
GPU计算已彻底改变了各个行业,推动了自动驾驶、机器人和分子生物学等领域的深度学习应用进步。这些机器提供的高速并行处理能力,能加速训练和推断深度学习模型所需的矩阵乘法计算。这些模型由多层相互连接的节点(神经网络)组成,需要处理和转换海量数据。
在AI研发中,更快、更便宜地训练神经网络和执行推断是首要任务。对于GPU 计算而言,这意味着需要更好地理解如何优化GPU性能。
核心要点
- GPU 优化对于更快的深度学习训练和高效的资源利用至关重要。
- 批量大小、混合精度和数据管道直接影响性能。
- CUDA、cuDNN和优化的框架有助于最大限度地发挥GPU潜力。
- 像NVIDIA Nsight Systems和PyTorch Profiler这样的分析工具可以帮助识别性能瓶颈。
- 内存 管理技术(如梯度检查点和模型 剪枝)能减轻GPU的负担。
- 使用多 GPU 和 分布式 训练进行扩展可以提高大型模型的效率。
熟悉以下内容将有助于理解本文所介绍的主题:
- 机器学习(ML)和深度学习基础知识(矩阵乘法、神经网络、Python、PyTorch)
- 数据类型(INT、FP等)
- 最新的NVIDIA GPU架构:Blackwell(已宣布,但尚未上市)、Hopper(2022)、Ampere(2020)
- CUDA和GPU内存层次结构
GPU优化入门:从了解硬件开始
这篇文章的目标是,让读者了解如何改进计算体验。建议那些热衷于优化GPU性能的人士,学习最新GPU架构的特性,了解GPU编程语言的现状,并熟悉NVIDIA Nsight和SMI等性能监控工具。通过反复试验、基准测试和迭代优化,才能更好地利用硬件。
利用NVIDIA GPU 的硬件特性
了解GPU架构的复杂性可以提升您对大规模 并行 处理器编程的直觉。NVIDIA在 successive GPU iterations中引入了许多专用硬件特性,以加速其并行处理能力。
核心加速单元:Tenso Cores
默认情况下,许多深度学习库(如PyTorch)使用单精度(FP32)进行训练。然而,单精度并非总是达到最佳精度的必要条件。较低的精度需要较少的内存,从而提高数据访问速度(内存带宽)。
Tensor Cores支持混合精度计算,即仅在必要时使用FP32,并使用在不影响精度的情况下最低精度的数据类型。目前,Tensor Cores有五代,第四代在Hopper架构中,第五代在Blackwell架构中。
| Tensor Core | 引入的数据类型 |
|---|---|
| Volta(第一代) | FP16, FP32 |
| Ampere(第三代) | 稀疏性, INT8, INT4, FP64, BF16, TF32 |
| Hopper(第四代) | FP8 |
| Blackwell(第五代) | FP4 |
上层加速库:Transformer Engine
Transformer Engine是一个库,支持Hopper GPU上的8位浮点(FP8)精度。Hopper GPU中引入FP8精度在不影响精度的情况下提高了性能。第二代Transformer Engine将出现在Blackwell架构中,支持FP4精度。
数据搬运助手:Tensor Memory Accelerator
Tensor Memory Accelerator(TMA)支持GPU全局内存和共享内存之间的异步内存传输。在TMA之前,需要多个线程和warp协同工作来复制数据。相比之下,有了TMA,线程块中的单个线程就可以发出TMA指令,从而异步处理复制操作。
GPU 是可编程的
思考一下:硬件设计会影响CUDA语言吗?还是CUDA语言推动了硬件设计?两者都对。硬件和软件之间的这种关系在2022年GTC演讲《How CUDA Programming Works》中得到了很好的阐述,Stephen Jones在其中解释道,CUDA语言的演变是为了让硬件的物理特性更具可编程性。
CUDA
CUDA(Compute Unified Device Architecture)是一个为配置GPU而设计的并行计算平台。CUDA支持C、C++、Fortran和Python等编程语言。
CUDA 库
CUDA之上构建了许多库,以扩展其功能。其中一些著名的包括:
- cuBLAS:一个GPU加速的基础线性代数(BLAS)库,能够加速低精度和混合精度的矩阵乘法。
- cuDNN(CUDA Deep Neural Network):一个提供DNN应用中常见操作实现的库,如卷积、注意力、矩阵乘法、池化、张量转换函数等。
- CUTLASS(CUDA Templates for Linear Algebra Subroutines):一个支持混合精度计算的库,为各种数据类型提供优化的操作,包括浮点(FP16到FP64)、整数(4/8位)和二进制(1位)。它利用NVIDIA的Tensor Cores进行高吞吐量的矩阵乘法。
- CuTe(CUDA Templates):一个仅包含头文件的C++库,提供Layout和Tensor模板。这些抽象封装了关于数据的基本信息,如类型、形状、内存位置和组织方式,同时还能实现复杂的索引操作。
Triton
Triton是一种基于Python的并行编程语言和编译器。Triton的创建者Phil Tillet也解释道,该语言旨在解决CUDA和现有特定领域语言(DSLs)在GPU编程方面的局限性。
虽然CUDA非常有效,但对于没有专业GPU编程经验的研究人员和从业者来说,它通常过于复杂。这种复杂性不仅阻碍了GPU专家和ML研究人员之间的沟通,也阻碍了在计算密集型领域中加速开发所需的快速迭代。
此外,现有的DSL具有限制性。它们缺乏对自定义数据结构的支持以及对并行化策略和资源分配的控制。
Triton通过允许其用户在SRAM中定义和操作张量,并使用类似torch的运算符进行修改,同时仍然提供实现自定义并行化和资源管理策略的灵活性,从而达到了平衡。Triton通过让没有丰富的CUDA经验的人也能够编写高效的GPU代码,从而让 GPU 编程不再遥不可及。
利用内存层次结构
GPU拥有多种内存类型,其大小和速度各不相同。内存大小和速度之间的反比关系是GPU内存层次结构的基础。将变量策略性地分配到不同的CUDA内存类型,可以使开发者更好地控制其程序的性能。指定的内存类型会影响变量的作用域(仅限于单个线程、在线程块内共享等)和访问速度。存储在高速内存(如寄存器或共享内存)中的变量可以比存储在全局内存等较慢内存类型中的变量更快地检索。
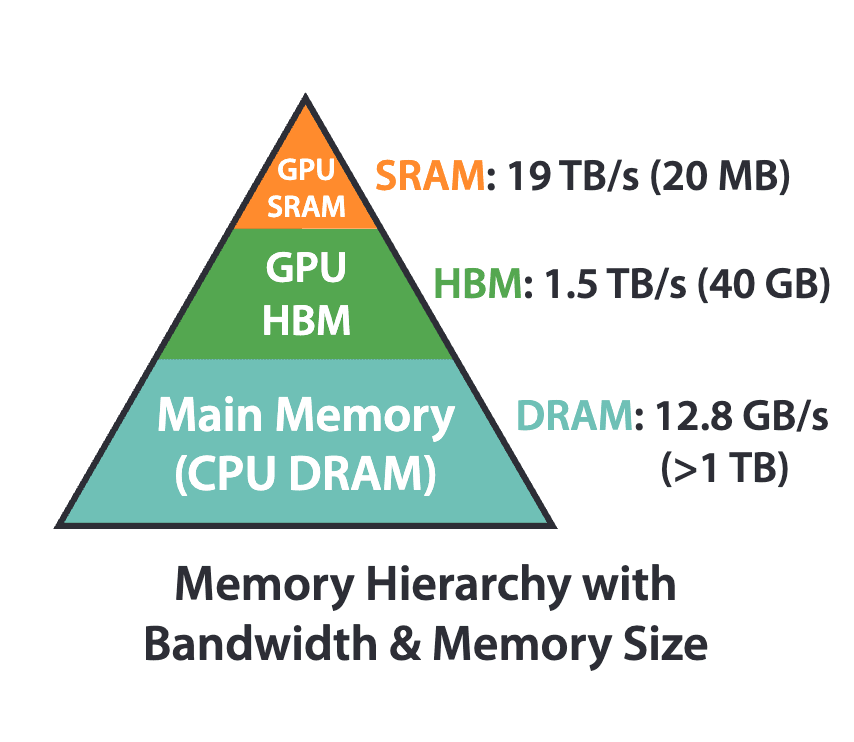
FlashAttention就是利用内存层次结构的一个硬件感知算法示例。
GPU 性能到底意味着什么?
GPU计算中的性能评估取决于预期的用例。尽管如此,用于评估整体效率的关键指标包括延迟和吞吐量。
延迟是指请求和响应之间的时间延迟。在我们最喜欢的并行处理器(GPU)的上下文中,请求是GPU收到处理命令时,响应是处理完成并返回结果时。
吞吐量是GPU每秒处理的单元数。此指标反映了GPU处理多个任务的并行能力。GPU架构师和开发人员努力最小化延迟并最大化吞吐量。
在对GPU进行基准测试时,通常会关注这些指标。例如,《Benchmarking and Dissecting the Nvidia Hopper GPU Architecture》研究报告,针对Hopper GPU的不同内存单元、Tensor Cores以及Hopper引入的新CUDA编程特性(DPX、异步数据移动和分布式共享内存)进行了延迟和吞吐量测试。
| 参数 | 值 |
|---|---|
| SMs | 108 |
| Total threads | 221,184 |
| PeakFP32TFLOP/s | 19.5 |
| PeakFP64TFLOP/s(non-tensor) | 9.7 |
| PeakFP64TFLOP/s(tensor) | 19.5 |
| TensorCorePrecision | FP64,TF32,BF16,FP16,I8,I4,B1 |
| Shared Memory per SM | 160kB |
| L2 Cache Size | 40960kB |
| Memory Bandwidth | 1555GB/sec |
| GPU Boost Clock | 1410MHz |
| NVLink Interconnect | 600GB/sec |
正如Stephen Jones在2022年GTC演讲《How CUDA Programming Works》中所说:每秒浮点运算次数(FLOPS)通常被引用为性能衡量标准,但它很少是限制性因素。GPU通常具有充足的浮点计算能力,因此,内存 带宽等其他方面被证明是更重要的瓶颈。
性能监控工具
GPU性能监控帮助开发者和系统管理员识别瓶颈(是受内存限制、延迟限制还是计算限制?)、有效分配GPU资源、防止过热、管理功耗,并就硬件升级做出明智决策。NVIDIA提供了两个强大的GPU监控工具:Nsight和SMI。
NVIDIA Nsight
NVIDIA Nsight Systems是一个系统级性能分析工具,可以可视化应用程序的算法并识别可优化的区域。有关NVIDIA Nsight Compute的更多信息,请参阅内核分析指南。
NVIDIA System Management Interface
NVIDIASystem Management Interface(nvidia-smi)是基于NVIDIA Management Library构建的命令行工具,用于管理和监控GPU设备。更多信息可以在nvidia-smi文档中找到。

常见问题解答
1. 为什么GPU优化对深度学习很重要?
深度学习模型通常需要数十亿个参数和海量数据集。如果不进行优化,训练可能需要数天甚至数周,导致成本高昂和实验速度变慢。优化GPU使用有助于缩短训练时间、提高准确性并更好地利用可用资源。这对于希望更快创新的研究人员、初创公司和企业尤其有用。
2. 有哪些常见的GPU性能优化技术?
深度学习的关键优化技术包括:调整批量大小以最大化GPU利用率(同时平衡内存限制);使用FP16进行混合精度训练以加速计算和减少内存使用;以及构建高效的数据管道,预先处理和加载数据。此外,缓存和预取策略有助于确保GPU始终有数据可供处理。总之,这些方法能使GPU完全投入计算,而不是在数据加载等较慢任务中闲置,最终提高速度和效率。
3.CUDA和cuDNN在GPU优化中扮演什么角色?
CUDA是NVIDIA的并行计算 平台,允许像TensorFlow和PyTorch这样的深度学习框架利用GPU。cuDNN是一个专门用于深度学习操作(如卷积、池化和归一化)的GPU加速库。通过使用CUDA和cuDNN,模型运行速度比在CPU或未经优化的GPU代码上运行快得多。
4. 如何识别 深度学习 工作流 中的性能瓶颈?
瓶颈可能发生在多个层面——数据加载、内存使用或计算。像NVIDIA Nsight Systems、NVIDIA Nsight Compute、TensorBoard或PyTorch Profiler这样的工具可以帮助可视化训练工作负载。它们可以突出显示GPU是否利用不足(由于数据管道缓慢)或者内存是否因低效操作而浪费。
5. 有哪些 GPU 内存 优化技术?
管理有限GPU内存的成熟技术包括梯度检查点,它通过重新计算中间值而不是存储它们来节省内存;以及模型 剪枝或量化,它们在对准确性影响最小的情况下缩小模型大小。此外,从FP32切换到FP16等更高效的数据类型可以减少总内存占用。总之,这些策略使得将更大的模型适配到受限的GPU资源中成为可能,同时最大限度地减少内存不足错误的风险。
6. 多GPU和分布式训练如何提高性能?
在训练超大数据集或模型时,单个GPU可能不足以胜任。多GPU训练将数据分割到多个GPU上,允许并行计算。分布式 训练更进一步,将工作负载扩展到具有GPU的多台服务器上。这种方法可以加快训练速度,处理更大的模型,并缩短获得结果的时间。
7. 不拥有昂贵硬件可以优化GPU性能吗?
是的!像**DigitalOcean Gradient™ AI GPU Droplets**这样的云提供商提供了对高性能GPU(如NVIDIA A100或H100)的灵活访问。这意味着您只需为您使用的GPU时间付费,这对于不愿投资昂贵本地GPU的初创公司、研究人员或个人来说具有成本效益。这种可扩展的解决方案,让每个人都能轻松进行优化。
结论
本文并非对GPU优化的所有内容都进行了总结,而只是对该主题的一个介绍。
为深度学习优化GPU性能不仅仅是为了更快的训练——更是为了充分利用可用硬件,以提高效率、可扩展性和成本效益。从微调批量大小和内存使用,到利用混合精度和高效的数据管道,这些技术可以显著影响模型的训练和部署的顺畅度和有效性。
对于开发者和研究人员来说,要实现这些优化,正确的基础设施至关重要。**DigitalOcean Gradient™ AI GPU Droplets**提供了专为AI和机器学习工作负载设计的按需、高性能GPU。无论您是在进行小型项目实验还是运行大规模训练,GPU Droplets都为您提供了应用性能优化技术的灵活性,而无需受基础设施限制的束缚。
通过将GPU优化的最佳实践与DigitalOcean云平台的简单性和可扩展性相结合,您可以加速您的深度学习项目,降低成本,并更多地专注于创新。如需了解DigitalOcean上 H200、H100、MI325X、MI300X和A100等GPU的最新价格与优惠政策,可直接联系DigitalOcean中国区独家战略合作伙伴卓普云aidroplet.com。


