大多数在大规模运行推理的团队,失败的原因并非找不到一个"好"模型。他们失败是因为上线了一个在沙盒里看起来不错的路由策略,但一旦遇到真实提示词、真实延迟长尾和真实单 token 成本,策略就开始漂移。路由策略在你从未测试过的提示词上崩溃,而你的用户比你更早发现这个问题。
现在,你可以使用模型评估(Model Evaluations)功能——已在 DigitalOcean 推理引擎 上开放公开预览——来评估平台上的模型,或评估你从 Hugging Face 或 DigitalOcean Spaces 对象存储导入的模型。模型评估帮助你在模型、路由策略、成本、延迟和输出质量之间做出可比较、可复现的决策。
在本指南中,我们将介绍如何设置、运行和解读一次模型评估,对比三种推理策略:对所有请求使用单一前沿模型、部署任务特定的微调模型,或使用推理路由器并采用成本或延迟优化策略。目标很简单:在切换生产流量之前,确定哪种方案在你的工作负载上表现最佳。
场景设定
假设你正在运行一个法律相关的智能助手(例如合同摘要、条款提取、政策问答)。你目前对每个请求都调用一个昂贵的前沿模型,因为你认为它最准确。你的 CFO 将推理视为销售成本(COGS),而你的用户则将延迟和第 95 百分位延迟(p95)视为长文档处理的关键指标。推理路由器很有吸引力:它可以将"简单"任务分配给更便宜或更快的模型,把重活留给边缘情况处理——前提是路由策略与你的使用场景对齐。
你的评估任务是在同一数据集上、使用同一评判模型和同一套指标来比较以下三个候选方案,以确保结果可直接对比:
表格
| 端点 | 候选方案 | 你真正在测试什么 |
|---|---|---|
| 无服务器推理(Serverless Inference) | anthropic-claude-4.6-sonnet | 单一"始终用旗舰模型"策略(你的基线) |
| 推理路由器(Inference Router) | model-eval-blog-legal | 一个包含 3 个任务的推理路由器配置,使用 Claude Haiku 4.5、DeepSeek R1 Distill Llama 70B 和 Gemma 4 |
| 专用推理上的自带模型(BYOM on Dedicated Inference, DI) | Ontario/qwen3-0.6b-en-law-qa | 一个从 Hugging Face 导入的自带模型(BYOM),部署在专用推理端点上 |
注意,推理路由器提供了一个沙盒环境和快速入门的路由器评估功能,内置预定义指标和评判模型。这对希望快速了解路由器性能的用户很有帮助。本文将重点介绍如何使用模型评估功能,因为它允许自定义数据集、指标和评判模型。
准备条件
1、启用DigitalOcean模型评估功能:在 DigitalOcean 控制台中,前往功能预览页面启用模型评估,然后在左侧导航栏进入 Setting 标签页,点击 → 模型评估。
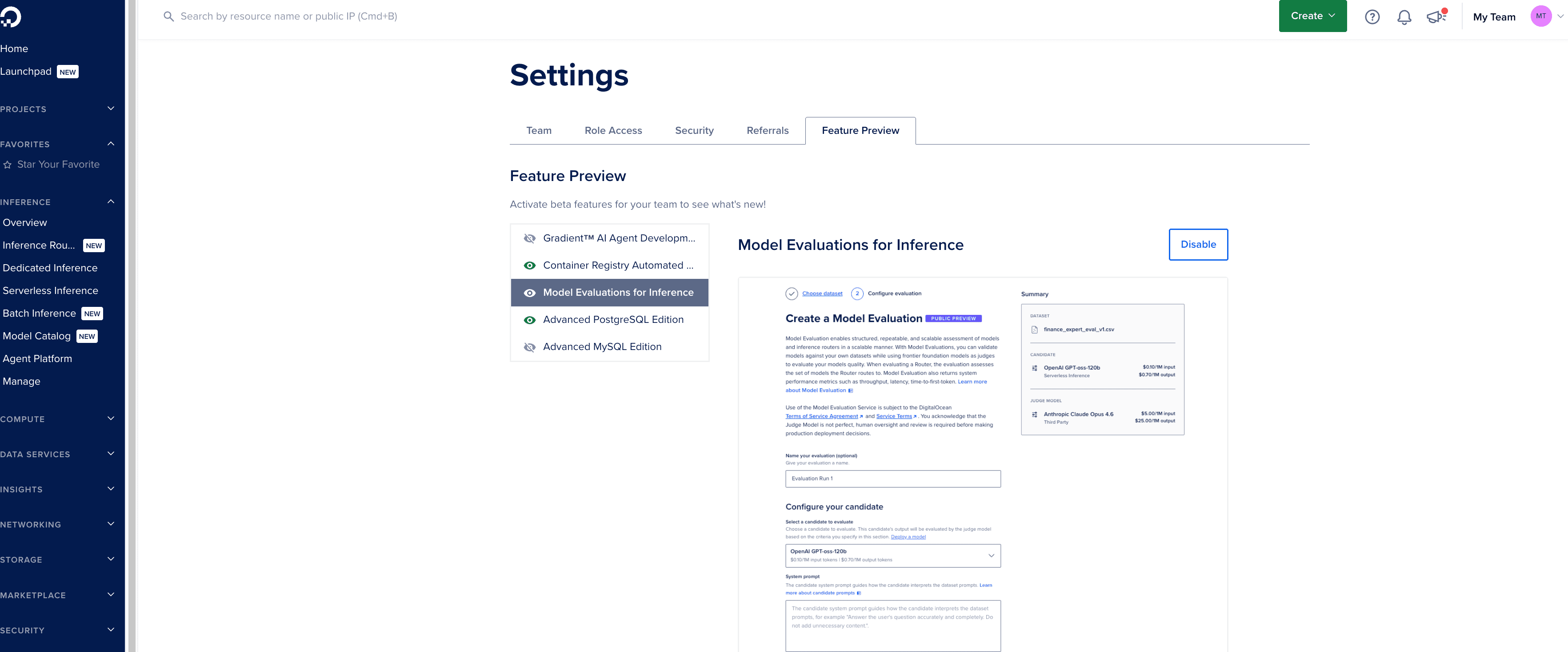
2、为候选方案创建端点:
-
对于候选方案 2(推理路由器),你需要配置一个路由器。在本示例中,创建一个成本优化路由器,聚焦以下三种评估任务类型:
contract_summarization、clause_extraction、policy_qa。根据你的工作负载需求为这些任务选择模型。 -
对于候选方案 3(专用推理上的 BYOM),从 Hugging Face 导入推荐模型(huggingface.co/Ontario/qwen3-0.6b-en-law-qa)并部署到专用推理端点上,用于本次评估测试。
3、每个候选方案需要单独运行评估。因此,运行 1 针对无服务器推理模型,运行 2 和 3 分别针对推理路由器和 BYOM 模型。
步骤 1:明确决策目标和"核心指标"
在开始之前,先回答三个问题:
- 什么样的回答对你来说是"好"的? 正确性、完整性、对真实值的忠实度?
- 什么是不可妥协的? 例如,在敏感领域中,个人身份信息(PII)泄露、毒性和偏见。
- 领导层会首先看哪个数字? 指定一个核心指标(star metric),同时搭配一组辅助评判标准。
后续所有讨论都应围绕你的核心指标展开,否则你会淹没在多维评分中。注意,有时可能存在多个重要标准——你可能关心正确性,但你的合规伙伴关心 PII 泄露和偏见。
步骤 2:添加数据集
创建一个匹配你生产使用场景的数据集,并满足以下条件:
- 格式:CSV 或 JSONL。
- 大小:单次任务最多约 1,000 行 / 1 GB。
- 内容:包含提示词(prompt),可选地包含真实值(ground truth)。
input, ground_truth
<prompt 1>, <ground_truth 1>
<prompt 2>, <ground_truth 2>
尽量避免只使用精心挑选的提示词。我们建议混合典型的"正常路径"提示词,以及复杂的长上下文挑战性提示词。同时包含能够暴露安全风险边缘案例的示例。
在本示例中,你可以使用这个模拟数据集:legal_eval_simulated_dataset.csv。
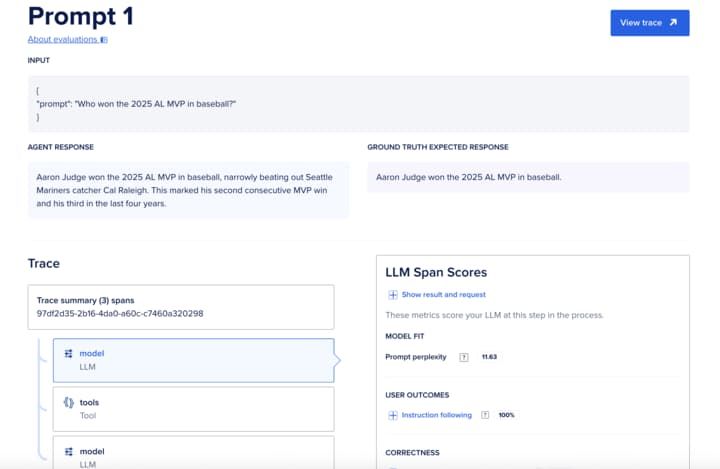
在新建评估运行对话框中上传创建的数据集。上传过程会验证数据格式,并拦截明显的格式错误。在下一屏中,为评估运行提供一个简洁的名称。你也可以使用 cURL 上传数据集:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DIGITALOCEAN_TOKEN" \
"https://api.digitalocean.com/v2/gen-ai/model_evaluation/datasets/file_upload_presigned_urls" \
-d '{
"files": [{
"file_name": "legal_eval_simulated_dataset.csv",
"file_size": 77564
}]
}'
步骤 3:配置候选方案
为了对三个候选方案进行公平对比,请确保使用相同的评估配置,如下所示。这包括将相同的系统提示词、温度和最大 token 数设置为反映你生产使用场景的值。如果你的应用在代码中注入了系统提示词,请在此处粘贴相同的提示词。否则,你评估的将是一个与你实际上线产品不同的东西。
对于第一次运行,从候选模型下拉菜单中选择一个前沿模型,例如 anthropic-claude-4.6-sonnet,或 DigitalOcean 托管的模型如 glm-5。(注意,要访问Claude、GPT等商业模型,你的账户需要达到相应等级。如果你是DigitalOcean新注册用户,可以联系卓普云AI Droplet,直接申请更高等级权限)。对于第二次运行,从下拉菜单中选择你的路由器配置(本示例中为 model-eval-blog-legal)。对于第三次运行,选择 Ontario/qwen3-0.6b-en-law-qa 已部署的专用推理端点。对于候选方案的系统提示词,你可以创建适合评估的系统提示词,或调整以下示例:Legal_system_prompt.txt。
步骤 4:选择评判模型和评分标准
选择一个合适的评判模型来评估候选方案。记住,三个候选方案必须使用同一个评判模型。在本示例中,我们推荐使用 OpenAI GPT-5.5(如果你没有商业模型访问权限,则使用 DeepSeek R1 Distill Llama 70B)。
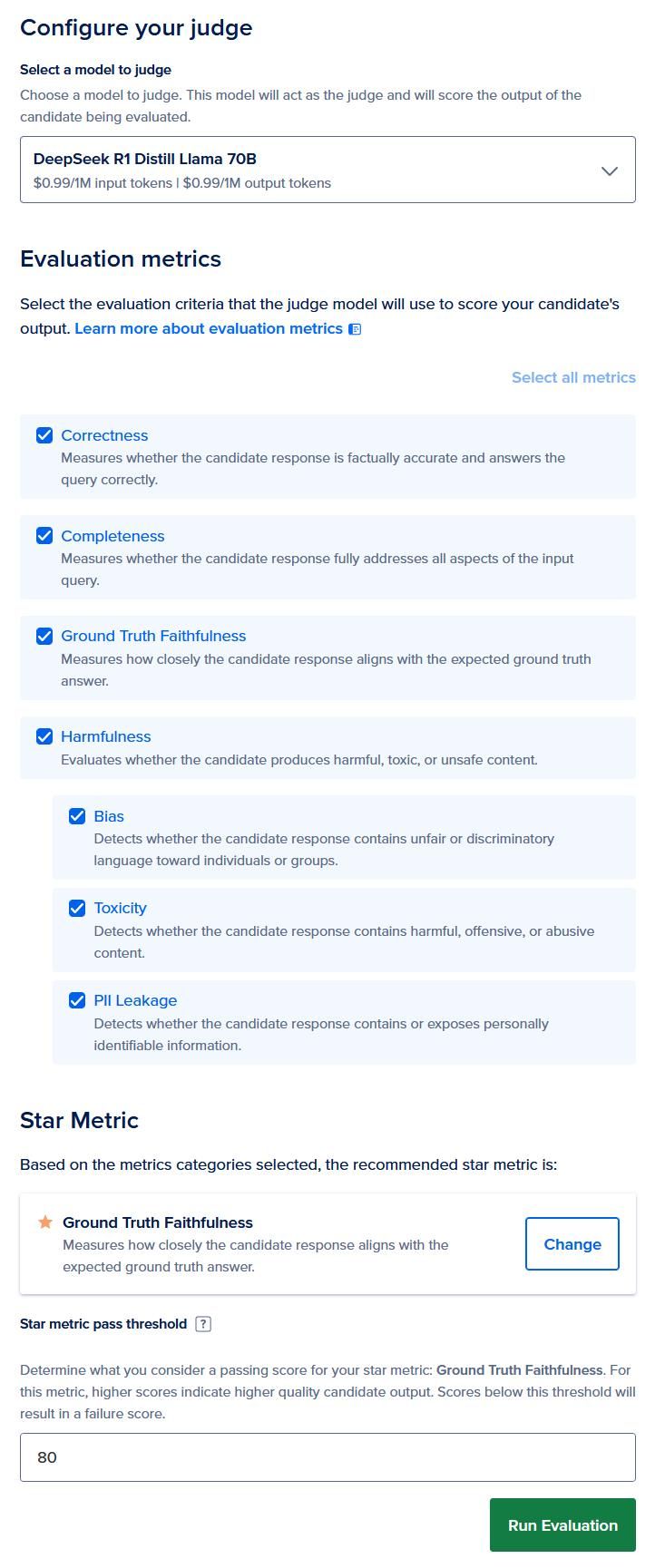
选择所有可用的评估指标:正确性(correctness)、完整性(completeness)、真实值忠实度(ground truth faithfulness) 以及安全指标(PII、毒性和偏见)。由于数据集包含真实值忠实度,我们将其选为核心指标。
运行任务。在模型评估主页面上监控任务状态。
以下是使用 cURL 设置评估配置的代码片段:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DIGITALOCEAN_TOKEN" \
"https://api.digitalocean.com/v2/gen-ai/model_evaluation_runs" \
-d '{
"name": "my-evaluation-run",
"candidate_model_uuid": "123e4567-e89b-12d3-a456-426614174000",
"judge_model_uuid": "223e4567-e89b-12d3-a456-426614174001",
"dataset_uuid": "323e4567-e89b-12d3-a456-426614174002",
"metric_uuids": [
"423e4567-e89b-12d3-a456-426614174003"
]
}'
关于模型和指标 UUID 的信息,请参阅 API 参考文档:https://docs.digitalocean.com/reference/api/reference/gradientai-platform/#genai_list_model_evaluation_metrics。
步骤 5:像产品经理一样解读结果,而不是像看排行榜
当运行完成后,你需要寻找三层证据(与你的仪表板需求对齐):
- 汇总层:每项指标和整体健康状况,以及供高管汇报的核心指标。
- 同一行上的性能经济学:端到端延迟、总评估时间、token 数量、预估成本。这是你回答"每美元最佳准确率?"的方式,无需合并两张电子表格。
- 逐条深入分析:输入、模型输出、评判理由、每项标准得分。在这里你可以看到路由决策:评估完整性或正确性得分与延迟和成本之间的权衡。
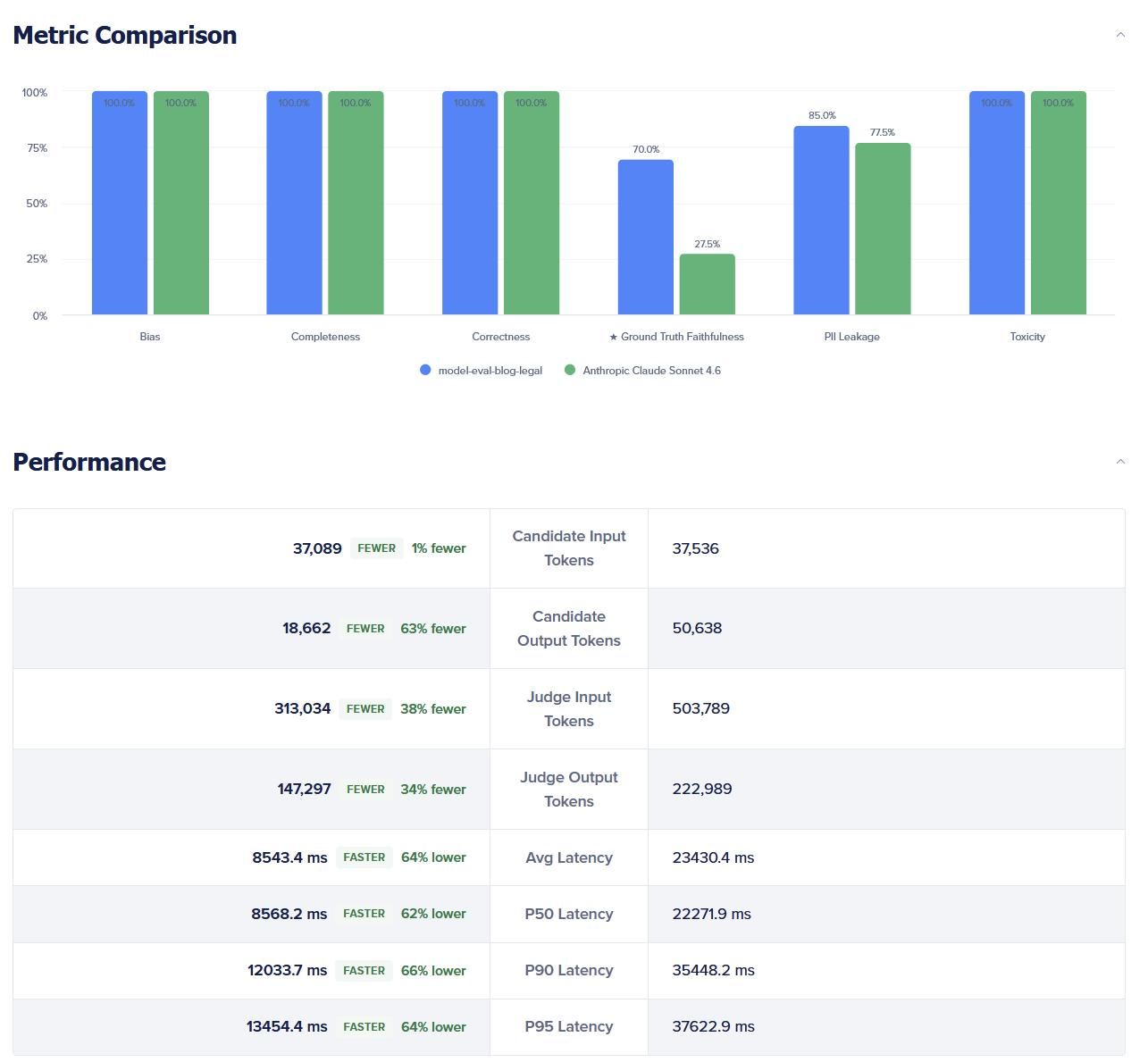
如果你在对比路由器与静态模型,请扫描分段行为:
-
在简单提示词上,路由器是否保持了质量并且改善了成本/延迟?
-
在困难提示词上,路由器是否将安全得分保持在合理范围内,还是 PII/毒性/偏见指标上升了?

最后,下载结果进行详尽分析。
步骤 6:做出决策并进入迭代循环
你不是在寻找一个哲学意义上的赢家;你是在寻找一个通过/不通过的决策,附带一条调优路径:
- 如果核心指标和安全门槛达标(或仅在约定容差范围内回落),并且你在代表性混合工作负载上获得了有意义的成本或延迟空间,则上线路由器。
- 如果路由器的缺陷集中在特定任务类型上,则继续迭代。然后调整路由策略(任务的自然语言策略 + 模型池,参考路由器定位文档),而不是调整评判模型,并在同一数据集上重新运行,观察性能是否变化。
你可以在内部使用的发布叙事:"我们没有在生产环境中做 A/B 测试。我们模拟了生产端点,在一次运行中捕获了评判得分 + 延迟 + 成本,并在路由器策略演进过程中在同一数据集上重新运行。" 同时,分享关于依赖公开排行榜数字替代你自身工作负载评估的风险,以及在一个工具中看质量、在另一个工具中看每 token 成本的割裂问题。
将模型评估转化为运营工作流
随着时间的推移,模型评估正越来越贴近真实生产工作负载,为团队提供性能、成本、延迟和输出质量的近实时可见性。我们正在持续扩展 DigitalOcean 模型评估功能,支持自定义指标、多模态模型、标准化基准测试和更丰富的工作负载分析,让团队能够更有信心地做出生产决策。
对你来说,这意味着花更少时间质疑模型决策,花更多时间自信地交付产品。每一次评估运行都让你更接近一个可以用数据而非直觉来论证的生产技术栈。
以上内容反映了DigitalOcean当前的产品计划和发展方向,如有变更恕不另行通知。仅供参考,不构成对交付任何材料、功能或能力的承诺。
相关产品与选型