
一个单打独斗的 LegalTech 创始人手里有超过一万份内部案件文件,产品需要一个能给出带来源引用的可靠答案的 AI 助手,但这位创始人第一天并不想自己运维向量数据库、嵌入服务或重排序器。
DigitalOcean Knowledge Bases 就是一个托管的 RAG 流水线。你只需要把文件指向 Spaces对象存储,平台就会自动帮你搞定分块、嵌入,并存入 OpenSearch托管数据库。检索能力以 MCP 工具的形式对外开放,地址在 https://kbaas.do-ai.run/v1/mcp,这样一来,智能体框架只需调用一个函数,而不用去串联五个服务。
这篇教程和那些教你手动拼装 LangChain + Chroma 的老式 RAG 教程不一样。这里,你只用 DigitalOcean AI原生云的基础设施:Spaces对象存储、知识库、MCP、无服务器推理(Serverless Inference),以及一个你要部署到 应用托管服务(App Platform)上的轻量 FastAPI 服务。
本文关键要点
- Knowledge Bases 能索引 Spaces 存储桶里的 PDF、Markdown、HTML 等超过 15 种文本格式,你完全不用自己跑向量基础设施。
- Knowledge Bases MCP 端点提供了
retrieve_knowledge_base用于混合搜索,每次调用能返回 1 到 25 个结果。 - MCP 检索的计费方式与 Knowledge Base 检索 API 一致:你需要为查询向量化支付嵌入 token,再加上可选的重排序 token。
- 答案生成是独立计费的。你的 FastAPI 服务按 token 为 无服务器推理 付费(例如,Claude Sonnet 4.6,对于高达 200K token 的提示,每百万输入 token 3.00 美元,每百万输出 token 15.00 美元)。
- 在应用托管服务上创建智能体是免费的,但你得为模型使用量、索引、存储和检索付费。
- 对于生产级 LegalTech 工作负载,建议从 TOR1 区域开始。根据 Knowledge Base 文档,大多数 Agent Platform 基础设施都跑在那里。
什么时候适合用 Knowledge Bases + MCP,什么时候不适合
| Knowledge Bases + MCP 适合的场景 | 可以考虑其他方案 |
|---|---|
| 静态或半静态文档库(案件文件、手册、政策) | 实时交易数据(CRM 行、工单状态) |
| 你想要混合语义加关键词检索,并可选重排序 | 你只需要单一 API 调用,无需文档支持 |
| 你想为 Cursor、LangChain 或自定义智能体获取 MCP 标准工具访问 | 你需要在定制硬件上实现亚 10 毫秒的大规模 QPS 检索 |
| 你想要托管的 OpenSearch 和 Spaces 存储 | 你出于政策原因必须跑自托管向量数据库 |
| 从原型到生产都在一朵云上 | 你已经有一套成熟且不想动的 RAG 技术栈 |
关于 RAG 与 MCP 在模式层面的决策树,可以参考 RAG 和 MCP 指南。这篇教程用 RAG 做文档支撑,用 MCP 做工具传输。
准备工作
开始之前,请确认你有:
- 一个 DigitalOcean 账户。(注意,新注册用户无法使用无服务器推理中的Claude、GPT系列模型,如需解禁只需联系卓普云即可)
- Control Panel 里的 Inference 和 Agent Platform 访问权限。
- 一个用于检索和 MCP 的 个人访问令牌,需要包含
GenAI:read权限;以及通过 API 创建知识库所需的genai增删改查权限。 - 一个来自 INFERENCE → Serverless Inference → Model Access Keys 的 模型访问密钥,或者一个拥有 Serverless Inference 访问权限的个人访问令牌(在某些账户上,当专用模型密钥不可用时,可以用同一个 PAT 作为
MODEL_ACCESS_KEY)。 - 已启用的 Knowledge Base Enhancements 预览功能,建议开启以使用高级分块和检索端点。
- 用于本地测试和 App Platform 部署的 Python 3.10+ 和 doctl。
实验提示: 请在沙盒项目中操作。本教程演练不要上传真实的客户个人隐私信息。仓库中的示例文件都是虚构的。
注意: 你也可以在 Control Panel 中使用 DigitalOcean Launch Pad,在 RAG Assistant Starter Kit 下部署这个 RAG 智能体。它遵循的步骤与本教程相同。但为了便于理解和学习,我们将手动部署所有内容。

术语速查表
| 术语 | 可以这样理解 |
|---|---|
| RAG | 检索相关文档片段,然后让 LLM 基于这些片段来回答 |
| Knowledge Base | 针对你的文件或 URL 的托管索引 |
| MCP | LLM 智能体调用工具的一种标准方式,比如调用 retrieve_knowledge_base |
| Spaces | S3 兼容的对象存储,用来存放你的原始案件文件 |
| Serverless Inference | 按 Token 付费访问目录模型(Claude、Llama 等等) |
| FastAPI 服务 | 你的 serve.py 应用:GET /health,POST /run 带上 {"prompt": "..."} |
| App Platform | 托管 FastAPI 容器或 Python buildpack 的地方 |
| Reranking | 重排序检索到的片段,让最相关的段落排到最前面 |
alpha | 检索调节参数:0 纯关键词,1 纯语义,0.5 混合(默认) |
什么是 RAG?
检索增强生成 (RAG) 意味着 LLM 不只靠记忆来回答。你的应用会先从你自己的文档中找到相关段落,然后要求模型仅根据这些材料来回答问题。这样做出的回答,是扎根在案件文件、政策或手册里的,而不是来自通用的训练数据。
可以把它想象成开卷考试:模型拿到问题,同时也拿到你图书馆里正确的几页书,然后带着引用写出答案。
整个流水线有四个阶段。下面的图表展示了它们在这篇教程里是怎么串起来的:
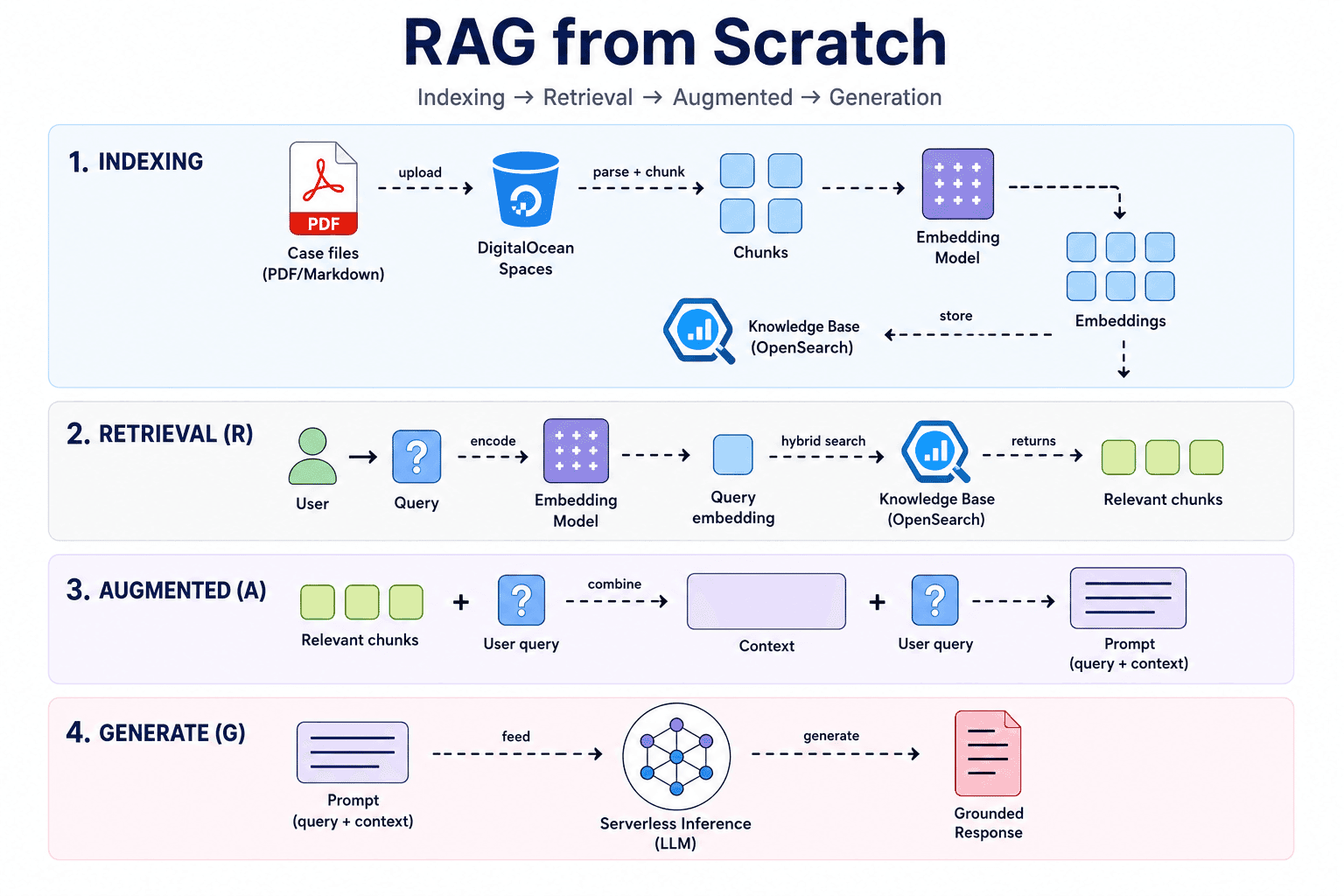
你将构建什么
示例案件文件 (Markdown/PDF)
|
v
DigitalOcean Spaces 存储桶
|
v
Knowledge Base (分块 + 嵌入 + OpenSearch)
|
+-----+-----+
| |
v v
MCP 检索 REST 检索 (生产默认)
https://kbaas.do-ai.run/v1/mcp
|
v
FastAPI RAG 服务 + Serverless Inference (Claude Sonnet 或 Llama)
|
v
App Platform HTTPS URL 用于生产查询
完成之后,你将拥有:
- 一个存放虚构 LegalTech 案件文件的 Spaces 存储桶。
- 一个已索引好、随时可检索的 Knowledge Base。
- 一次针对
retrieve_knowledge_base的成功 MCP 检索调用。 - 一个 FastAPI 服务(
serve.py+rag_core.py),它从 Knowledge Base 检索,再通过 Serverless Inference 作答。 - 一个用 curl 测试过的本地
POST /run端点。 - 同样的服务部署到 App Platform,拥有一个公网 HTTPS URL。
如何使用这篇教程
- 从本文件夹里的
SETUP.md开始,里面有一套编号脚本流水线,你可以逐条复制执行。 - 在运行任何脚本之前,先把
config.env.example复制为config.env。绝对不要把config.env提交到 Git。 - 在做 MCP 测试之前,先等索引完成。根据 Knowledge Base 文档,资源配置通常需要五分钟或更久。
- 在启动 FastAPI 服务之前,先跑通
test_mcp_retrieval.sh。必须先确保检索能正常工作。 - 如果你已经有一个 Knowledge Base,可以直接从 第三步 开始。
仓库结构
Zero-Infrastructure RAG Agent/
├── SETUP.md # 编号操作手册 (从这里开始)
├── config.env.example # 复制为 config.env
├── sample-case-files/ # 虚构 LegalTech Markdown 文件
├── scripts/
│ ├── 01_discover_prerequisites.py # 列出项目 UUID、模型、VPC
│ ├── 02_upload_to_spaces.py # 上传示例文件到 Spaces
│ ├── 03_create_knowledge_base.py # 通过 API 创建知识库
│ ├── 04_wait_for_indexing.py # 轮询直到索引完成
│ ├── 05_test_retrieve_api.sh # REST 检索冒烟测试
│ └── run_all.sh # 按顺序执行步骤 01-06
├── .do/app.yaml # App Platform 规格 (Python buildpack)
└── legaltech-rag-agent/
├── rag_core.py # 检索 + Serverless Inference 逻辑
├── serve.py # FastAPI 应用 (本地 + App Platform)
├── requirements-serve.txt # FastAPI 依赖
└── test_mcp_retrieval.sh # MCP 检索冒烟测试
我也为这篇教程创建了一个 GitHub 仓库:Zero-Infrastructure RAG Agent,你可以克隆它,然后按照 README.md 文件中的步骤操作。
六步概览
| 步骤 | 目标 | 主要命令或路径 |
|---|---|---|
| 0 | 配置密钥 | cp config.env.example config.env |
| 1 | 将案件文件暂存到 Spaces | python3 scripts/02_upload_to_spaces.py |
| 2 | 创建并索引 Knowledge Base | python3 scripts/03_create_knowledge_base.py |
| 3 | 测试 MCP 检索 | ./legaltech-rag-agent/test_mcp_retrieval.sh |
| 4 | 构建 FastAPI RAG 服务 | legaltech-rag-agent/serve.py + rag_core.py |
| 5 | 将服务指向 Serverless Inference | .env + 模型访问密钥 |
| 6 | 本地运行并部署 | uvicorn serve:app → ./scripts/deploy_app_platform.sh |
首先:配置你的环境文件
这篇教程里的所有脚本都从同一个文件读取配置,这样你就不用在不同终端里到处找变量了。
1. 复制模板:
cd "Zero-Infrastructure RAG Agent"
cp config.env.example config.env
2. 打开 config.env,设置以下值:
| 变量 | 去哪里找 |
|---|---|
DIGITALOCEAN_API_TOKEN | API Tokens,需有 genai + GenAI:read 权限 |
DO_PROJECT_ID | 01_discover_prerequisites.sh 的输出 (默认项目 UUID) |
SPACES_ACCESS_KEY_ID | Control Panel → Spaces → Access Keys,或用 MCP spaces-key-create |
SPACES_SECRET_ACCESS_KEY | 创建 Spaces 密钥时一次性显示 |
MODEL_ACCESS_KEY | INFERENCE → Serverless Inference → Model Access Keys |
填写 config.env 文件的示例:
# DigitalOcean API Token (管理资源需要)
DIGITALOCEAN_API_TOKEN=你的_do_api_token_放这里
# 项目 UUID (来自先决条件脚本输出)
DO_PROJECT_ID=你的_项目_uuid_放这里
# Spaces 对象存储访问密钥
SPACES_ACCESS_KEY_ID=你的_spaces_访问密钥_id_放这里
SPACES_SECRET_ACCESS_KEY=你的_spaces_秘密访问密钥_放这里
# Serverless Inference 模型访问密钥
MODEL_ACCESS_KEY=你的_模型_访问密钥_放这里
- 复制并填写所有值。
- 绝对不要把这个文件提交到 Git,也不要分享它的内容。
3. 每个步骤之前,先加载这个文件:
source config.env
模板里已经包含了为本实验验证过的默认值:
EMBEDDING_MODEL_UUID=22652c2a-79ed-11ef-bf8f-4e013e2ddde4(All MiniLM L6 v2)VPC_UUID=db9169a0-e935-4329-9add-3ee52359105a(default-tor1)KB_REGION=tor1
4. 发现你的项目 UUID:
chmod +x scripts/*.sh legaltech-rag-agent/test_mcp_retrieval.sh
./scripts/01_discover_prerequisites.sh
把输出的默认项目 UUID 复制到 config.env 的 DO_PROJECT_ID 中。
步骤 1:上传案件文件到 Spaces 存储桶
你的原始文件存放在 DigitalOcean Spaces 里。Knowledge Base 会从存储桶中拉取文件,并索引它支持的格式(.md、.pdf、.html、.docx 等,详见 Knowledge Base 文档)。
为实验准备示例文件
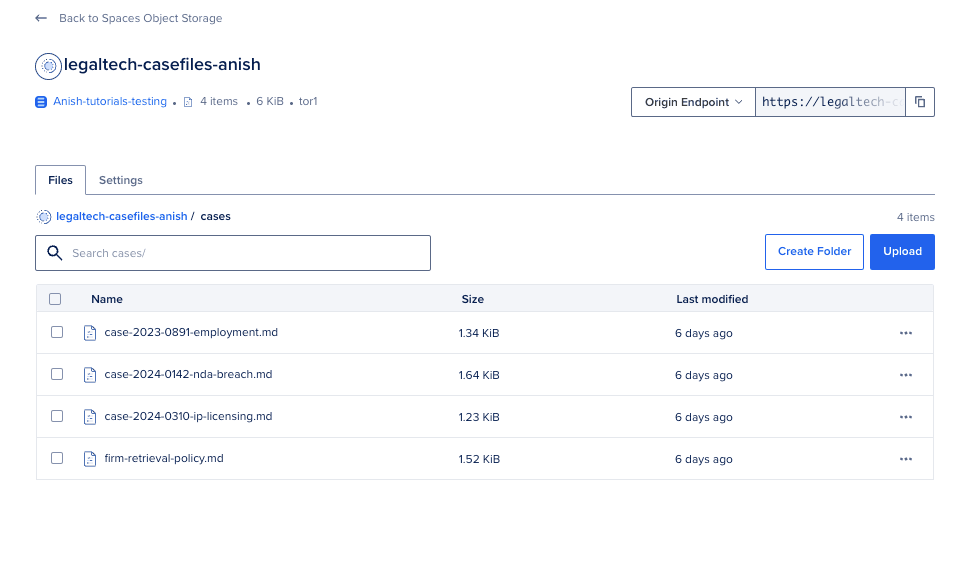
这篇教程在 sample-case-files/ 下包含了四个虚构的 Markdown 文件:
case-2024-0142-nda-breach.mdcase-2023-0891-employment.mdcase-2024-0310-ip-licensing.mdfirm-retrieval-policy.md
对于包含一万个文件的生产级语料库,模式同样适用。建议为每个客户或每个案件类别安排一个存储桶。文档建议每个知识库不要超过五个存储桶,以保证索引性能。
创建一个 Spaces 存储桶
- 打开 Control Panel → Spaces Object Storage → Create Bucket。
- 选择区域。如果你打算在 Agent Platform 中挂载智能体,请使用 TOR1。
- 将存储桶命名为
legaltech-casefiles-tutorial(或者你自己的名字)。 - 把
sample-case-files/里的示例文件上传进去。
用配套的 Python 脚本上传
1. 安装上传依赖:
pip install -r scripts/requirements.txt
2. 运行上传脚本:
source config.env
python3 scripts/02_upload_to_spaces.py
你可以在 legaltech-rag-agent 文件夹中找到 02_upload_to_spaces.py 文件。
这个脚本做了什么: 它用你的 S3 兼容密钥连接到 Spaces,如果存储桶不存在就创建它,然后把所有四个 .md 文件上传到 cases/ 目录下。
预期输出:
Bucket exists: legaltech-casefiles-tutorial
Uploading 4 files to s3://legaltech-casefiles-tutorial/cases/
uploaded cases/case-2024-0142-nda-breach.md
uploaded cases/case-2023-0891-employment.md
uploaded cases/case-2024-0310-ip-licensing.md
uploaded cases/firm-retrieval-policy.md
Upload complete.
每次文件上传就是一个简单的复制,在步骤 2 之前不会发生任何嵌入。
用 DigitalOcean MCP 验证
如果你在 Cursor 中使用 DigitalOcean MCP 服务器,可以用 spaces-key-list 列出 Spaces 访问密钥。如果需要编程上传访问,可以用 spaces-key-create 创建一个专用密钥。
步骤 2:通过 API 创建 Knowledge Base
现在你要把这个存储桶变成一个可搜索的索引。本教程使用 DigitalOcean AI Platform API,这样每一步都能在你的终端上复现。
会创建些什么
API 调用会配置:
- 一个名为
legaltech-cases-kb的 Knowledge Base - 一个在 TOR1 自动配置大小的新 OpenSearch 数据库
- 一个针对你 Spaces 存储桶的索引任务
- 可选的重排序,使用
bge-reranker-v2-m3
选择一个嵌入模型
创建之后就没法再换嵌入模型了。
| 模型 | UUID (目录) | 索引价格 (按文档) |
|---|---|---|
| All MiniLM L6 v2 (实验默认) | 22652c2a-79ed-11ef-bf8f-4e013e2ddde4 | 每 1M Token 0.009 美元 |
| GTE Large EN v1.5 | 22653204-79ed-11ef-bf8f-4e013e2ddde4 | 每 1M Token 0.09 美元 |
| Bge M3 | 78836a83-26d0-11f1-b074-4e013e2ddde4 | 每 1M Token 0.02 美元 |
你可以自己列出模型:
source config.env
curl -sS "https://api.digitalocean.com/v2/gen-ai/models?usecases=MODEL_USECASE_KNOWLEDGEBASE" \
-H "Authorization: Bearer $DIGITALOCEAN_API_TOKEN" | python3 -m json.tool
{
"models": [
{
"uuid": "22652c2a-79ed-11ef-bf8f-4e013e2ddde4",
"name": "All MiniLM L6 v2"
}
]
}
创建 Knowledge Base
1. 运行创建脚本:
source config.env
python3 scripts/03_create_knowledge_base.py
这个脚本做了什么: 它发送 POST https://api.digitalocean.com/v2/gen-ai/knowledge_bases,带上你的 Spaces 存储桶作为数据源,采用基于章节的分块,并启用重排序。成功后,它会将 KNOWLEDGE_BASE_ID 写入 config.env。
2. 检查 JSON 载荷 (用于学习):
脚本发送的主体相当于:
{
"name": "legaltech-cases-kb",
"embedding_model_uuid": "22652c2a-79ed-11ef-bf8f-4e013e2ddde4",
"project_id": "你的_DO_PROJECT_ID",
"region": "tor1",
"vpc_uuid": "db9169a0-e935-4329-9add-3ee52359105a",
"tags": ["legaltech-tutorial"],
"datasources": [
{
"spaces_data_source": {
"bucket_name": "legaltech-casefiles-tutorial",
"region": "tor1"
},
"chunking_algorithm": "CHUNKING_ALGORITHM_SECTION_BASED",
"chunking_options": { "max_chunk_size": 256 }
}
],
"reranking_config": {
"enabled": true,
"model": "bge-reranker-v2-m3"
}
}
3. 预期输出:
Knowledge base created.
ID: 123e4567-e89b-12d3-a456-426614174000
Name: legaltech-cases-kb
Status: provisioning
Saved KNOWLEDGE_BASE_ID to config.env
请把示例 UUID 替换为你账户中的实际值。
替代方案 (仅用 curl): 如果你更喜欢用 shell 而不是 Python 来做创建调用:
source config.env
./scripts/03_create_knowledge_base_curl.sh
你可以在 legaltech-rag-agent 文件夹中找到 03_create_knowledge_base_curl.sh 文件。
curl 脚本会读取 payloads/create_knowledge_base.json,注入你的 DO_PROJECT_ID,并把返回的 UUID 保存到 config.env。
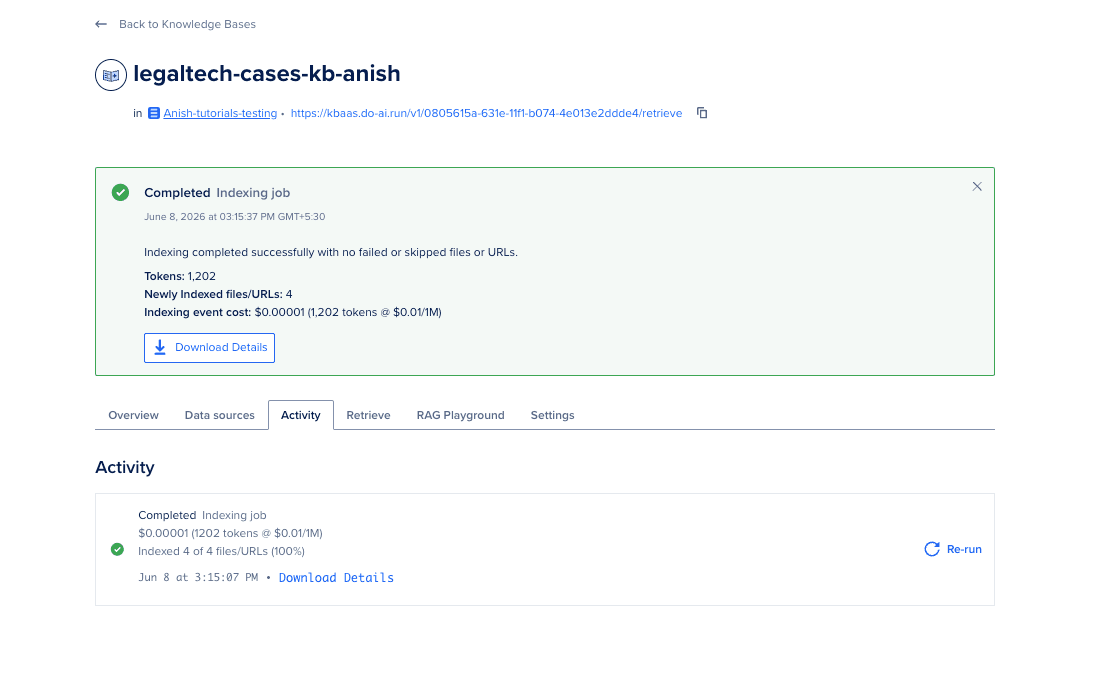
等待索引完成
1. 轮询直到知识库就绪:
source config.env
python3 scripts/04_wait_for_indexing.py
这个脚本每 30 秒检查一次状态,最长持续 45 分钟。
2. 在 Control Panel 中确认 (可选):
Data Services → Knowledge bases → legaltech-cases-kb → Activity
状态值包括 Completed、Partially Completed 和 Failed。
在 MCP 之前先测试 REST 检索
source config.env
./scripts/05_test_retrieve_api.sh
传入自定义查询:
./scripts/05_test_retrieve_api.sh "案件 2024-0310 的诉讼预算是多少?"
好的响应长什么样: JSON 中 total_results 大于零,并且片段里提到了 $320,000 或 Lumen Bio。
Control Panel 替代方案 (可选)
你也可以在 Control Panel 里手动创建知识库。如果你更喜欢 UI 操作,可以跳过 03_create_knowledge_base.py,按以下步骤手动创建:
- Data Services → Knowledge bases → Create Knowledge Base
- 选择一个嵌入模型,可选重排序模型
- Pull from a Spaces bucket or folder → 选择
legaltech-casefiles-tutorial - 在 TOR1 中 Create new OpenSearch 数据库
- 点击 Create knowledge base
然后从下面这个地址复制 UUID:
https://cloud.digitalocean.com/agent-platform/knowledge-bases/{UUID}
把它加到 config.env:
export KNOWLEDGE_BASE_ID="你的_uuid_放这里"
用 API 列出知识库:
curl -sS -X GET "https://api.digitalocean.com/v2/gen-ai/knowledge_bases" \
-H "Authorization: Bearer $DIGITALOCEAN_API_TOKEN" | python3 -m json.tool
你也可以在 Control Panel 里运行查询:

你将得到以下输出:
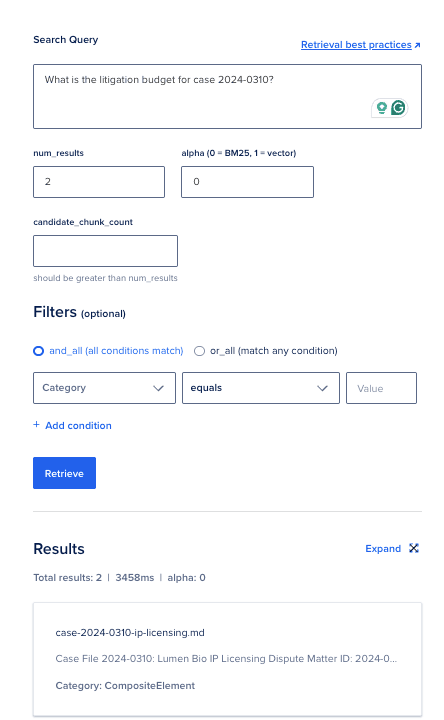
你可以展开结果:

步骤 3:启用 MCP 集成并测试检索
Knowledge Bases 通过一个专用的 MCP 服务器提供了检索能力。这个端点独立于通用的 DigitalOcean MCP 服务器(Droplets、Apps 等)。它的 URL 是:
https://kbaas.do-ai.run/v1/mcp
认证需要一个拥有 GenAI:read 权限的个人访问令牌。通过 MCP 检索的计费方式与直接检索 API 调用相同,详情见 定价文档。
支持的 MCP 工具
| 工具 | 用途 |
|---|---|
retrieve_knowledge_base | 对单个知识库进行混合搜索,返回 1 到 25 个结果 |
参数:
knowledge_base_id(必需): 你的 UUIDquery(必需): 律师的问题文本num_results(必需): 1 到 25 之间alpha(可选): 默认0.5混合模式filters(可选): 对item_name、page_number等字段的元数据过滤
完整参考:Knowledge Bases MCP 工具。
在 Cursor 中配置 MCP (可选)
根据 配置远程 MCP,将以下内容块添加到你的 MCP 客户端配置中:
{
"mcpServers": {
"knowledge-bases": {
"url": "https://kbaas.do-ai.run/v1/mcp",
"headers": {
"Authorization": "Bearer <你的_拥有_genai_read_权限的_api_token>"
}
}
}
}
用配套的 Shell 脚本做冒烟测试
在 legaltech-rag-agent/ 目录下:
export DIGITALOCEAN_API_TOKEN="你的_token"
export KNOWLEDGE_BASE_ID="你的_kb_uuid"
./test_mcp_retrieval.sh
预期输出如下:
Initializing MCP session...
event: message
data: {"jsonrpc":"2.0","id":1,"result":{"capabilities":{"logging":{},"tools":{"listChanged":true}},"instructions":"DigitalOcean Knowledge Bases MCP server. Use the retrieve_knowledge_base tool to search knowledge bases by UUID.","protocolVersion":"2025-03-26","serverInfo":{"name":"digitalocean-knowledge-bases","version":"1.0.0"}}}
Calling retrieve_knowledge_base...
event: message
data: {"jsonrpc":"2.0","id":2,"result":{"content":[{"type":"text","text":"Found 3 result(s):\n\n--- Result 1 ---\nCase File 2024-0142: Meridian Analytics NDA Breach\n\nMatter ID: 2024-0142 Client: Northwind Logistics LLC Opposing Party: Meridian Analytics Inc. Jurisdiction: Delaware Chancery Court Filed: 2024-03-18 Status: Discovery\n\nSummary\n\nNorthwind Logistics alleges Meridian Analytics disclosed confidential pricing models and customer pipeline data to a competitor after signing a mutual NDA on 2023-11-02.\nMetadata: map[chunk_category:CompositeElement ingested_timestamp:2026-06-08T09:45:23.292831+00:00 item_name:case-2024-0142-nda-breach.md page_number:\u003cnil\u003e]\n\n--- Result 2 ---\nSolo Founders Legal AI Retrieval Policy\n\nEffective: 2024-06-01 Owner: Founding partner Applies to: Internal case research assistant\n\nPurpose\n\nThis policy defines how the firm's AI assistant retrieves answers from internal case files stored in DigitalOcean Knowledge Bases.\n\nAllowed Uses\n\nSummarize matter status for attorneys assigned to the matter.\n\nSurface procedural deadlines from indexed case files.\n\nDraft internal research memos with source citations.\n\nProhibited Uses\n\nDo not use the assistant for client-facing advice without attorney review.\n\nDo not query across matters without explicit matter ID in the prompt.\n\nDo not upload client PII to non-production workspaces.\nMetadata: map[chunk_category:CompositeElement ingested_timestamp:2026-06-08T09:45:24.015805+00:00 item_name:firm-retrieval-policy.md page_number:\u003cnil\u003e]\n\n--- Result 3 ---\nClaims\n\nCalifornia Labor Code retaliation (whistleblower).\n\nFEHA retaliation.\n\nBreach of implied covenant of good faith.\n\nDamages Sought\n\nLost wages and benefits: $410,000 through trial date.\n\nEmotional distress: $150,000.\n\nPunitive damages requested if malice shown.\n\nDiscovery Status\n\nReceived personnel file 2024-01-05.\n\nPending IT logs for ethics portal submission timestamp.\n\nDeposition of HR director Denise Park set for 2024-08-14.\n\nSettlement Range (Internal)\n\nMediator brief suggests opening demand $650,000, expected bracket $275,000 to $425,000. Privileged.\nMetadata: map[chunk_category:CompositeElement ingested_timestamp:2026-06-08T09:45:19.820378+00:00 item_name:case-2023-0891-employment.md page_number:\u003cnil\u003e]\n\n"}],"structuredContent":{"results":[{"metadata":{"chunk_category":"CompositeElement","ingested_timestamp":"2026-06-08T09:45:23.292831+00:00","item_name":"case-2024-0142-nda-breach.md","page_number":null},"text_content":"Case File 2024-0142: Meridian Analytics NDA Breach\n\nMatter ID: 2024-0142 Client: Northwind Logistics LLC Opposing Party: Meridian Analytics Inc. Jurisdiction: Delaware Chancery Court Filed: 2024-03-18 Status: Discovery\n\nSummary\n\nNorthwind Logistics alleges Meridian Analytics disclosed confidential pricing models and customer pipeline data to a competitor after signing a mutual NDA on 2023-11-02."},{"metadata":{"chunk_category":"CompositeElement","ingested_timestamp":"2026-06-08T09:45:24.015805+00:00","item_name":"firm-retrieval-policy.md","page_number":null},"text_content":"Solo Founders Legal AI Retrieval Policy\n\nEffective: 2024-06-01 Owner: Founding partner Applies to: Internal case research assistant\n\nPurpose\n\nThis policy defines how the firm's AI assistant retrieves answers from internal case files stored in DigitalOcean Knowledge Bases.\n\nAllowed Uses\n\nSummarize matter status for attorneys assigned to the matter.\n\nSurface procedural deadlines from indexed case files.\n\nDraft internal research memos with source citations.\n\nProhibited Uses\n\nDo not use the assistant for client-facing advice without attorney review.\n\nDo not query across matters without explicit matter ID in the prompt.\n\nDo not upload client PII to non-production workspaces."},{"metadata":{"chunk_category":"CompositeElement","ingested_timestamp":"2026-06-08T09:45:19.820378+00:00","item_name":"case-2023-0891-employment.md","page_number":null},"text_content":"Claims\n\nCalifornia Labor Code retaliation (whistleblower).\n\nFEHA retaliation.\n\nBreach of implied covenant of good faith.\n\nDamages Sought\n\nLost wages and benefits: $410,000 through trial date.\n\nEmotional distress: $150,000.\n\nPunitive damages requested if malice shown.\n\nDiscovery Status\n\nReceived personnel file 2024-01-05.\n\nPending IT logs for ethics portal submission timestamp.\n\nDeposition of HR director Denise Park set for 2024-08-14.\n\nSettlement Range (Internal)\n\nMediator brief suggests opening demand $650,000, expected bracket $275,000 to $425,000. Privileged."}],"total_results":3}}}
脚本做了两次调用:
initializeMCP 会话。tools/call调用retrieve_knowledge_base,查询案件 2024-0142 的状态是什么?。
好的响应长什么样: JSON 中 total_results 大于零,并且片段里提到了案件 2024-0142 或 Meridian Analytics NDA 违约摘要。每个结果都应包含 text_content 和诸如 source 或 page 等 metadata。
如果你看到零结果: 索引可能还在跑,存储桶路径可能错了,或者对于精确的案件 ID 关键词匹配,查询可能需要调低 alpha。首先检查 Activity 标签页。对于重度依赖 ID 的查找,试试 alpha: 0。
手动 curl 示例 (单次调用)
curl -sS -X POST "https://kbaas.do-ai.run/v1/mcp" \
-H "Content-Type: application/json" \
-H "Accept: application/json, text/event-stream" \
-H "Authorization: Bearer $DIGITALOCEAN_API_TOKEN" \
-d '{
"jsonrpc": "2.0",
"id": 3,
"method": "tools/call",
"params": {
"name": "retrieve_knowledge_base",
"arguments": {
"knowledge_base_id": "你的_KB_UUID",
"query": "案件 2024-0142 里要求了什么赔偿?",
"num_results": 5,
"alpha": 0.5
}
}
}' | sed -n 's/^data: //p' | jq '.result.structuredContent'
每行一个源文件:
curl -sS ... | sed -n 's/^data: //p' | jq '.result.structuredContent.results[] | {item_name: .metadata.item_name, text_content}'
{
"results": [
{
"metadata": {
"chunk_category": "CompositeElement",
"ingested_timestamp": "2026-06-08T09:45:23.292831+00:00",
"item_name": "case-2024-0142-nda-breach.md",
"page_number": null
},
"text_content": "Case File 2024-0142: Meridian Analytics NDA Breach\n\nMatter ID: 2024-0142 Client: Northwind Logistics LLC Opposing Party: Meridian Analytics Inc. Jurisdiction: Delaware Chancery Court Filed: 2024-03-18 Status: Discovery\n\nSummary\n\nNorthwind Logistics alleges Meridian Analytics disclosed confidential pricing models and customer pipeline data to a competitor after signing a mutual NDA on 2023-11-02."
},
{
"metadata": {
"chunk_category": "CompositeElement",
"ingested_timestamp": "2026-06-08T09:45:23.292831+00:00",
"item_name": "case-2024-0142-nda-breach.md",
"page_number": null
},
"text_content": "Key Facts\n\nNDA executed on 2023-11-02 with a 24-month confidentiality term.\n\nJoint evaluation period ran from 2023-11-15 through 2024-01-30.\n\nOn 2024-02-14, Northwind learned Meridian shared a slide deck containing Northwind unit economics with Apex Data Systems.\n\nThe slide deck filename was Northwind_Pricing_v3_confidential.pptx.\n\nMeridian employee Sarah Chen sent the file via personal Gmail on 2024-02-09.\n\nDamages Claimed\n\nLost enterprise contract with Harbor Freight Group: $1.2M annual value.\n\nRemediation and audit costs: $84,000.\n\nInjunctive relief requested to stop further disclosure."
},
{
"metadata": {
"chunk_category": "CompositeElement",
"ingested_timestamp": "2026-06-08T09:45:24.015805+00:00",
"item_name": "firm-retrieval-policy.md",
"page_number": null
},
"text_content": "Solo Founders Legal AI Retrieval Policy\n\nEffective: 2024-06-01 Owner: Founding partner Applies to: Internal case research assistant\n\nPurpose\n\nThis policy defines how the firm's AI assistant retrieves answers from internal case files stored in DigitalOcean Knowledge Bases.\n\nAllowed Uses\n\nSummarize matter status for attorneys assigned to the matter.\n\nSurface procedural deadlines from indexed case files.\n\nDraft internal research memos with source citations.\n\nProhibited Uses\n\nDo not use the assistant for client-facing advice without attorney review.\n\nDo not query across matters without explicit matter ID in the prompt.\n\nDo not upload client PII to non-production workspaces."
},
{
"metadata": {
"chunk_category": "CompositeElement",
"ingested_timestamp": "2026-06-08T09:45:23.656377+00:00",
"item_name": "case-2024-0310-ip-licensing.md",
"page_number": null
},
"text_content": "Case File 2024-0310: Lumen Bio IP Licensing Dispute\n\nMatter ID: 2024-0310 Client: Lumen Bio Therapeutics Counterparty: Helix Research Partners Jurisdiction: SDNY Filed: 2024-05-03 Status: Motion to dismiss pending\n\nSummary\n\nLumen Bio seeks declaratory judgment that its CRISPR delivery method does not infringe Helix Patent US-10,998,221 after Helix sent a cease-and-desist letter on 2024-04-11.\n\nPatent at Issue\n\nPatent: US-10,998,221\n\nTitle: Lipid nanoparticle formulations for guide RNA delivery\n\nPriority date: 2017-06-14\n\nLumen Position\n\nLumen uses a distinct PEGylation ratio (8:1 vs Helix claimed 4:1).\n\nPrior art reference WO2018/044112 anticipates claims 1-4.\n\nNo licensing agreement exists between parties."
},
{
"metadata": {
"chunk_category": "CompositeElement",
"ingested_timestamp": "2026-06-08T09:45:19.820378+00:00",
"item_name": "case-2023-0891-employment.md",
"page_number": null
},
"text_content": "Claims\n\nCalifornia Labor Code retaliation (whistleblower).\n\nFEHA retaliation.\n\nBreach of implied covenant of good faith.\n\nDamages Sought\n\nLost wages and benefits: $410,000 through trial date.\n\nEmotional distress: $150,000.\n\nPunitive damages requested if malice shown.\n\nDiscovery Status\n\nReceived personnel file 2024-01-05.\n\nPending IT logs for ethics portal submission timestamp.\n\nDeposition of HR director Denise Park set for 2024-08-14.\n\nSettlement Range (Internal)\n\nMediator brief suggests opening demand $650,000, expected bracket $275,000 to $425,000. Privileged."
}
],
"total_results": 5
}
将检索过滤到单个案件文件
当律师只处理一个案件时,可以通过文件名元数据来过滤:
{
"filters": {
"equals": {
"key": "item_name",
"value": "case-2024-0142-nda-breach.md"
}
}
}
这个模式与 Control Panel 中 Retrieve 标签页的过滤器一致,具体描述见 测试知识库检索文档。
步骤 4:构建 FastAPI RAG 服务
在步骤 3 确认检索功能正常后,接下来把 Knowledge Base 检索和 Serverless Inference 接入一个小小的 FastAPI 应用。这个服务就是你本地跑、然后部署到 App Platform 上的那个东西。
理解服务流程
POST /run {"prompt": "..."}
-> Knowledge Base 检索 (默认用 REST API)
-> 将片段格式化为上下文
-> Serverless Inference 聊天补全
-> {"response": "...", "retrieval_preview": "..."}
步骤 3 证明了 MCP 检索可行。托管服务使用 Knowledge Base 检索 REST API (RETRIEVAL_MODE=rest),因为它在生产中更稳定。只有当你需要在应用代码中体验 MCP 传输时,才设置 RETRIEVAL_MODE=mcp。
核心模块
| 文件 | 角色 |
|---|---|
rag_core.py | 检索 (retrieve_context_rest 或 retrieve_context_mcp)、生成 (generate_answer) 和 run_rag() |
serve.py | FastAPI 应用:GET /health、POST /run |
requirements-serve.txt | FastAPI、uvicorn、httpx、LangChain 客户端 |
1. Serverless Inference 客户端 (rag_core.py)
# 这是你的代码中如何初始化 Serverless Inference 客户端的示例。
# 你会在 `rag_core.py` 中找到(或需要添加)这段代码,该文件位于 `legaltech-rag-agent/` 目录下。
# 寻找一个设置语言模型客户端的函数(它可能在 `generate_answer()` 或类似函数内部被调用)。
# rag_core.py 中的用法示例:
from langchain_openai import ChatOpenAI
import os
llm = ChatOpenAI(
model=os.environ.get("INFERENCE_MODEL", "anthropic-claude-sonnet-4"),
api_key=os.environ.get("MODEL_ACCESS_KEY"),
base_url="https://inference.do-ai.run/v1",
temperature=0.1,
max_tokens=800,
)
注意: 你不能直接在终端或 Notebook 里跑这段代码。这个 Python 代码是 FastAPI 后端的一部分——已包含(或将包含)在 rag_core.py 中。
MODEL_ACCESS_KEY 是 Serverless Inference 的凭证。建议从 INFERENCE → Serverless Inference → Create a Model Access Key 创建一个专用密钥。如果你账户上的模型密钥 API 已下线,在实验环境中,一个拥有推理访问权限的个人访问令牌也可以当作 MODEL_ACCESS_KEY 使用。
2. REST 检索 (生产默认)
await client.post(
f"https://kbaas.do-ai.run/v1/{kb_id}/retrieve",
headers={"Authorization": f"Bearer {token}", ...},
json={"query": query, "num_results": num_results, "alpha": alpha},
)
3. FastAPI 端点 (serve.py)
@app.get("/health")
async def health() -> dict[str, str]:
return {"status": "ok"}
@app.post("/run")
async def run(body: RunRequest) -> dict[str, Any]:
return await run_rag(body.prompt.strip())
你的应用调用 POST /run 并带上 {"prompt": "你的问题"}。响应会包含带来源引用的答案,以及一个用于调试的截断版 retrieval_preview。
环境文件
在 legaltech-rag-agent/ 里面把 .env.example 复制为 .env:
cd legaltech-rag-agent
cp .env.example .env
设置以下值(从 config.env 里复制 KNOWLEDGE_BASE_ID 和 Token):
MODEL_ACCESS_KEY=你的_model_access_key
DIGITALOCEAN_API_TOKEN=你的_个人访问_token
KNOWLEDGE_BASE_ID=你的_知识库_uuid
INFERENCE_MODEL=anthropic-claude-sonnet-4
RETRIEVAL_MODE=rest
NUM_RESULTS=5
RETRIEVAL_ALPHA=0.5
.env 已加入 gitignore,绝对不要提交 Token。
安装依赖并在本地运行
cd legaltech-rag-agent
pip install -r requirements-serve.txt
set -a && source .env && set +a
uvicorn serve:app --host 0.0.0.0 --port 8080
启动示例:
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
INFO: Started server process
INFO: Waiting for application startup.
INFO: Application startup complete.
确认健康状态:
curl http://localhost:8080/health
{"status":"ok"}
用 curl 测试:
curl -X POST http://localhost:8080/run \
-H "Content-Type: application/json" \
-d '{"prompt": "总结一下案件 2023-0891,并列出下一次作证日期。"}'
上面 curl 命令的输出:
{
"response": "根据检索到的案件文件上下文,针对案件 ID 2023-0891:\n\n## 案件摘要 - 案件 ID 2023-0891\n\n• **客户**:Jordan Ellis 诉 Vega Software Corp.\n• **案件类型**:不当解雇/报复索赔\n• **立案日期**:2023-09-12,加州高等法院,旧金山县\n• **当前状态**:已安排调解\n\n## 关键事实\n• Ellis 是一名高级产品经理,于 2021-04-19 入职\n• 于 2023-08-30 被解雇(理由为“绩效重组”)\n• Ellis 于 2023-07-22 提交了内部道德报告,涉及向阿联酋经销商项目发送未授权加密模块\n• 解雇发生在举报后 39 天\n• 遣散费方案:8 周薪资,需签署广泛的免责协议\n\n## 索赔\n• 加州劳工法典报复(举报人)\n• FEHA 报复\n• 违反诚信与公平交易的默示契约\n\n## 下一次作证日期\n• **人力资源总监 Denise Park 的作证定于 2024-08-14**\n\n## 索赔金额\n• 工资和福利损失:410,000 美元\n• 精神损害赔偿:150,000 美元\n• 如能证明恶意,将要求惩罚性赔偿\n\n*来源:案件 ID 2023-0891, case-2023-0891-employment.md*",
"retrieval_preview": "{\n \"results\": [\n {\n \"metadata\": {\n \"chunk_category\": \"CompositeElement\",\n \"ingested_timestamp\": \"2026-06-08T09:45:19.820378+00:00\",\n \"item_name\": \"case-2023-0891-employment.md\",\n \"page_number\": null\n },\n \"text_content\": \"Case File 2023-0891: Vega Software Wrongful Termination\\n\\nMatter ID: 2023-0891 Client: Jordan Ellis Employer: Vega Software Corp. ...\"\n }\n ]\n}",
"knowledge_base_id": "0805615a-631e-11f1-b074-4e013e2ddde4",
"model": "anthropic-claude-sonnet-4",
"retrieval_mode": "rest"
}
预期行为: 如果那些片段排名靠前,响应中应提及 Vega Software、Jordan Ellis 以及 2024-08-14 的人力资源总监作证。
步骤 5:将智能体指向 Serverless Inference 模型
检索质量和答案质量是分开的选择。你在这里为生成环节挑选推理模型。
注意:你不需要部署 Serverless Inference 实例
如果你以为要在 Control Panel 里找到一个新建的 GPU 或推理应用,这很正常,是个常见的误解。Serverless Inference 的配置方式跟 Dedicated Inference 或 App Platform 不一样。
| 你在本教程中部署的东西 | 你只是通过 HTTPS 调用的东西 |
|---|---|
| Spaces 存储桶、Knowledge Base、App Platform 上的 FastAPI | Serverless Inference 在 https://inference.do-ai.run/v1 |
在每次 POST /run 时,你的 FastAPI 服务都会执行两个独立的步骤:
- 检索 — Knowledge Base API (
DIGITALOCEAN_API_TOKEN) 找到相关的案件文件片段。 - 生成 — Serverless Inference API (
MODEL_ACCESS_KEY) 将这些片段加上用户问题,转化为自然语言答案。
DigitalOcean 为所有客户运行共享的模型集群,你不需要预留 GPU 小时。你只需创建一个 Model Access Key,在 .env 里设置 INFERENCE_MODEL,当用户提问时,你的代码就去调用 API。计费按 Token,遵循 Serverless Inference 定价。
在 Control Panel 的 INFERENCE → Serverless Inference 下,你看到的是模型目录和模型访问密钥,而不是“创建实例”的按钮。在你的应用调用 inference.do-ai.run 之后,Token 用量会出现在推理用量和账单里。Knowledge Base 检索是单独计费的(嵌入和可选的重排序 Token)。
对于需要私有 GPU 的稳定生产流量,可以使用DigitalOcean的 专用推理服务(Dedicated Inference)。如果需要自己训练微调模型,可使用DigitalOcean的 GPU Droplet云服务器(H200、H100等)。本教程使用无服务器推理(Serverless Inference),因为法律研究查询是突发性的,按 Token 付费对初次部署来说更简单。
选择一个模型
| 模型 | 输入 / 输出 (根据文档) |
|---|---|
| Claude Sonnet 4.6 | $3.00 / $15.00 每 1M Token (≤200K 提示) |
| Llama 3.3 Instruct 70B | $0.65 / $0.65 每 1M Token |
用 DigitalOcean MCP 的 inference-model-catalog-search 工具或 Control Panel 的 Model Catalog 来列出模型。在准备教程时,搜索 claude sonnet 会返回 Anthropic Claude Sonnet 4 以及相关目录条目的 UUID。
在 .env 里设置模型 slug:
INFERENCE_MODEL=anthropic-claude-sonnet-4.6
创建或复制一个 Model Access Key
INFERENCE → Serverless Inference → Model Access Keys → Create Access Key
为本地运行导出:
export MODEL_ACCESS_KEY="你的_key"
直接 Serverless Inference 冒烟测试 (可选)
curl -X POST "https://inference.do-ai.run/v1/chat/completions" \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic-claude-sonnet-4",
"messages": [{"role": "user", "content": "回复 READY"}],
"max_tokens": 10
}'
示例输出 (来自 Control Panel 的专用 Model Access Key):
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "READY",
"role": "assistant"
}
}
],
"model": "anthropic-claude-sonnet-4",
"object": "chat.completion",
"usage": {
"completion_tokens": 5,
"prompt_tokens": 11,
"total_tokens": 16
}
}
如果这个请求报 401,请先修好模型访问密钥,再去调试 MCP。
步骤 6:将 FastAPI 服务部署到 App Platform
本地的 uvicorn 证明了 RAG 流水线是通的。App Platform 会给你一个你的产品可以调用的公网 HTTPS URL。
先确认本地健康状态
在 uvicorn 仍在运行的情况下(或从步骤 4 重新启动它):
curl http://localhost:8080/health
# {"status":"ok"}
用配套脚本部署
仓库里自带了 .do/app.yaml(Python buildpack,source_dir: legaltech-rag-agent)和 scripts/deploy_app_platform.sh,后者会从 config.env 注入密钥,然后创建或更新应用。
1. 把仓库推送到 GitHub (App Platform 从 Git 克隆):
# 一次性:创建一个公开仓库并推送(密钥留在 config.env 里,不进 Git)
gh repo create legaltech-rag-agent --public --source=. --remote=origin --push
2. 部署:
source config.env
./scripts/deploy_app_platform.sh
脚本会写入 .do/app.deploy.yaml(已 gitignore),运行 doctl apps create 或 doctl apps update,然后打印应用 URL。
手动替代方案:
source config.env
# 编辑 .do/app.yaml:设置 KNOWLEDGE_BASE_ID 和密钥占位符,然后:
doctl apps create --spec .do/app.deploy.yaml --project-id "$DO_PROJECT_ID"
App Platform 上必需的运行时环境变量:
| 变量 | 用途 |
|---|---|
MODEL_ACCESS_KEY | Serverless Inference (密钥) |
DIGITALOCEAN_API_TOKEN | Knowledge Base 检索 API (密钥) |
KNOWLEDGE_BASE_ID | 你的知识库 UUID |
INFERENCE_MODEL | 例如 anthropic-claude-sonnet-4 |
RETRIEVAL_MODE | 托管部署用 rest |
NUM_RESULTS / RETRIEVAL_ALPHA | 检索调优参数 |
测试线上端点
把主机名换成你的 App Platform 默认入口:
curl https://legaltech-rag-agent-jjd7r.ondigitalocean.app/health
curl -X POST https://legaltech-rag-agent-jjd7r.ondigitalocean.app/run \
-H "Content-Type: application/json" \
-d '{"prompt": "有哪些雇佣案件涉及不当解雇?"}' | jq .
示例健康响应:
{"status":"ok"}
上面 curl 命令的输出:
{
"response": "根据检索到的案件文件,我找到了一个涉及不当解雇的雇佣案件:\n\n• **案件 ID 2023-0891** - Vega Software 不当解雇案\n - 客户:Jordan Ellis\n - 雇主:Vega Software Corp.\n - 立案日期:2023-09-12\n - 索赔:加州劳工法典报复(举报人)、FEHA 报复,以及违反诚信与公平交易的默示契约\n - 指控:因举报出口管制违规行为而遭到报复性不当解雇\n - 时间线:Ellis 于 2023-07-22 报告道德违规,于 2023-08-30(39 天后)被解雇\n - 状态:已安排调解\n\n这是提供的已索引资料中唯一一个涉及不当解雇的雇佣案件。",
"retrieval_preview": "{\n \"results\": [\n {\n \"metadata\": {\n \"chunk_category\": \"CompositeElement\",\n \"ingested_timestamp\": \"2026-06-08T09:45:19.820378+00:00\",\n \"item_name\": \"case-2023-0891-employment.md\",\n \"page_number\": null\n },\n \"text_content\": \"Case File 2023-0891: Vega Software Wrongful Termination\\n\\nMatter ID: 2023-0891 Client: Jordan Ellis Employer: Vega Software Corp. Jurisdiction: California Superior Court, San Francisco County Filed: 2023-09-12 Status: Mediation scheduled\\n\\nSummary\\n\\nJordan Ellis, a senior product manager, alleges wrongful termination in retaliation for reporting export control violations related to Vega's UAE reseller program.\\n\\nKey Facts\\n\\nHire date: 2021-04-19.\\n\\nTermination date: 2023-08-30, cited as \\\"performance restructuring.\\\"\\n\\nEllis submitted an internal ethics report on 2023-07-22 regarding unlicensed encryption module shipments.\\n\\nVega eliminated Ellis's role 39 days after the report.\\n\\nSeverance offer: 8 weeks pay with broad release.\"\n },\n {\n \"metadata\": {\n \"chunk_category\": \"CompositeElement\",\n \"ingested_timestamp\": \"2026-06-08T09:45:19.820378+00:00\",\n \"item_name\": \"case-2023-0891-e",
"knowledge_base_id": "0805615a-631e-11f1-b074-4e013e2ddde4",
"model": "anthropic-claude-sonnet-4",
"retrieval_mode": "rest"
}
部署成功后,你会得到一个带案件 ID、有据可查的答案,这些信息来自你已索引的案件文件。
当精度不够时调优重排序
如果答案引用了错误的案件:
- 在 Control Panel 中打开知识库的 Settings 标签页。
- 确认重排序已启用,并选中了你选择的重排序模型。
- 用同样的查询再次请求
POST /run,检查retrieval_preview。 - 收紧提示词,加入明确的案件 ID。
- 在
rag_core.py中为单案件会话添加item_name过滤器。
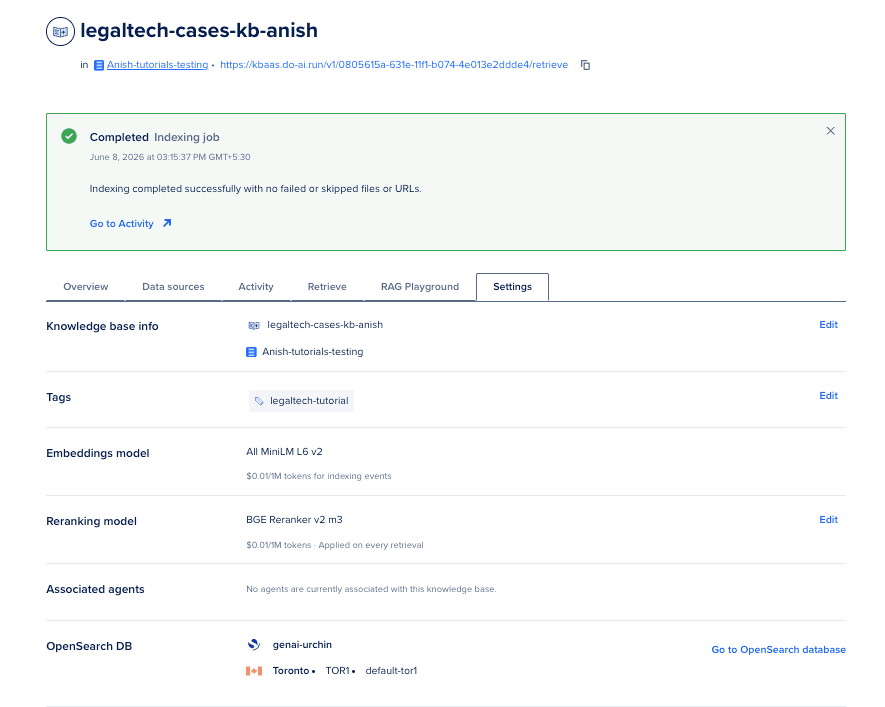
你可以查看 重排序文档 获取更多细节。
可观测性
你可以观察以下内容:
- App Platform: 在 Apps → 你的应用 → Runtime Logs 下查看运行时日志。
- 检索调试: 每次
POST /run的响应都包含retrieval_preview(已检索 JSON 的前 1200 个字符)。 - Control Panel: Knowledge bases → Retrieve 标签页,用于在不打到你应用的情况下做一次性检索测试。
个人创业者的成本概算
这些数字来自 DigitalOcean Inference 定价。你的账单取决于文件大小、查询量和模型选择。
| 计费项 | 示例计算 | 备注 |
|---|---|---|
| 初始索引 | 10 MB 语料 ≈ 3M Token × $0.009/1M ≈ $0.03,使用 all-mini-lm-l6-v2 | 随 Token 线性增长 |
| OpenSearch 存储 | 取决于集群大小 | 见 OpenSearch 定价 |
| 检索查询 | 每次 MCP 调用向量化 1 个查询 | 通过 MCP 或 REST 价格相同 |
| 重排序 | 启用时按重排序 Token 计费 | BGE Reranker v2 m3 每 1M Token 0.01 美元 |
| 答案生成 | Sonnet 4.6 上 2K 输入 + 500 输出 Token ≈ 每个答案 $0.0135 | (($3×2) + ($15×0.5)) / 1000 |
遇到问题时
以下是我在开发这个应用时亲身遇到的一些常见问题及其解决方案。
| 现象 | 可能原因 | 尝试方法 |
|---|---|---|
MCP 401 | Token 缺少 GenAI:read | 创建一个具有正确权限的新 Token |
retrieve_knowledge_base 返回 0 个片段 | 索引未完成或存储桶错误 | 检查 Activity 标签页,重新运行索引 |
| 答案引用了错误案件 | 混合搜索范围太宽 | 降低温度,添加 item_name 过滤器,启用重排序 |
| App Platform 构建失败 | 缺少 requirements-serve.txt 或 source_dir 错误 | 确认 .do/app.yaml 指向 legaltech-rag-agent |
POST /run 在 App Platform 上返回 500 | 缺少环境变量 | 在应用规格中设置 KNOWLEDGE_BASE_ID、MODEL_ACCESS_KEY 和 DIGITALOCEAN_API_TOKEN |
| 应用健康检查失败 | 服务未监听 8080 端口 | http_port: 8080 和 uvicorn ... --port 8080 必须匹配 |
知识库创建 400 错误在 max_chunk_size 上 | 值超过嵌入模型限制 | 对 All MiniLM L6 v2 使用 256(而非 500) |
模型报 401 错误 | 混淆了 API Token 和模型访问密钥 | 推理只用 MODEL_ACCESS_KEY |
| 首次查询很慢 | 索引冷启动或 num_results 过大 | 从 num_results: 5 开始,分析性能后再增加 |
| 上传停滞 | 批次太大 | 每批上传少于 100 个文件,且总大小低于 2 GB |
清理(停止实验计费)
- 删除 App Platform 应用:Apps → 你的应用 → Destroy。
- 删除知识库:Knowledge bases → … → Destroy(会销毁关联的数据源和索引)。
- 如果你创建了一个专用的 OpenSearch 数据库且不再需要,删除它。
- 当你不再需要原始文件时,删除 Spaces 存储桶。
- 撤销用于教程的 API Token 和模型访问密钥。
OpenSearch 集群和已存储的嵌入只要资源还在,就会持续产生费用。你可以从 Control Panel 中删除它们。
常见问题
1. Knowledge Bases MCP 和 DigitalOcean MCP 服务器有什么区别?
DigitalOcean MCP 服务器 管理 DO 基础设施,比如 Droplets、Apps 和 Spaces 密钥。位于 https://kbaas.do-ai.run/v1/mcp 的 Knowledge Bases MCP 端点 仅包含用于已索引知识库的检索工具。你需要分开配置它们。
2. 如果我用了 Knowledge Bases,还需要 LangChain 或 Chroma 吗?
走这条路,你不需要 Chroma 或自托管向量数据库。你仍然可以在智能体代码里用 LangChain,如果你想用 LangChain 智能体的话,但检索是通过 Knowledge Bases 在 DigitalOcean 托管的 OpenSearch 上运行的。
3. MCP 检索是如何计费的?
通过 MCP 检索的计费方式与检索 API 相同,包括查询向量化 Token 和可选的重排序 Token,详情可咨询卓普云(aidroplet..com)。
4. 我应该在什么时候启用重排序?
当召回率看起来不错,但排序顺序不对时,就该启用重排序。这种情况常见于案件标题和当事人名称有重叠的时候。每次检索调用你都需要为额外的重排序 Token 付费。
5. 我可以用 Dedicated Inference 代替 Serverless 吗?
可以,如果你需要一个私有的 GPU 端点来做答案生成。Knowledge Base 检索仍然留在托管 Knowledge Bases 服务上。很多个人创业者从 Serverless 开始(Claude Sonnet 4.6 每百万输入 Token 3.00 美元),当流量稳定后再把生成迁移到 Dedicated。参见 无服务器推理 vs 专用推理。
6. 我怎样才能在一万多份文件中做实据支撑,又不把 Token 预算花光?
把 num_results 保持在 5 到 8 之间,当案件已知时用 item_name 过滤,并且用重排序代替每次调用发送 25 个大片段的暴力方式。在发布生产默认值之前,先用本地的 POST /run 测试提示。
结语
恭喜你,你用自己的双手构建了一个基于 DigitalOcean Knowledge Bases 和 Serverless Inference 的 RAG 智能体!如果你一路跟了下来,现在你已经知道如何将智能体部署到 App Platform、如何测试它的端点,以及如何排查常见问题了。
当我第一次拼装自己的 RAG 流水线时,手头有趁手的构建块和清晰的步骤让一切都变得不同。希望这篇教程能帮你拨开一些迷雾。
有了新的 RAG 智能体,你已经做好了从知识库回答问题的准备,并且可以开始构建更聪明、反应更灵敏的应用了。当你在探索和微调你的部署时,别犹豫,尽管大胆试验,并根据你的具体需求调整这些步骤。要是碰到了路障,请记住:每一个伟大的解决方案,都始于一个棘手的 Bug 或一个未解的问题。祝你玩得开心!
这是 LegalTech RAG Agent 仓库,你可以用它快速将 RAG 智能体部署到 App Platform:https://github.com/anishsingh20/legaltech-rag-agent
接下来读什么
你也可以查看以下教程,了解更多关于DigitalOcean、无服务器推理的知识:
- 《微调后的 LLM 如何部署到生产环境?GPU 推理端点的搭建、测试与上线全流程》这篇教程向你展示了如何用 BYOM(自带模型)和 Dedicated Inference 将微调 LLM 部署到生产环境。
- 《AI 推理采用本地硬件 + Serverless 混合架构:让敏感数据不出户,算力成本更低》这篇文章以语音翻译工具为例,展示如何根据隐私、成本、运维和能力四个维度,将敏感数据(如音频)留在本地硬件处理,将非敏感文本交由云端 Serverless 推理,实现数据安全与成本优化的平衡
- 《Claude Code 的开源替代方案:用 OpenCode + DigitalOcean 实现模型自由》这篇文章介绍如何通过 DigitalOcean 一键部署 OpenCode,在五分钟内获得与 Claude Code 同等的终端智能编码体验,同时支持自由切换模型、避免供应商锁定,并按用量付费。
相关产品与选型


