在 Deploy 2026 大会上,DigitalOcean 推出了为推理时代而生的 DigitalOcean AI 原生云。DigitalOcean 推理引擎上的批量推理支持大规模异步工作负载。换句话说就是可以将大批量、非实时的推理任务打包提交,后台异步处理,无需同步等待结果。随着开发者从 AI 原型走向生产级应用,成本和速率限制往往是最大的瓶颈。批量推理解决了这些障碍,让你能够以同步请求的几分之一成本,异步处理海量工作负载。
无论你是在进行大规模数据转换、内容生成、构建嵌入还是离线评估,批量推理都提供了一种统一且一致的方式,通过 DigitalOcean 的一个 API 来使用 OpenAI 和 Anthropic 等前沿大模型。
AI 扩展瓶颈
实时推理对于聊天机器人、编码助手和即输即搜等交互式 AI 应用至关重要。但当任务涉及处理 10,000 张支持工单以进行情感分析、为整个产品目录生成 SEO 元数据,或针对测试套件对新系统提示进行基准测试时,实时推理就成了一种昂贵且低效的工具。
这些请求中的每一个都与生产流量争抢同样受速率限制的吞吐量。团队不得不花费大量工程时间来编写重试逻辑、管理背压(Backpressure),并监控那些需要连续运行数小时 API 调用的脚本。如果你使用多个供应商的模型,比如用 OpenAI 做嵌入、用 Anthropic 做生成,那么即使核心工作流完全相同——提交请求、等待、获取结果——你还要管理不同的凭证、不同的账单仪表板和不同的错误处理策略。
处理数千个同步请求不仅缓慢,更是一项架构挑战。在规模上,同步推理变得效率低下,需要数千个保持开启的连接,产生持续的速率限制压力,并在等待响应时浪费算力。它还会引入吞吐量瓶颈、重试风暴和不一致的延迟,同时将复杂的编排逻辑(排队、重试、退避)推给客户端。跨多个模型供应商时,这种碎片化只会加剧运维负担。
DigitalOcean 批量推理为什么能解决这个问题
借助批量推理,你可以在单个 .jsonl 文件中提交最多 OpenAI 的 50k 个请求或 Anthropic 的 100k 个请求,让 DigitalOcean 负责处理编排:排队、执行和结果交付。
这种方案的独特之处在于其统一界面。你无需分别与每个供应商打交道,而是可以通过单个 DigitalOcean API 访问 OpenAI 和 Anthropic 等模型。统一的端点、统一的认证流程以及统一的计费账户,让您可以在同一个地方监控每一个任务,而无需关心它具体是由哪家模型服务商执行的。
这个统一的控制平面在管理运维复杂性的同时,保留了对每个供应商原生模型能力的完整访问。
DigitalOcean 批量推理提供统一的操作入口
无论你使用哪个模型,上传、提交和获取结果的工作流完全相同。通过使用一套端点和一次认证流程,你可以在不重写编排逻辑或对账不同发票的情况下,切换或组合供应商。
显著的成本节约
与标准实时推理费率相比,批量请求在输入 token、输出 token 以及缓存 token 上都有显著折扣。如果你目前正以实时价格运行后台工作负载,切换到批量可以将成本降低高达 50%。
示例:使用 Claude Opus 4.6 的 50,000 个请求(假设每个请求平均 1,000 个输入 token 和 500 个输出 token。)
| 指标 | 实时推理 | 批量推理 |
|---|---|---|
| 输入成本(5000 万 token @ $5/M) | $250.00 | $125.00 |
| 输出成本(2500 万 token @ $25/M) | $625.00 | $312.50 |
| 总成本 | $875.00 | $437.50 |
| 以上定价信息截至 2026 年 5 月 |
在此示例中,通过切换到批量模式,你可以在一次运行中节省 $437.50。这让你能够将顶级智能用于那些原本可能因成本过高而无法进行的大规模数据处理任务,同时为在高吞吐量工作负载中优化推理预算创造了新的机会。
绕过速率限制
批量任务在专用吞吐通道上运行,与你的实时推理配额完全分离。当 40,000 个请求的批量任务在后台处理时,你的生产端点始终保持健康。这有助于减少数据流水线中 429 Too Many Requests 错误。
异步处理
提交任务即可继续其他工作。DigitalOcean 会管理队列、重试和交付。你可以在任务完成时轮询结果,或配置 webhook 自动接收通知(webhook 通知即将推出)。
与 DigitalOcean 计算资源深度集成
批量推理内置于 DigitalOcean 平台中。工作流的每一部分,从文件存储到任务监控再到用量分析,都运行在你已经在使用的基础设施上。
由 DigitalOcean Spaces 驱动
输入文件(最大 200 MB)通过预签名 URL 直接上传到 DigitalOcean Spaces(对象存储)。无需配置外部存储,无需开通 S3 存储桶,也无需管理跨账户 IAM 策略。API 生成一个预签名上传 URL,你只需 PUT 你的 .jsonl 文件,Spaces 会处理其余一切。
结果的交付方式相同。当任务完成时,结果端点返回一个预签名的 Spaces 下载 URL。结果文件保留最多 30 天,你可以按自己的时间安排来获取。
这正是为 DigitalOcean 生态其余部分提供支持的 Spaces 对象存储,现在已集成到你的 AI 批量流水线中。
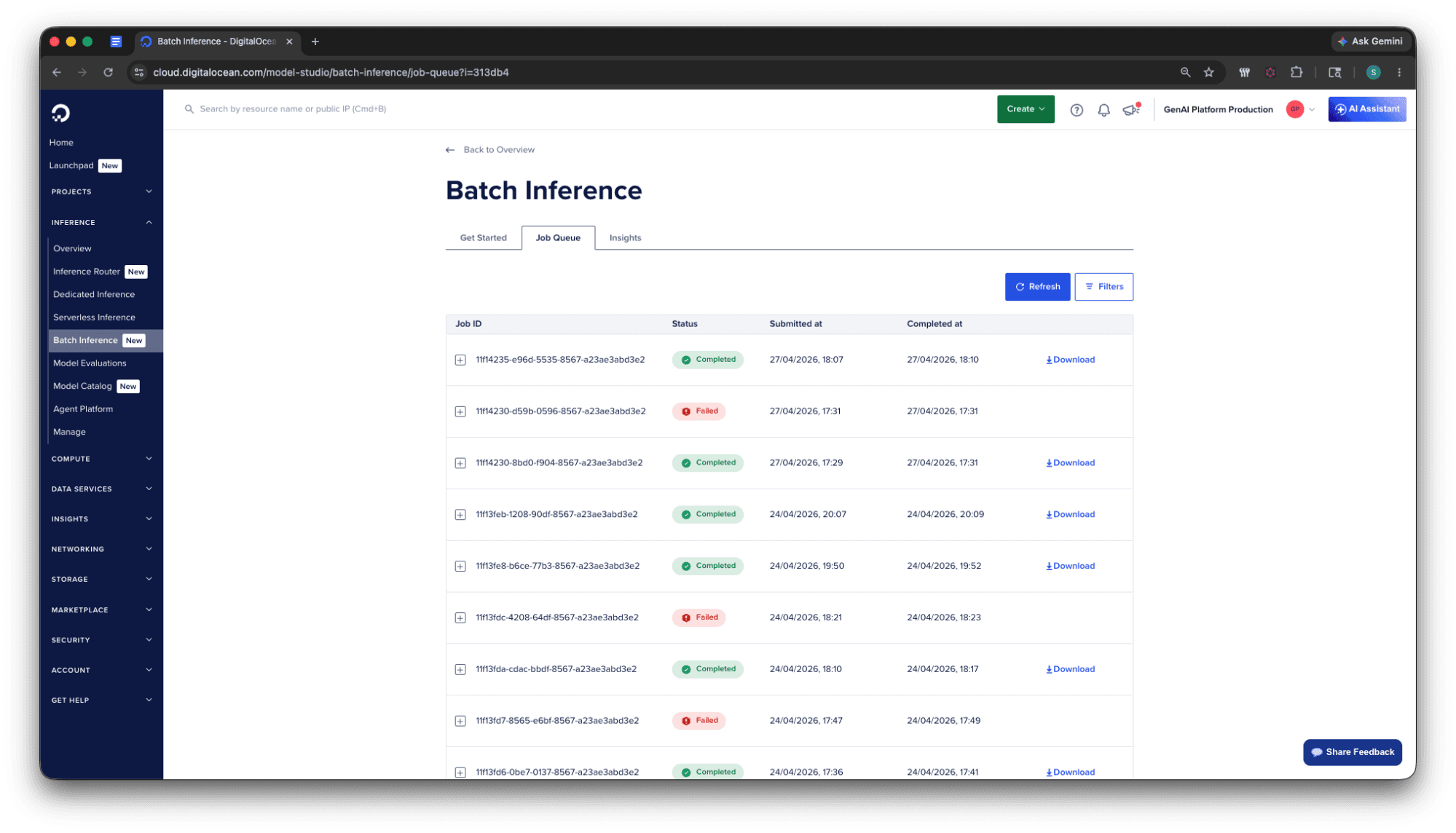
任务队列:实时追踪每项任务
DigitalOcean 控制面板中的批量推理任务队列提供每项批量任务的实时视图,OpenAI 和 Anthropic 的任务并排显示在一个列表中。对于每项任务,你可以查看:
- 状态:等待处理、进行中、已完成、失败、已取消
- 进度:总请求数、已完成数和失败数,随任务运行实时更新
- 时间戳:任务提交、开始和完成的时间
- 供应商:哪个供应商正在执行批量任务
这消除了在开发过程中轮询 API 的需要。你可以直接从你用于管理 Droplet、数据库和 Kubernetes 的同一个控制面板监控你的任务。
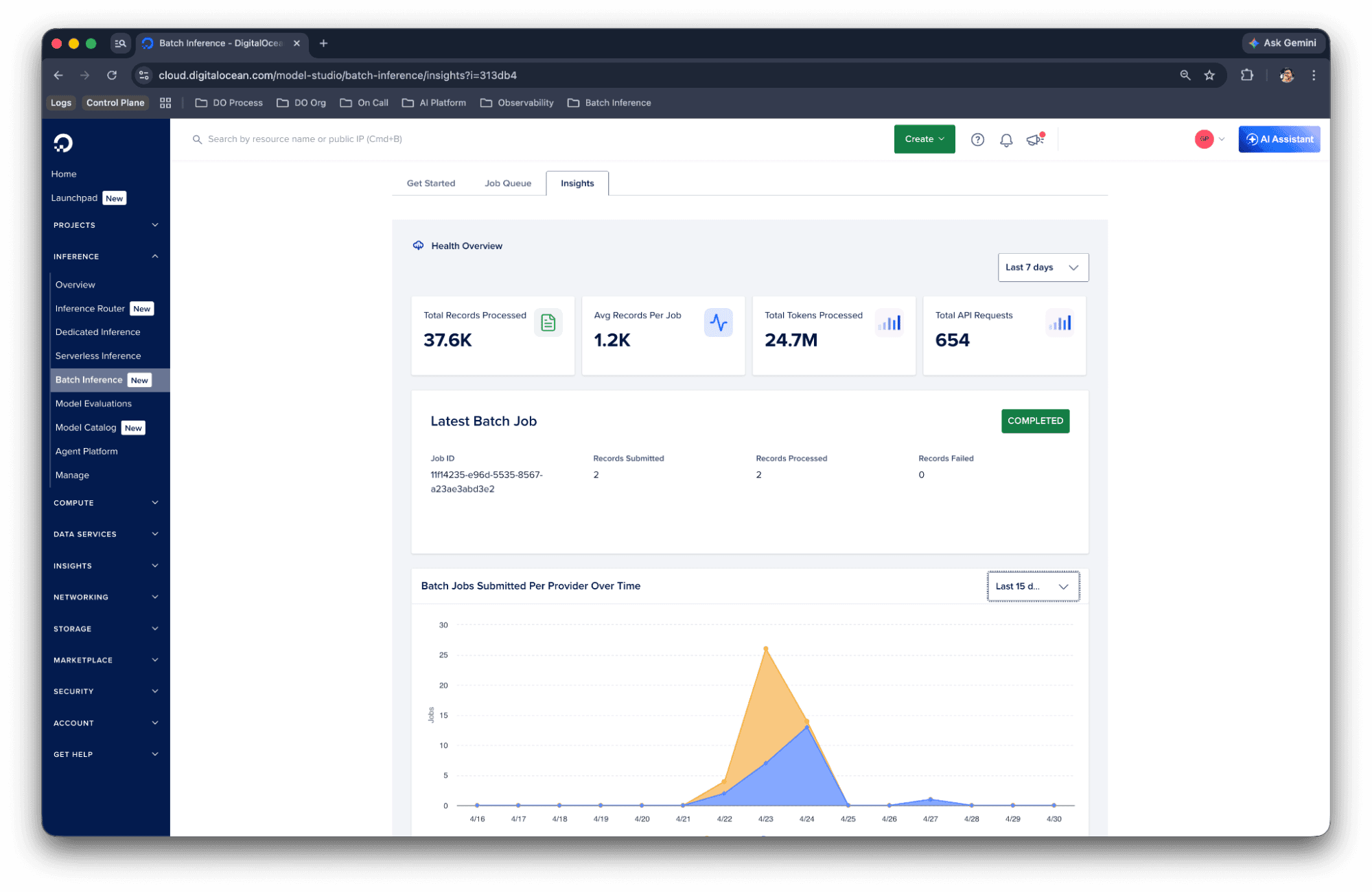
Insights:了解你多个模型的使用情况
批量推理 Insights 页面提供了跨两个模型供应商的批量使用情况的集中视图。你可以追踪 token 消耗、任务量和随时间变化的完成趋势,所有这些都在一个地方完成,而无需分别查看 OpenAI 和 Anthropic 的仪表板。
使用批量推理 Insights 来理解成本模式、识别使用高峰期,并为你的批量流水线规划容量。
统一的计费
OpenAI 和 Anthropic 批量工作负载的 token 用量和任务成本都显示在一张 DigitalOcean 账单上。无需跨供应商对账不同的账单,也无需管理额外的付款方式。DigitalOcean 支持信用卡、支付宝、Paypal等支付方式,同时你的企业还可通过卓普云(aidroplet.com)与 DigitalOcean 进行公对公直签,并获取中文的技术支持服务。
MCP 服务器支持
批量推理也可作为 MCP(模型上下文协议) 服务器使用,能够无缝集成到 AI 驱动的 IDE、智能体框架和任何兼容 MCP 的客户端中。这让开发者能够在现有工作流中直接创建批量任务、监控任务状态并获取结果。
智能体可以被指示对输入文件(例如用于批量推理的 JSONL 文件)进行操作,只需引用指定的文件路径。基于此上下文,智能体自主选择并调用合适的 MCP 工具来处理文件上传并发起批量任务创建。它可以监控状态,任务完成后,用户可以提示智能体获取最终的任务结果和对应的下载 URL,从而以最少的人工干预提供一个无缝的端到端工作流。
如何运作
无论你面向 OpenAI 还是 Anthropic,工作流都是相同的:准备、上传、提交、获取。所有请求发送到 https://inference.do-ai.run/v1,并通过你的模型访问密钥进行认证。
- 准备你的输入文件。 创建一个
.jsonl文件,每行是供应商原生格式的一个推理请求。OpenAI 的行包含custom_id, method, url,和body。Anthropic 的行包含custom_id和params。模型在文件内部按请求指定,让你在单个批量任务内拥有完全的灵活性。 - 上传你的文件。 调用
POST /v1/batches/files并传入文件名以获取file_id和预签名 Spaces 上传 URL。然后将你的.jsonl文件PUT到该 URL。预签名 URL 有效期为 15 分钟。 - 创建批量任务。 调用
POST /v1/batches并传入file_id、provider(openai或anthropic)以及completion_window (24h)。两个供应商的端点、认证和响应格式完全相同,唯一的区别是provider字段。 - 监控并获取结果。 轮询
GET /v1/batches/{batch_id}获取状态,或通过控制面板中的任务队列监控进度。一旦任务达到已完成状态,调用GET /v1/batches/{batch_id}/results获取输出文件和错误文件的预签名下载 URL。结果文件保留 30 天。
你还可以用 GET /v1/batches 列出所有任务,用 POST /v1/batches/{batch_id}/cancel 取消正在运行的任务。
有关完整的 API 详情、代码示例(cURL 和 Python)以及输入文件格式示例,请参阅批量推理文档:https://docs.digitalocean.com/products/inference/how-to/use-batch-inference/
批量推理有哪些使用场景?
批量推理非常适合任何高吞吐量、对延迟不敏感的工作负载。以下示例是一些最常见的模式。
电商目录丰富化
一个拥有 50,000 个产品的电商平台需要为每个列表生成 SEO 友好的标题、营销描述和元数据标签。与其通过数天的顺序 API 调用来处理,不如将整个目录作为一个批次提交。你可以用 gpt-4o-mini 生成英文文案,然后用 Claude 跑第二个批次做本地化翻译,全程通过同一流水线,只需更改 provider 字段。
支持工单分类与分流
组织可以在一个批次中处理一整年的支持工单,按类别、紧急程度和情绪进行分类,同时提取产品名称、问题类型和客户等级等结构化字段。输出是一个干净的 .jsonl 文件,可随时导入到分析流水线或 CRM 中。
大规模内容审核
拥有用户生成内容的平台,如市场、论坛和评论网站,通常需要扫描数千条帖子、图片和列表以检查是否违反政策。批量推理让你可以在夜间处理整个积压队列,而不会与生产审核端点的速率限制发生冲突。
模型评估和提示工程
在开发新的系统提示时,你可以通过同一 API 针对数千个测试用例,对 OpenAI 和 Anthropic 模型运行相同的评估套件。这让你能以批量定价进行结果对比,成本远低于实时运行相同的评估。
文档处理和数据提取
批量推理可以总结数千份法律合同、研究论文或财务文件。它还可以从非结构化文档中提取结构化数据,如日期、金额、当事方和条款,或对积压的发票和收据进行分类。这些任务量大但通常对时间不敏感。
开始使用
批量推理现已在 DigitalOcean AI 平台上线。
目前支持轮询任务状态,webhook 通知即将推出以用于自动化工作流。随着平台的发展,敬请期待更多供应商和模型支持。
更广阔的图景
推理已成为现代 AI 系统的重心。应用不再是单次模型调用,它们协调多个模型,检索并合成数据,执行工具,然后在生产中重复这一循环。这是一个栈的问题,而非模型的问题。
DigitalOcean 的 AI 原生云正是为此而构建。五个层次,一个平台,每一层都开放:GPU 计算、推理、数据与存储、智能体,以及连接它们的工具。批量推理是推理层的最新成员,与实时无服务器推理、新的推理路由器、专用推理以及涵盖文本、图像、音频和视频的 25 个以上模型目录并列。
实时推理为交互式体验提供动力,批量推理则处理在幕后进行的繁重工作。与 GPU Droplet、知识库和托管数据库(包括用于向量工作负载的托管 Weaviate 私有预览版)一起,它们构成了一个完整的系统,用于构建生产级 AI,而无需拼凑来自多个供应商的服务。
我们的目标是简化技术栈,让你可以专注于构建。
相关产品与选型