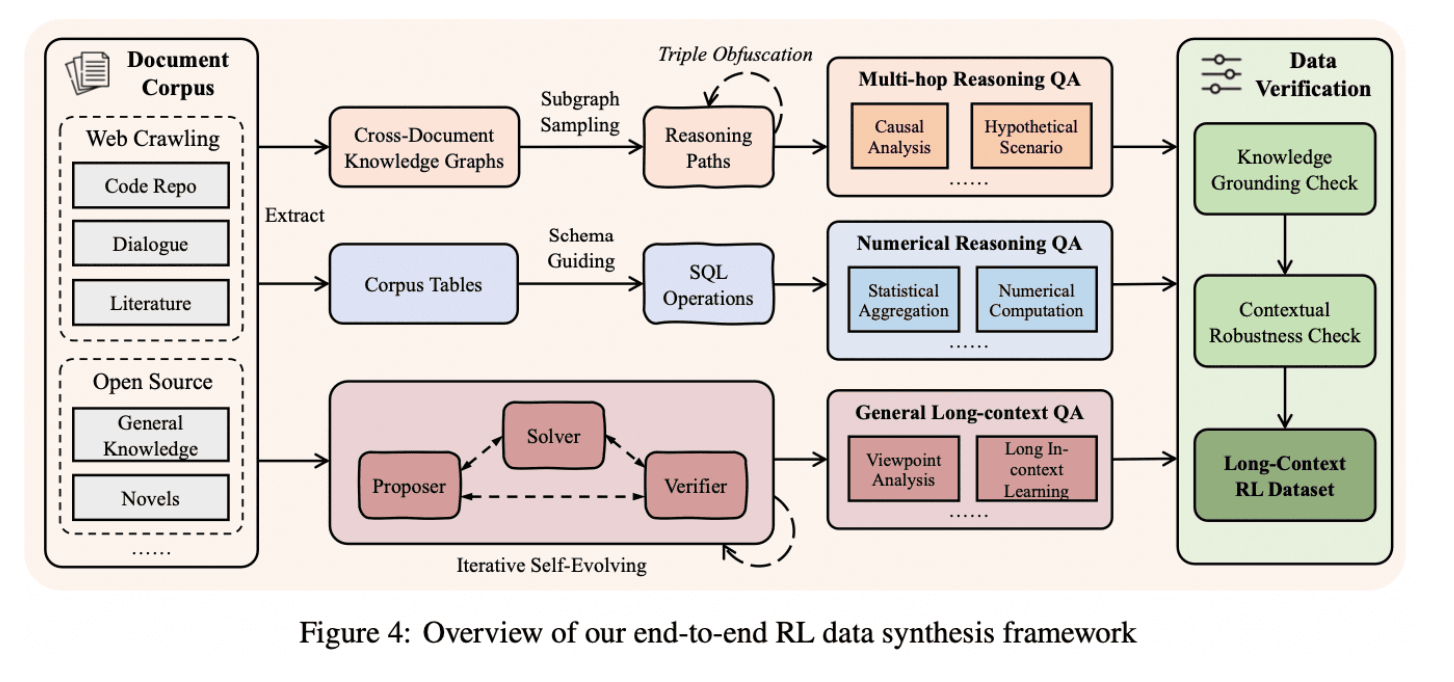
长上下文数据合成流水线
QwenLong-L1.5 通过三项关键改进提升了长上下文推理能力:
首先,它不再使用简单的“找一个事实”式训练任务,而是将文档拆解为细粒度事实单元,并构造需要模型跨越多个文本片段进行信息关联的问题,从而生成更智能、更贴近真实场景的训练数据。
其次,它引入了专门为超长输入设计的强化学习方法,以保证训练过程的稳定性,其中包括一种名为 AEPO 的技术,用于在文本长度不断增加时精细控制模型的学习方式。
最后,针对单次可读内容超过模型上下文窗口的场景,QwenLong-L1.5 增加了一套记忆系统,使模型能够在多个推理步骤中对关键信息进行总结、存储和复用,从而即使在超出原生上下文长度的情况下,仍能保持有效推理。
自适应熵控制策略优化
在长序列上进行训练会导致传统强化学习中的策略崩塌问题。QwenLong-L1.5 引入了 AEPO,其主要作用包括:
- 动态调整熵约束
- 防止梯度爆炸
- 支持在不断增长的序列长度上进行课程式学习
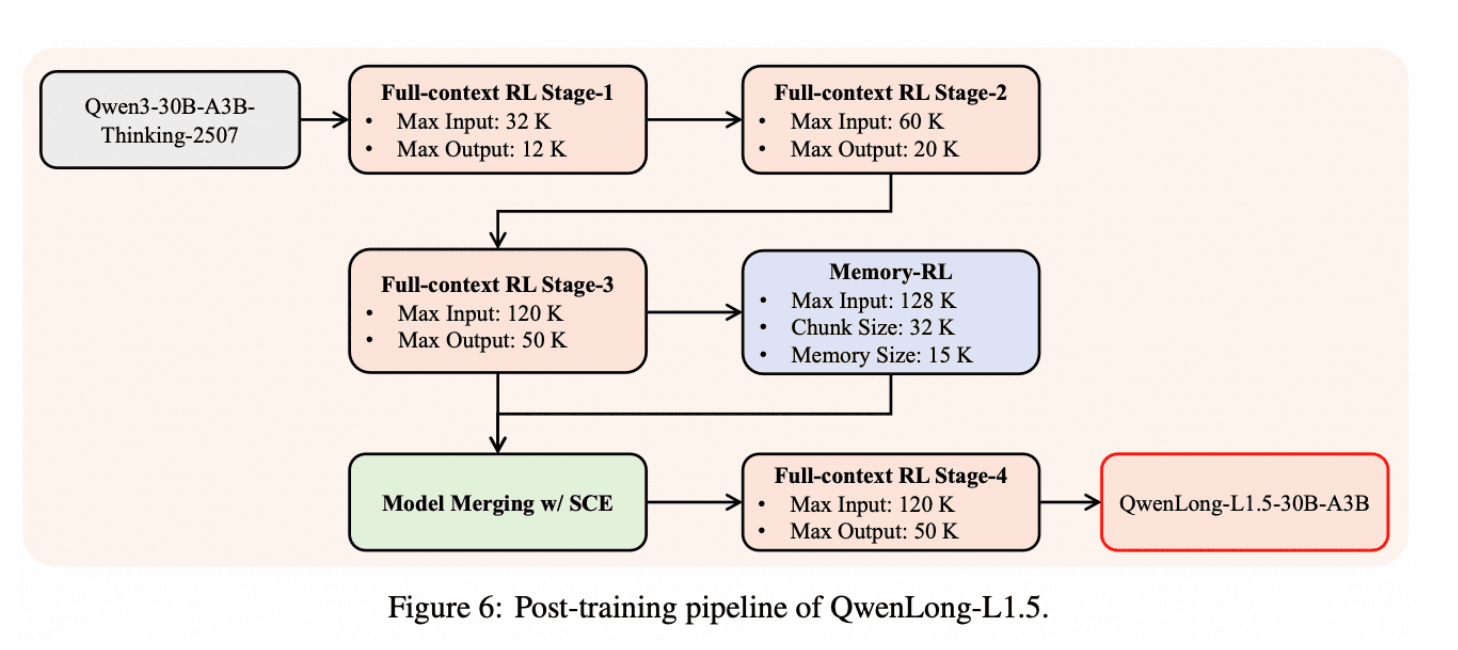
超越上下文窗口的内存管理
QwenLong-L1.5 提出了一种多阶段记忆融合框架,使模型能够对远超其原生 256K token 上下文窗口的信息进行推理。
在第一阶段,模型会在可用上下文内对大段文本进行一次性推理,提取关键信号和中间推理结果。随后,这些重要信息会被总结并压缩为结构化的记忆表示,在保留核心事实的同时去除冗余内容。
在第二阶段,模型在处理文档的新片段时,会不断迭代更新这份记忆,使先前获得的信息得以逐步细化、扩展或修正。
在最后阶段,通过一种基于融合的强化学习方法,将模型的推理过程与记忆更新过程对齐,确保存储下来的记忆真正服务于推理任务,而不会发生漂移或失效。
通过上述多阶段流程,QwenLong-L1.5 能够读取海量文档流,在长时间跨度内保持上下文一致性,并执行多步、循环式的推理过程——这些都是单一上下文窗口内无法完成的任务。
QwenLong-L1.5 的性能表现
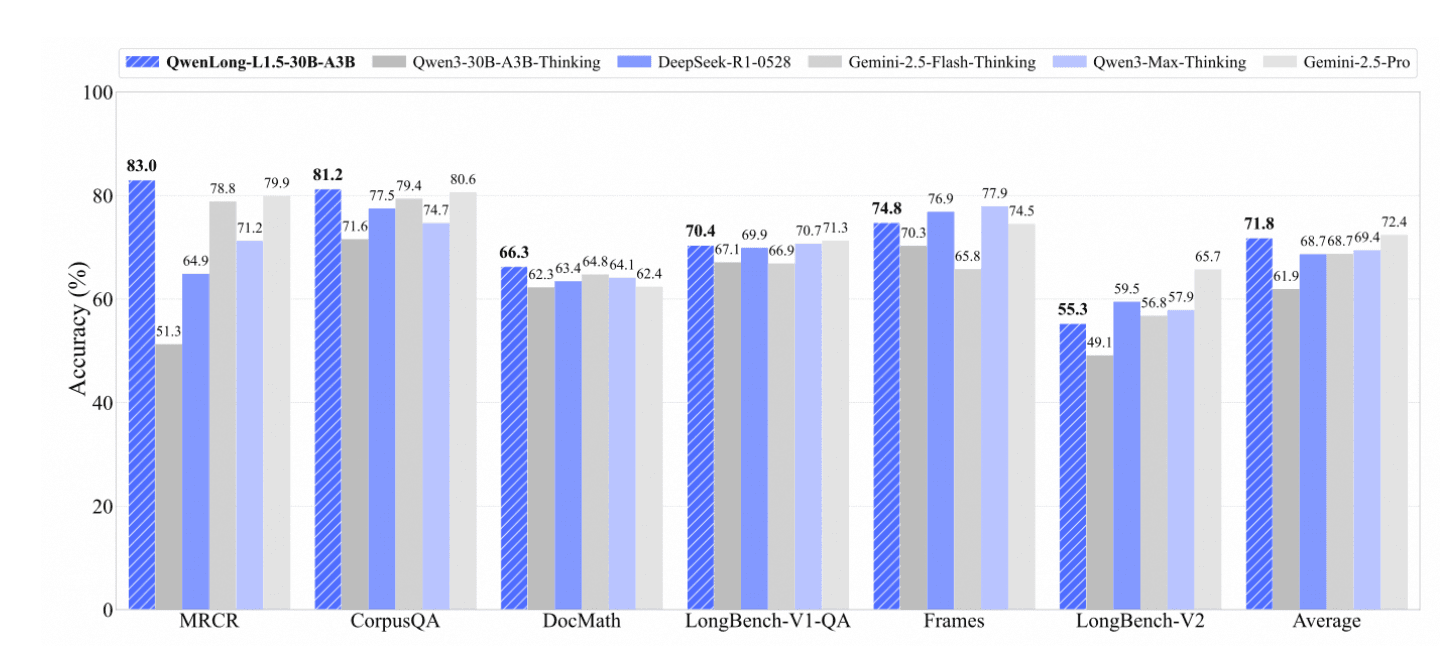
该基准测试结果显示,QwenLong-L1.5-30B-A3B 在各项评测中持续优于其基础模型 Qwen3-30B-A3B-Thinking,并且在整体表现上可与 Gemini-2.5-Pro、Gemini-2.5-Flash-Thinking、DeepSeek-R1 以及 Qwen3-Max-Thinking 等领先的长上下文模型相媲美。
在多文档阅读理解(MRCR)、CorpusQA、文档级数学推理(DocMath)以及 LongBench 等多种长上下文任务上,QwenLong-L1.5 都展现了稳定而全面的性能优势。尤其在 LongBench-V1、Frames、LongBench-V2 等强调推理能力与记忆容量的基准测试中,该模型取得了显著提升,整体平均准确率达到最高或接近最高水平。
这些结果表明,QwenLong-L1.5 的后训练策略与记忆融合框架带来的改进,能够在真实世界的长上下文推理任务中稳定发挥作用,而不是仅仅在某一个特定基准上“刷分”。
为什么要在 DigitalOcean GPU 上运行 QwenLong-L1.5?
DigitalOcean 的 GPU Droplet 非常适合长上下文推理场景,因为它们提供:
- 高显存的 NVIDIA GPU,如 H100、H200,以及即将上市的 B300 GPU
- 可预测、透明的定价,DigitalOcean 比 AWS、GCP 更便宜和透明
- 高效、无负担的 GPU 初始化体验,支持一键部署多种开源大模型
- 完整的 SSH 与 CUDA 控制能力
推荐部署 QwenLong-L1.5 的 GPU 配置:
- 普通推理:A100 / H100
- 长上下文推理:H100(推荐)
第一步:创建 DigitalOcean GPU Droplet
首先在 DigitalOcean 上创建一个 GPU Droplet,为模型运行提供所需算力资源。
选择:
- 镜像:Ubuntu 22.04
- GPU:H100 或 A100
- 显存:80GB(长上下文任务非常消耗显存)
第二步:环境配置
通过安装所需的驱动程序、库和依赖项来配置系统环境,确保您的 GPU Droplet 已准备就绪
# 更新系统
sudo apt update && sudo apt upgrade -y
# 安装 Python 工具
sudo apt install -y python3-pip git
# 创建虚拟环境
python3 -m venv .venv
source .venv/bin/activate
第三步:安装依赖
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
验证安装
python - <<EOF
import torch
print("Torch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
EOF
第四步:登录 Hugging Face
通过 Hugging Face 进行身份验证,以访问下载和运行预训练模型所需的模型、数据集及访问 token。
pip install -U huggingface_hub
hf auth login
在提示时粘贴你的 Hugging Face Access Token
(生成路径:Hugging Face → Settings → Access Tokens)
第五步:在 DigitalOcean GPU 上下载 QwenLong-L1.5
hf download Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B
第六步:安装 verl
# 安装 verl,这里使用 0.4 版本
git clone --branch v0.4 https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
第七步:开始使用模型
加载 QwenLong-L1.5 模型,开始进行推理或实验。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
使用 device_map="auto" 让权重在 GPU 显存中自动高效分配。
第八步:长上下文推理示例
运行推理任务,输入长序列文本,可以看到 QwenLong-L1.5 在长上下文处理和多跳推理方面的表现。我们可以做很多事情,我们简单举个例子。
下载一部长篇小说
import requests
url = "https://www.gutenberg.org/files/1342/1342-0.txt"
output_file = "novel.txt"
response = requests.get(url)
response.raise_for_status()
with open(output_file, "w", encoding="utf-8") as f:
f.write(response.text)
print("Novel downloaded successfully.")
把 URL 替换成你的数据来源即可。
加载并预处理文本(可选)
def load_novel(path):
with open(path, "r", encoding="utf-8") as f:
text = f.read()
start_marker = "*** START OF"
end_marker = "*** END OF"
if start_marker in text:
text = text.split(start_marker)[-1]
if end_marker in text:
text = text.split(end_marker)[0]
return text.strip()
novel_text = load_novel("novel.txt")
print(f"Novel length (characters): {len(novel_text)}")
构建长上下文 Prompt
question = (
"Who is the main protagonist of the novel, "
"and how does her personality evolve throughout the story?"
)
template = """
Please read the following novel and answer the question below.
<novel>
{novel}
</novel>
Question:
{question}
Format your response as:
"Therefore, the answer is (your answer here)"
"""
prompt = template.format(
novel=novel_text,
question=question
)
分词并运行推理
长上下文推理对 GPU 资源消耗较大,因此请确保您拥有充足的 GPU 显存。如果 H100 GPU Droplet 不够用,可以考虑替换成 DigitalOcean 云平台上的其它 GPU ,比如 H200、MI325 X 等。由于 GPU Droplet 的市场需求较大,如需了解实际的 GPU 剩余库存,可咨询 DigitalOcean 中国区独家战略合作伙伴卓普云 AI Droplet。
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(
[text],
return_tensors="pt"
).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=2000,
temperature=0.7,
top_p=0.95
)
提取推理过程与最终答案
output_ids = outputs[0][len(inputs.input_ids[0]):].tolist()
try:
# </think> 的 token id
end_think_idx = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
end_think_idx = 0
thinking = tokenizer.decode(
output_ids[:end_think_idx],
skip_special_tokens=True
).strip()
final_answer = tokenizer.decode(
output_ids[end_think_idx:],
skip_special_tokens=True
).strip()
print("Reasoning:\n", thinking)
print("\nAnswer:\n", final_answer)
如果小说内容大到连 256K token 也放不下,可以这样做:
- 将文本切分为多个块(如按章节)
- 依次输入模型
- 让 QwenLong-L1.5 在内部更新记忆
- 在处理完所有块后再提问
现实中已有的应用场景
QwenLong-L1.5 非常适合需要理解和推理海量信息的应用,例如:
- 评估冗长的法律或财务文件
- 总结与综合大量研究论文
- 构建需要在长时间交互中保持上下文的对话式智能体
它同样适用于企业级知识助手,将多个文档的数据整合后输出精确且具备上下文感知能力的答案,也适合需要跨多步骤监控指令与执行结果的工具型 AI Agent。
常见问题(FAQ)
什么是 QwenLong-L1.5? QwenLong-L1.5 是由阿里通义实验室开发的一款长上下文推理模型,基于 Qwen3-30B-A3B-Thinking 构建,并通过聚焦于记忆管理与强化学习的后训练技术进行增强。
QwenLong-L1.5 与标准大模型有何不同? 与在超长输入场景下表现吃力的传统大模型不同,QwenLong-L1.5 借助记忆框架与专门设计的训练策略,能够在超过其物理上下文窗口长度的文档上进行推理。
QwenLong-L1.5 的最大上下文长度是多少? 该模型原生上下文窗口为 256K token,但其内存管理框架使其能够有效处理远超这一上限的信息。
为什么要使用 DigitalOcean GPU 运行 QwenLong-L1.5?DigitalOcean GPU Droplet 提供高性能 GPU、可预测的定价以及便捷的部署流程,非常适合在生产或研究环境中运行像 QwenLong-L1.5 这样的大模型。
QwenLong-L1.5 是否也适用于通用推理任务? 是的。长上下文能力的提升也会带来在数学、工具调用以及长对话等通用领域的整体性能提升。
写在最后
QwenLong-L1.5 所展现的强大长上下文推理能力,并不仅取决于上下文窗口的大小,更依赖于模型在“如何推理、如何保留信息以及如何随时间更新信息”方面的训练方式。通过结合结构化数据合成、专门面向长序列的强化学习技术以及多阶段内存管理框架,QwenLong-L1.5 能够胜任涉及超大文档与长时间交互的复杂任务。
当部署在 DigitalOcean GPU Droplet 上时,它可以成为文档分析、研究综述与企业知识助手等实际场景中可行且可扩展的解决方案。总体来看,QwenLong-L1.5 提供了一种强大而透明的长上下文推理方法,在生产环境中兼具出色性能与良好实用性。


