自诞生以来,图像生成一直是 AI 最受欢迎的用例之一,正如我们在本博客中广泛介绍的那样。从像 Flux 和 Hi-Dream 这样的模型中,我们看到了大量资源投入到微调的开发中,由此产生的艺术作品令人惊叹。文生图模型(text-to-image models)能做的事情实在太多了——它让任何人都有可能将想象变为现实。
但这些模型并非完美无缺。通常,一张本应完美的图像会被一些微小的瑕疵或错误破坏。例如,图像模型曾经有一个臭名昭著的弱点,那就是在处理四肢,尤其是手部时会遇到困难,这使得在野外很容易识别出 AI 生成的图像。虽然现在这个问题在较新的模型中已基本得到修复,但修复这些小错误的需求仍然存在。要做到这一点,通常需要具备使用 Photoshop 或 GIMP 等照片编辑软件的技能。这就是新的图像生成模型(image editing models)发挥作用的地方。
什么是图像生成模型
图像生成模型是一种 文生图/图生图(text-to-image/image-to-image) 模型,它接收文本输入指令,对现有图像进行更改。这些更改可以是微小的,比如给一个人加上胡须;也可以是巨大的,比如改变照片的整个风格。这让任何用户都能根据需要修正他们的 AI 生成图像。
在本次评测中,我们将探讨一些现有最佳的开源(open source) 和 闭源(closed source) 图像编辑工具,并尝试从定性和定量角度评估它们之间的差异,讨论它们的优缺点,并简要展示它们的使用方法。
如何评估模型的能力?
为了评估这些模型,我们将运行一系列图像编辑测试,以定性评估它们的能力。这些测试包括使用相同的图像和提示指令,对图像进行全面的编辑和更改。然后,我们将查看输出,并给出我们对模型表现的主观评价。
OmniGen2 & UMO
我们想介绍的第一个图像生成模型是来自 OmniGen 研究团队的 OmniGen2,以及它随后在字节跳动的 统一多身份优化框架(Unified Multi-identity Optimization framework) UMO 中的应用。OmniGen2 是这类模型中第一个开源的模型,它的功能比我们今天将要介绍的其他模型更为有限。尽管如此,OmniGen2 在指令引导的图像编辑(Instruction-guided Image Editing)(通过文本输入编辑图像)和上下文内生成(In-Context generation)(灵活处理和组合包括人物、参考物体和场景在内的多样化输入,以产生新颖且连贯的视觉输出)方面展现出强大的能力。OmniGen2 具有两条用于文本和图像模态的不同解码路径,利用不共享的参数和一个解耦的图像分词器。与他们之前的作品 OmniGen 1 相比,这种流程使其性能得到了大幅提升。
UMO 由字节跳动研究人员开发,旨在提升现有图像生成模型的能力,并已应用于包括其自有的 UNO 在内的多个模型。OmniGen2 UMO 全面提高了 OmniGen2 的实用性。大量实验表明,UMO 不仅显著改善了身份一致性(identity consistency),还减少了几种图像定制方法中的身份混淆,在身份保持(identity preserving)维度上,在当时树立了开源方法的新标杆。我们始终建议使用 UMO 而不是单独使用 OmniGen2,因此在本次评测中我们将测试 UMO OmniGen2。
Flux Kontext
Flux Kontext 是下一个开源的图像生成模型套件。来自 Black Forest Labs 的这些模型一经发布就引起了轰动,许多用户通过它们的工具和平台首次接触到图像生成模型。这些模型分为三种形式:Max、Pro 和 dev。
FLUX.1 Kontext [dev] 是一个 120 亿参数的整流流(rectified flow)Transformer,能够根据文本指令编辑图像。“该模型支持迭代编辑,擅长在各种场景和环境中保留角色特征,并允许进行精确的局部和全局编辑。”(来源)在实践中,它是一个令人难以置信的图像编辑工具,仅需文本提示即可进行复杂的编辑。
Qwen Image Edit & Qwen Image Edit 2509
Qwen Image Edit 建立在扩散(diffusion-based)图像编辑方法已取得的进展之上,这些方法开创了结合语义和外观控制以实现更灵活编辑工作流程的做法。200 亿参数的 Qwen-Image 基础模型将其独特的文本渲染精度带入了编辑领域。
为此,Qwen-Image-Edit 同时将输入图像导向 Qwen2.5-VL(用于语义基础)和 VAE 编码器(用于外观一致性),实现了平衡意义与风格的高保真编辑。这种与现有研究传统的对齐确保了 Qwen Image Edit 继承了先前创新的优势,同时在精确的文本和图像操作中提供了更强的结果。
Qwen Image Edit 2509 是该模型的更新版本,在所有可辨别的方面都超越了 Qwen Image Edit 的能力。我们始终建议使用 2509 而非原版,并且将在本次评测中对其进行测试。值得注意的是,Qwen Image Edit 2509 在多图像编辑(Multi-Image editing)方面得到了特别改进,允许用户同时提交多张图像进行编辑。
Gemini Flash 2.5,又名 Nano Banana
Gemini 2.5 Flash 的图像编辑能力,代号 Nano Banana,是本次评测的对照组。Nano Banana 是一款在所有任务和指标上都表现出色并主导图像生成模型排行榜的图像生成模型。不仅如此,它运行在 Google 的云平台上,这使我们能够利用他们最前沿的工作成果。
最终,这款闭源模型可以说是继 Photoshop 之后有史以来最强大的图像编辑工具。因此,我们将其用作与其他所有模型进行比较的基准。我们预期 Nano Banana 将在各个方面超越开源竞争对手,并很好地充当良好模型行为的标杆。
定性评估图像生成模型
现在我们进入本文的评测部分。在本节中,我们将尝试定性评估所选模型的性能。为了便于评估,我们使用在 DigitalOcean 云平台的 H100x8 GPU Droplet 服务器上运行的 Hunyuan Image 3.0 生成了 5 张图像。所有图像均以 50 步、1024x1024 的分辨率和随机种子生成。然后,我们将使用每个图像生成模型对 5 张生成的图像分别应用 5 种图像操作。这将为每个模型生成 5 个具有相同图像编辑提示的示例,以便进行比较。
提示词
首先,我们创建了 4 个提示词来生成在体裁、主题、真实感、艺术风格、内容和主题方面高度多样化的图像。这些提示词是我们自己想出来的,参考了一些前人的作品和 Hunyuan Image 3.0 的技术报告,然后使用 Hunyuan Image 2.1 的提示词增强功能进行了优化。这些增强后的提示词如下:

1: “一张手绘宣传海报,描绘了一位探险家在一个外星球上,背景是一个充满活力和奇异的丛林。中心人物是一位探险家,他身着笨重的复古未来主义太空服,特点是银色调、有衬垫的织物和突出的波纹管。他戴着一个巨大的球形玻璃头盔,露出了他坚定的表情。在一只戴手套的手中,他握着一把射线枪,这是一种带有金属枪管和可见屏幕的工具,暗示着扫描或防御的功能。探险家站在占据中景的茂密外星丛林中。丛林里充满了高大细长的树木,树干呈深紫色,树冠上覆盖着厚厚的、旋转的粉色藤蔓。地面上不时地突起着大型、锯齿状的橙色晶体结构,散发着微弱的内部光芒。在远方,可以看到古老、破旧的废墟的轮廓,被藤蔓严重覆盖,散落着碎片。海报底部的华丽手写标题以大胆、程式化的字体拼写着“探索 Rigel-4!”。这件艺术品以 20 世纪中期手绘宣传海报的风格呈现,让人联想到经典的罗克韦尔插画。”
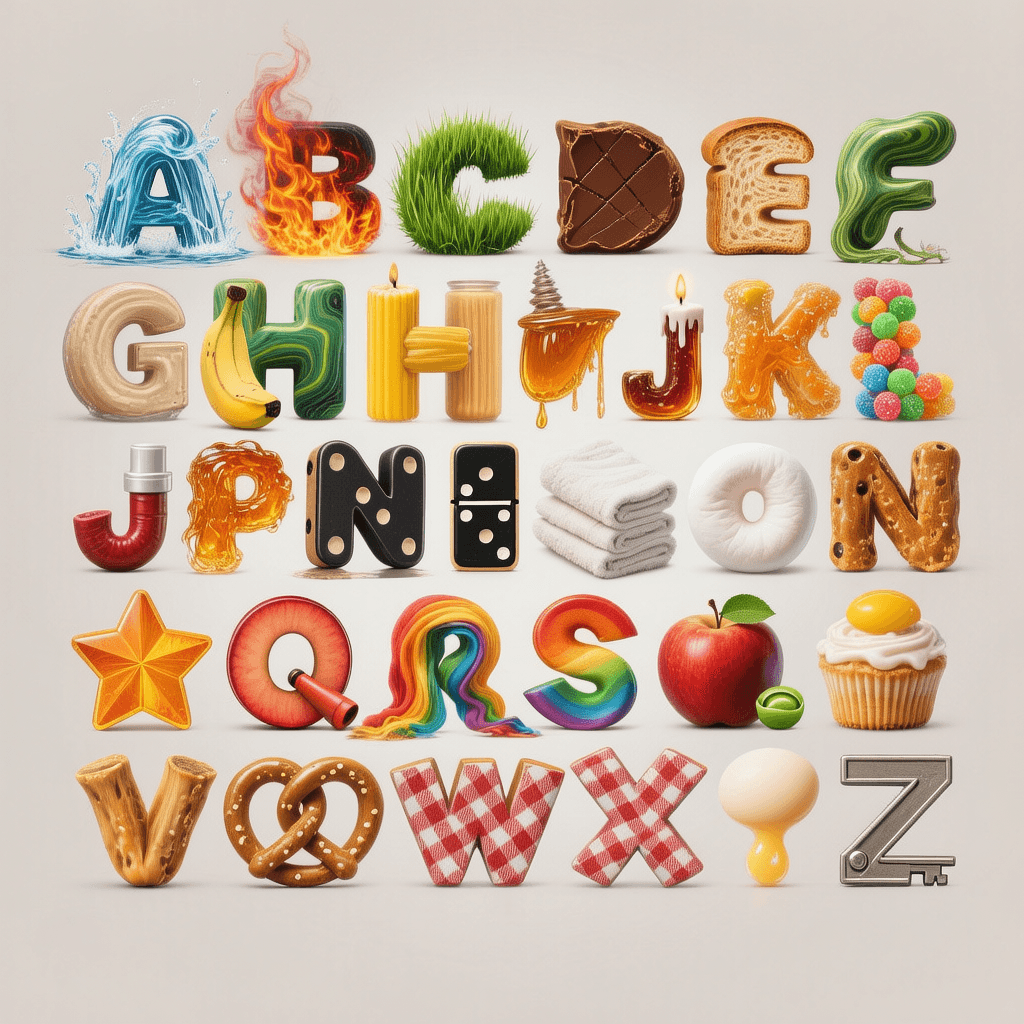
2: “一个宏大的字母拼图呈现在一个普通的、中性的背景上,A 到 Z 的字母按标准顺序水平排列。每个字母都被巧妙地替换成一个在视觉上代表其相应发音的物体,并以独特、鲜明的风格渲染。字母 “A” 被描绘成动态流动的水,半透明的蓝色水流形成了它的形状,在尖端带有白色泡沫,凝固在运动中。紧随“A”的是 “B”,由咆哮的火焰表示,由充满活力的橙色和黄色火焰组成,向上闪烁,拖着深红色的烟雾。字母 “C” 由郁郁葱葱的绿草形成,可以清楚地看到和详细描绘出单独的草叶,暗示着一种锋利、清脆的切割。序列继续,“D” 是一块浓郁的棕色巧克力,表面光滑有光泽,有可见的刻痕。“E” 被描绘成一块新鲜切开的面包,显示出浅金黄色的面包皮和多孔、透气的面包屑。“F” 表现为一捆绿叶,上面有精致的叶脉。“G” 形状像一块大型的大理石纹绿色石头,有深绿色和浅绿色的漩涡图案。“H” 由一根亮黄色香蕉表示,直立放置,其棕色种子清晰地定义在其尖端。字母的中心部分继续,“I” 是一个高耸、细长的蜡烛在一个简单的玻璃罐中,其灯芯从内部点亮。“J” 是一系列彩色、圆形软糖的集合。“K” 由蜂蜜制成,呈现出滴落的、粘稠的金色琥珀色液体流。“L” 由一个单一、大型的红苹果形成,果皮光滑且反光。“M” 被描绘成一叠叠整齐折叠的、原始的白色毛巾。“N” 是一对黑色多米诺骨牌,它们的圆形形状由一条细而灵活的线连接。“O” 是一个完美的圆形、白色棉花糖,看起来柔软且略微可挤压。“P” 是一个经典的红白条纹纸管。“Q” 是一个单一、充满活力的橙色星星,中心为黄色。“R” 由一片红苹果切片和一颗小绿豌豆组成。“S” 是一条长而蜿蜒的彩虹色丝绸缎带。“T” 是一本标准的精装书,合上并显示深棕色封面。“U” 是一个简单的、金黄色纸杯蛋糕,白色糖霜沿着侧面滴落。“V” 是一个 V 形的切口框架,露出一块坚实的红色水果块。“W” 由四根直的棕色椒盐卷饼形成。“X” 是一块亮红白格纹布。“Y” 是一个单一、大型的淡黄色蛋黄。最后,“Z” 由一把直的、金属银色钥匙表示。整体呈现出一种干净、多彩、高度创意的数字插画风格。”

3: “场景设定在一个灯光明亮、超现代的餐厅内,一对男女坐在一张餐桌旁,定格在一个庆祝的瞬间。在前景中,这对男女紧挨着坐在一张圆形、深色木质桌子旁。穿着一套时髦深色西装的男人举起一个优雅的酒杯,酒杯的杯脚与他的同伴的酒杯相碰。穿着一件时尚丝绸衬衫的女人温暖地笑着,与他对视,并将自己的酒杯向前举起敬酒。桌子中央的一支高大的蜡烛在他们的脸上投射出温暖、闪烁的光芒,突显了喜庆的庆祝氛围。在背景中,透过宽阔的落地玻璃窗,可以看到一群小丑在抛光的混凝土地板上表演一段笨拙但非常滑稽的舞蹈。他们的动作被夸大,包括杂技式的翻转、笨拙的旋转和幽默的面部表情,在餐厅内部明亮的环境光下显得尤为突出。餐厅的环境是极简主义的,以其朴素的白墙和窗外表演的广阔、清晰视野为特色。此图像呈现出一种高质量、充满活力的摄影风格。”

4: “一只顽皮的卡通猴子被描绘成正在积极攀爬一棵大型、多节的树,这是受中国古代艺术启发的手稿的中心焦点。这只猴子有着浅棕色的皮毛,一条长长的、用于平衡的卷曲尾巴,以及一个以大大的、闪烁的眼睛和宽阔的笑容为特征的调皮表情。它的小手紧紧抓住树干有纹理的树皮,一条腿弯曲着,仿佛在匆忙攀爬中。这棵树本身是古老而健壮的,扭曲的树干以深色、富有表现力的书法线条描绘,粗细不一。它的树枝以粗笔触和更细的线条结合描绘细节,横跨构图,点缀着玉绿色和深祖母绿色调的程式化树叶。背景是一种柔和的、灰白色或浅羊皮纸般的纹理,暗示着陈旧的纸张,远处可见淡淡的、雾蒙蒙的群山,以淡雅、稀释的墨水渲染。整个构图以中国传统水墨水彩手稿的风格呈现,强调流畅的笔触和单色或有限的调色板。”
接下来,让我们讨论编辑提示的计划。为了有效工作,这些提示需要根据每张图片进行定制,因为许多编辑如果普遍应用就没有意义。因此,每组图像编辑的提示将专门为每张图片创建。这些提示将是多样化的,旨在涵盖多种类型的编辑,包括风格转换(Style Transfer)、物体修改(object modification)、物体添加(object addition)、物体减除(object subtraction)和主体操纵(subject manipulation)。我们将在下一节的每个示例下方列出编辑内容。
比较图像生成模型的能力
图像 1
我们的编辑提示如下:
- 让图像呈现梵高《星月夜》的风格
- 给这个男人加上小胡子
- 移除图像底部的文字和标志配色

正如我们在上图中所见,每个不同的模型似乎都在不同的领域表现出色。例如,在风格转换示例中,Qwen 和 Nano Banana 遥遥领先于其他模型。它们在直接将风格转移到图像上的同时,保留了原始图像。UMO 和 Flux Kontext 在保留原始图像的细微特征方面落后于其他模型,UMO 似乎甚至没有理解请求。
Nano Banana 和 Qwen 在任务 2 (添加胡子) 中再次表现出色。UMO 和 Kontext 似乎效果稍差,胡子在头盔外部可见。
对于提示 3,Nano Banana 是明显的佼佼者。Qwen 似乎没有理解需要移除标志背景,而 UMO 虽然理解了任务,但未能扩展背景特征。Kontext 和 Nano Banana 都成功地完成了任务,但我们更喜欢 Nano Banana 在移除标志和文字后添加的图像细节。
总体而言,Nano Banana 是这一系列任务中的佼佼者,但 Qwen 和 Kontext 在大多数场景中都相当不错。
图像 2
我们的编辑提示如下:
- 让图像看起来像是为日本动漫卡通制作的动画
- 从图像中移除燃烧的字母 B
- 将右下角的字母 Z 更改为数字符号“1”

正如我们在上图中所见,每个不同的模型似乎都在不同的领域表现出色。例如,在风格转换示例中,Qwen 和 Nano Banana 遥遥领先于其他模型。它们在直接将风格转移到图像上的同时,保留了原始图像。UMO 和 Flux Kontext 在保留原始图像的细微特征方面落后于其他模型,UMO 似乎甚至没有理解请求。
Nano Banana 和 Qwen 在任务 2 (添加胡子) 中再次表现出色。UMO 和 Kontext 似乎效果稍差,胡子在头盔外部可见。
对于提示 3,Nano Banana 是明显的佼佼者。Qwen 似乎没有理解需要移除标志背景,而 UMO 虽然理解了任务,但未能扩展背景特征。Kontext 和 Nano Banana 都成功地完成了任务,但我们更喜欢 Nano Banana 在移除标志和文字后添加的图像细节。
图像 3
我们的编辑提示如下:
- 让场景和角色看起来像是来自一个流行的美国卡通片,拥有黄皮肤角色
- 移除背景中的小丑
- 给前景中的男人添加戏剧性的悲伤小丑妆

查看提示 1,Qwen Image Edit 是明显的佼佼者。其他模型似乎理解了任务,但都未能达到结果。Nano Banana 对于卡通来说过于写实,而 UMO 似乎错过了它可以借鉴的无处不在的卡通示例,比如《辛普森一家》。在这里,唯一接近 Qwen 的模型是 Kontext,它似乎既理解了任务,又成功地进行了编辑。
对于提示 2,我们更喜欢 Qwen Image Edit 的结果。其他模型都成功地移除了背景物体,但它们没有像 Qwen 那样用逼真的替代物填充空间。替换后的桌子使它看起来更像一张真实的图像。
对于提示 3,Nano Banana 和 Qwen Image Edit 似乎更好地成功地进行了编辑。Nano Banana 在这里可能是赢家,因为它没有修改前景中女人的面部表情,不像 Qwen Image Edit。UMO 和 Kontext 确实正确地进行了编辑,但也对图像中的另一个主体进行了编辑。由于我们指定只编辑男人的特征,这些结果表明它们比 Qwen 和 Nano Banana 文本理解能力较弱。
图像 4
我们的编辑提示如下:
- 让场景变成用相机拍摄的写实照片
- 给猴子加上高礼帽、单片眼镜和华丽的西装
- 翻转猴子,让它倒挂着爬下树

最后我们来看图像 4 的第一个提示。对于这个例子,Qwen Image Edit 2509 再次遥遥领先于其他模型。它成功地、可信地完全改变了图像的风格。其他模型都没有做到,尽管 Flux Kontext 似乎至少理解了任务并尝试了。
对于提示 2,Qwen Image Edit 是赢家。添加到猴子身上的新衣服在 Qwen 的编辑结果中显得最逼真,也最忠实于提示,紧随其后的是 Nano Banana 的结果。Flux Kontext 做得不错,但给了猴子眼镜而不是单片眼镜。UMO 完全未能将猴子留在树上。
正如我们在提示 3 中看到的,Qwen 和 Nano Banana 的编辑显然优于其他模型。两者都成功地展示了猴子被转换到倒挂的位置。我们特别喜欢 Qwen 的示例,猴子现在挂在树枝上。对于 UMO,我们怀疑模型不理解该怎么做,只是选择了移除物体。对于 Flux Kontext,没有进行编辑。
总体结果
从这些结果来看,在我们主观看来,Qwen Image Edit 2509 是目前最好、最通用的图像编辑 AI 工具。它不仅能力最强,而且原生支持同时使用多张图像,这使其比本次评测中的其他模型更有价值。它还可以使用 AI-Toolkit 等工具进行微调,仅凭模型的可定制性在许多情况下就使其成为比 Nano Banana 更好的选择。我们推荐 Qwen Image Edit 2509 用于所有图像编辑任务。
现在就可以在 DigitalOcean Gradient GPU Droplet 上试用 Qwen Image Edit 2509 !我们也发布了相关的部署教程,可以访问卓普云官网博客阅读教程。如需了解GPU Droplet 服务器产品详情,可直接咨询DigitalOcean中国区独家战略合作伙伴卓普云。