
Claude Opus 4.8 这样的前沿模型能驱动从 Python 到 C++ 再到 GDScript 的智能编码,但在生产规模下,它们的按 token 计费成本会迅速膨胀。DigitalOcean 的推理路由器直面这个问题:它将常规工作路由到较小的开源模型,只有在任务确实需要时才升级到前沿模型。为了在一个真实的多文件代码库上衡量差异,我们完全通过 OpenCode 构建了一款完整的基于 Godot 4 的点球大战游戏游戏——PK Shootout。
在这次构建中,OpenCode 在 83 个助手回合(助手轮次,assistant turns)中完成了 596 个路由任务。该项目使用了大约 410 万 token,通过推理路由器的总花费约为 8.25 美元。大多数任务被路由到 MiMo V2.5 和 GLM-5.2,而 596 个任务中只有 2 个需要回退。同样的构建如果只用前沿模型,预估花费将高达约 123 美元(假设生成相同数量的 token)。
PK Shootout 是在几个小时内使用 OpenCode 开发完成的。为了1. 让模型跑起来,我们通过 OAuth 登录将 OpenCode 连接到 DigitalOcean 的无服务器推理服务,然后创建了自己的推理路由器作为后端。有了这两样东西,我们构建了一款完整的 Godot 4 点球大战游戏(瞄准、力量条、门将 AI、对手模拟、突然死亡、结束画面和重新开始),整个工作流中从未指定过模型名称。DigitalOcean的推理路由器按任务挑选模型。然而,在这个过程中我们最核心的发现并不是省了多少钱,而是:推理路由器并不总是运行你所配置的那些模型。它会基于成本驱动做出自主选择,而最终实际运行的模型让我们大吃一惊。
本文将带你走过我们用AI 编程创建这款游戏的完整步骤,从连接 OpenCode 到在应用托管平台(App Platform) 上进行托管。我们将详细拆解哪些环节进展顺利、哪些地方需要人工介入,以及开发过程中实际投入的时间和成本。
将 OpenCode 连接到 DigitalOcean
这是整个流程中最简单的部分之一。我们登录了 DigitalOcean 账户,打开 Inference Router 页面,创建了一个名为 game-designer 的路由器,并配置了四个不同的路由(Routes):
- design:在编码和设计阶段使用最频繁的路由。它将 GLM-5.2 作为主模型,并配备了 Deepseek V4 Pro、Kimi K2.6 和 MiMo V2.5 Pro 作为后备模型池。
- repo-qa:针对简单的代码库问答进行了调优。模型池包括:Gemma 4、MiMo V2.5、Arcee Trinity Large Thinking(公开预览版)以及 Qwen 3.5 397B A17B。
- chore:处理琐碎、低风险且不需要架构推理的修改,例如提交信息(commit messages)、文档字符串(docstrings)、行内注释、README 模板、.gitignore 条目、变量重命名和格式化。模型池包括:Qwen3 Coder Flash、Ministral 3 14B、Gemma 4 和 MiMo V2.5,默认调用 Gemma 4。
- debug:用于诊断运行时错误、堆栈轨迹、构建失败和异常行为,通过分步推理来定位并修复现有代码中的 Bug。模型池包括:GLM-5.2、Deepseek 3.2、MiniMax M2.5(公开预览版)和 Kimi K2.6。
这个路由器承包了这款游戏 100% 的开发工作。将它连接到 OpenCode 只需要一个步骤:在终端中安装 OpenCode,运行 /connect,选择 Login with DigitalOcean(OAuth 路径:只有这个选项会暴露你的路由器),然后进行授权。接着运行 /models,你的路由器就会以 router: 为前缀显示出来。我们选择了 router:game-designer,然后便开始着手构建。
从这里开始,开发便进入了常见的智能体(Agent)循环:用自然语言描述一项修改,让智能体阅读相关文件,提出修改建议,然后应用这些修改。不同之处在于底层的逻辑:对于每一次请求,路由器会决定由哪条路由和哪个模型来处理,而我们的提示词中没有任何模型的名字。 本文接下来的部分将深入探讨我们完全依赖这种架构从头到尾构建《点球大战》所获得的经验。
哪些 DigitalOcean 托管模型真正能驱动一个编码智能体
先说明一下,DigitalOcean平台上的托管模型,指的是无服务器推理中的开源模型,比如DeepSeek、Qwen、Kimi等,这些模型都已部署在DigitalOcean的服务器上,用户可以直接调用API来使用。
言归正传,坦白讲,实际问题并不是“我们选了哪个模型?”,因为我们从未主动做过选择。真正的问题是:“推理路由器是如何将不同的模型与各类工作进行精准匹配的,以及它们各自的表现如何?” 这种视角的转变至关重要,因为这正是路由驱动工作流的核心前提:你负责描述任务,路由负责决定模型。
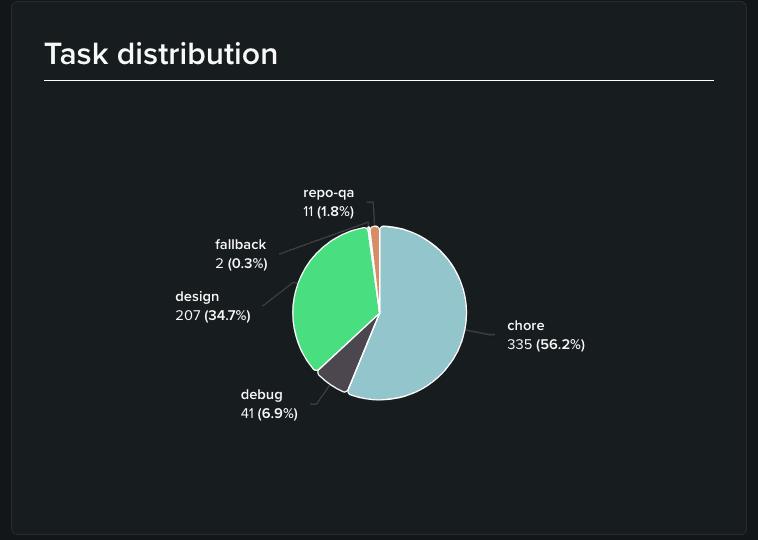
在整个构建期间,路由器将 596 个任务解析到了五个桶中:chore 占了 335 个任务(56.2%),design 207 个(34.7%),debug 41 个(6.9%),repo-qa 11 个(1.8%),还有 2 个回退(0.3%)。这个分布形状正是你对真实开发的预期:大量小编辑构成一条长尾,坚实的设计工作构成核心,真正调试工作较薄的一层,以及几乎没有纯粹的仓库问答。
将这些任务映射到模型分布上,故事就变得比单纯看配置更有意思了。实际上只有三个模型承载了几乎所有的流量:MiMo V2.5 占据了约 56%,GLM-5.2 占据了约 42%,而 Gemma 4 仅占了微弱的 ~2%。我们在每条路由的后备池中列出的许多其他模型(如 Deepseek、Kimi、Qwen、Ministral 等)甚至从未获得上场机会。在实际运行中,这两匹“悍马”搞定了一切。
GLM-5.2 的表现完全符合我们的配置预期。它 ~42% 的份额与它作为主模型的两条路由几乎完美契合:design(34.7%)加上 debug(6.9%)正好是 ~41.6%。这是一个清晰的信号,表明设计和调试路由准确执行了我们的意图,而且 GLM-5.2 足够强大,完全可以胜任架构设计和分步排错这两类最容易暴露模型指令遵循能力短板的重度任务。
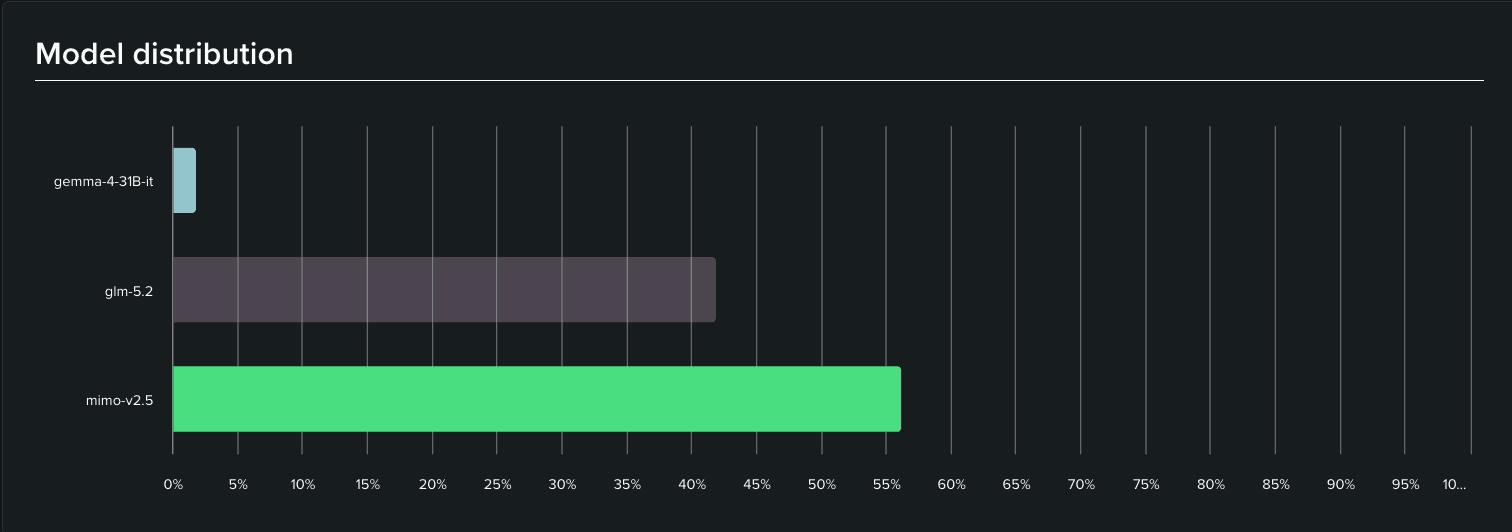
然而,chore 路由则是配置与现实发生分歧的地方,这一点值得摊开来讲。Chore 是我们最大的任务桶,占了总任务的 56%,但我们配置的默认模型 Gemma 4 却只处理了 ~2% 的调用。相反,并未在任何路由中被设为默认模型的 MiMo V2.5 却吞下了 ~56% 的流量。这是因为在路由器的综合计算中,MiMo V2.5 的实际性价比更高,导致路由器在处理低风险修改时主动选择了它而不是 Gemma 4。
💡 给创业者的启示: 路由配置表达的是你的意图,但最终给出答案的是路由器的自主决策。因此,务必定期监控你的模型流量分布,以确认到底是谁在底层干活。
在运行智能体协议(Agentic Protocol)本身时,这些模型表现得毫无压力。在整个开发过程中,底层的模型能够可靠地进行工具链调用:读取文件、用 grep 检索过期的引用、应用精准的 str_replace 式的代码行替换,而不是吐出一堆盲目的长篇大论然后碰运气。它们还执行了跨文件一致性检查(例如,验证在修改后,场景文件、其挂载的脚本以及调用它的代码是否能对齐),并正确推导出了复杂的控制流——比如在异步的比赛结束函数中 await 的先后顺序,以及在函数挂起之前状态是否已经正确设置。这才是衡量“模型能否驱动编码智能体”的真正门槛,它比任何跑分(Benchmark)都更具含金量:它测试的不仅是模型懂不懂 GDScript 语法,更是它能不能熟练操作工具、把整个代码库装进脑子里,并且在修改局部时不把视线之外的其他功能改塌。 在这个门槛上,路由器的这两匹主力马交出了完美的答卷。
开发成本与耗时分析
做出一个能玩的游戏固然是好消息,但底层的具体数据才让这个工作流具有参考价值。
为了完成这款拥有完整功能和文档的游戏,我们共经历了 83 次智能体轮次(Assistant turns) 和 17 次用户轮次(User turns),智能体工作与人类输入的比例大约为 5:1。仅靠 17 次提示词,项目就从一个空的 Godot 工程演变为了包含瞄准、力度条、守门员 AI、对手模拟、骤死赛、结算、重启和完整 README 的成熟项目。
在总共 83 次轮次中,智能体累计花费了大约 74.5 分钟的净生成时间——这是模型实际在后台写代码的时间,不包括我们阅读代码、在 Godot 中测试或思考下一步该问什么的时间。单次轮次的耗时差异巨大:短到只需 2.1 秒的一行代码修复,长到写完整个 README 文件花费了 529.6 秒。这种两极分化真实反映了路由工作流的流量分布:长尾的快速修改中间,夹杂着少数重型的、跨多文件的全局生成。从实际挂钟时间(Wall-clock time)来看,《点球大战》在几个小时内就组装完毕了,其中模型生成大约占了一个多小时。
相比于一刀切地只用一个模型,推理路由器确实引入了一项额外开销:决定每个请求该去往何处的时间。 这项开销非常小且完全可量化。在开发期间,路由解析延迟稳定在 0.27 ~ 0.30 秒 之间(6月25日测得 game-designer 的解析耗时为 0.276s)。每次请求多花约四分之一秒,这就是不自己指定模型的代价值。在两天的开发窗口内,这条延迟曲线一直保持平坦,直到项目末期才略微上升,这说明路由性能并不会随着项目代码库的扩大而退化。
由于大部分流量被解析到成本较低的模型——MiMo 和 GLM,而非前沿 API——总花费远低于用全前沿模型完成同样 596 个任务的成本。换算成具体数字:完成所有工作大约用了 410 万 token——构建应用、设计计划、写 README 文件,以及回答几个关于已完成内容的问题。综合算下来,MiMo v2.5 的调用总计约 0.65 美元,GLM-5.2 的调用累计约 7.56 美元,Gemma 4 的调用花费约 0.04 美元,加起来总共约 8.25 美元。作为对比,如果不用路由器、全部跑 GLM-5.2,总预估成本为 18.04 美元;如果使用前沿模型,比如 ChatGPT 5.5,在相同的 token 数下成本高达 123.00 美元。尽管顶尖模型在处理任务时可能效率更高、消耗的 Token 更少,但这点节省根本无法抵消大模型高昂的单 Token 单价。 将高价的重度工作交给高价模型,把其余一切扔给廉价模型,这正是该工作流的核心经济学逻辑,而任务的天然分布正好完美契合了这一点。
我们不得不人工介入的地方
如果一篇复盘文章只讲成功的部分,那它将毫无价值。虽然路由器独立搞定了《点球大战》的大部分工作,但有三个时刻必须由人类介入,而这恰恰是整个构建过程中最具启发性的地方。其中两次证明了智能体干得漂亮,另一次则暴露了一个阶段性的硬伤——在你把 load-bearing(承重/核心)业务交托给它之前,必须看清这个边界。
一:真正的代码 Bug(智能体自主解决)
在早期的一个版本中,游戏画面看起来一切正常,但点击鼠标左键时没有任何反应:没有蓄力条,球也踢不出去。我们用大白话描述了这一症状,让智能体排查原因。它读取了输入处理器,追踪了事件流,并推导出了问题所在:输入事件甚至根本没有传导到 _unhandled_input 中。罪魁祸首是全屏的背景节点(Background node),一个 ColorRect。和 Godot 4 中的所有 Control 节点一样,它默认开启了 MOUSE_FILTER_STOP,在鼠标事件向下传递之前就悄无声息地将其全部吞掉了。修复方法很简单,只需一行代码将背景的鼠标过滤设置为 ignore 即可。
注意:我们从未指出原因,只是报告了症状。智能体自己诊断出了底层根源,这正是 debug 路由被设计用来进行分步推理的完美范例。
二:空间感知摩擦(人类表达歧义)
我们要求把球门移动到“大约屏幕下方 1/3 的位置(about 1/3 of the way down the screen)”。智能体将这句话理解为了“从屏幕顶部向下数 1/3”,于是把球门往上挪了,这和我们脑海中的画面完全相反。我们直接指出了这一点,并修正为“从屏幕底部向上数 1/3(1/3 from the bottom of the screen)”,它在下一次尝试中就精准地把球门放到了正确的位置。
教训:这并不是模型的失败,而是因为用自然语言描述空间指令天然带有歧义,而消除这种歧义的成本就是多花两个对话轮次。如果第一次就给出精确指令,本可以省下这笔开销。在智能体开发中,人类的工作已经从“写代码”变成了“编写毫无歧义的意图”。
三:中端模型的硬伤(缺乏外部实时知识)
这是最需要引起重视的一点。当我们要求智能体写一段通过 DigitalOcean 无服务器推理生成图片资源的脚本时,它根本不知道真实的 API 结构。在它的推理过程中,它凭空捏造了几个看起来很合理的端点 URL,没有一个是正确的。不过值得称赞的是,它随后触发了自我怀疑,明确指出它不确定这些信息,并主动向我们索要真实的端点和 Token,而不是盲目硬写,最后它生成了一个通用的兼容 OpenAI 的脚本,把关键细节留作占位符。
核心局限:模型在缺乏检索(Retrieval)的情况下,无法可靠地掌握最新的外部 API 细节。如果我们盲信它的第一次猜测,直接部署上线的就是一段坏掉的代码。我们最终为它手动提供了官方配置(见文末最后一节)。
综合来看,这三个时刻清晰地画出了一条分界线。智能体擅长对能看到的代码进行推理:仅凭症状就诊断出鼠标 bug、应用有针对性的修复、以及从模糊指令中优雅地恢复。它的弱项,正是任何没有检索增强的模型都会弱的地方:对那些它无法查看的当前外部系统缺乏权威知识。知道一个任务落在这条线的哪一边,就是用这个工作流把事情做好的关键。
何时适合用推理路由,何时该用顶尖模型
在项目结束时,我们已经有了足够的证据,能够针对“智能路由驱动 + 托管在 DigitalOcean 的架构”究竟适合哪些场景,给出一个客观且立得住脚的结论了。
适合使用路由架构的场景
当你的开发工作大多是常规操作时。 我们的任务划分极具代表性:大约 56% 的杂务(Chore)和 35% 的架构设计(Design),只有极少量的硬核调试,以及几乎为零的纯代码库问答。这才是日常开发的真实样貌——在稳定的设计核心之上,围绕着大量小范围、边界清晰的细微修改,而这正是路由器天生要来吞噬的场景。便宜的任务分给廉价的模型,沉重的任务只有在路由要求时才升级,你永远不需要为一个文档字符串或一个变量重命名去支付顶级模型的昂贵账单。成本数据直观地证明了这一点:整个项目搭建下来只花了大约 8.25 美元,而如果单用 GLM-5.2 预估需要 18.04 美元,用顶级模型则会高得离谱。当你的绝大部分工作是业务落地实现而不是开创性的逻辑推理时,这种混合路由架构的优势就是核心所在。
应该求助于顶级 Frontier API 的场景
当任务极度依赖外部系统的最新精确知识,或者需要经历多步骤、长周期的全局架构推理时。 我们遇到的最清晰的信号,就是后端开始凭空捏造它其实并不知道的 DigitalOcean 端点的那一刻。一个在没有检索(Retrieval)机制下运行的常规中端模型(或次旗舰模型),会非常自信地去填补它在最新 API 和 SDK 知识上的空白,而这种失败模式往往会在你最预想不到的时候让你付出代价。
这条判定标准用大白话很好概括:常规业务实现,交给路由;权威外部事实,要么人工验证,要么升级路由。 如果一个任务取决于模型无法在你的代码库里直接审查的细节,要么直接把事实喂给它,要么将它路由给你百分之百信任的顶级模型。
在这两种情况下,底层都存在着相同的权衡,而且这笔账非常划算。你虽然牺牲了一点点速度(路由器为每次请求增加了大约四分之一秒的解析延迟),并且得接受偶尔的降级(在 596 个任务中发生了 2 次,即当某条路由的主模型没有返回可用输出时,模型池中的下一个模型会接管比赛)。但作为回报,你再也不用一刀切地在代码里固定死单个模型,永远不会为琐碎的工作白交冤枉钱,而且在单次响应搞砸时还能获得一个内置的安全网。对于《点球大战》这类工作负载来说,这笔交易完全超值。
路由驱动的后端何时才是正确选择?
《点球大战》在几个小时内,就从一个空的 Godot 工程演变为了包含瞄准、力度条、守门员 AI、对手模拟、骤死赛、结算画面及重新开始的完整点球小游戏。它完全是通过 OpenCode 运行在 DigitalOcean 的无服务器推理服务上,由推理路由器在 596 个任务中动态进行模型与工作类型的精准匹配,而我们的提示词中从未出现过任何一个模型的名字。
这个结果清晰地勾勒出了这种工作流的用武之地。智能体在可见的代码库上展现出了强悍的推理能力:它仅凭症状就诊断出了鼠标输入 Bug、跨多个文件应用了精准修复,并从带有歧义的指令中轻松恢复。路由器把廉价的工作留给低成本模型,将有能力的高级模型储备给设计和调试,从而让整个项目构建的成本控制在 8.25 美元左右。它的局限性同样一目了然,并且和所有缺乏检索机制的模型一样:对无法直接审查的外部实时系统缺乏权威认知。在使用这个架构时,分清你的任务属于哪一侧,就已经成功了一半。
对于边界清晰的常规开发(这也是绝大多数开发的常态)来说,智能推理路由驱动加 DO 托管的后端是一种真正具有实战价值的构建方式,而且比默认一刀切地去调顶级 API 要便宜得多。
配置与链接
这次构建的一切都可以用一个 DigitalOcean 账户、OpenCode 和几分钟的设置来复现。以下是如何将 OpenCode 与 DigitalOcean 配合使用的完整配置:
- 创建一个模型访问密钥。在 DigitalOcean 控制面板中,打开 Inference → Serverless Inference,然后在 Get Started 标签页中点击 Create a Model Access Key。一个密钥覆盖所有模型和所有模态(文本、图像、音频),且该密钥同时适用于基础模型和路由器。把它保存在安全的地方——任何非 OAuth 访问都需要它。
- 构建路由器(可选但推荐)。在控制面板中,打开 Inference Router 板块并创建一个路由器。我们将我们的路由器命名为 game-designer,并给了它四条路由——design、repo-qa、chore 和 debug——每条路由都有一个主模型和一个回退池,正如本文前面所述。路由器让你可以描述任务而无需指定模型名称;你可以跳过这一步,直接调用基础模型,但那样路由就得你自己来做了。
- 连接 OpenCode。安装 OpenCode,启动它(TUI、桌面版或 Web 版),然后运行:
/connect
搜索 DigitalOcean 并选择 Login with DigitalOcean。这是 OAuth 方式,也是关键的一步:它请求 genai:read 和 inference:query 权限,并拉入你的基础模型和路由器。另一个选项 Paste Model Access Key 也能完成认证,但不会显示你的路由器——所以如果你已经构建了路由器,请使用 OAuth。在浏览器中授权后,运行:
/models
你的路由器会以 router: 前缀显示出来。我们选中了 router:game-designer 并开始构建。以上就是全部设置。直接调用端点。如果你更想从自己的代码中驱动 Serverless Inference,而不是通过 OpenCode,它是兼容 OpenAI 的。将任何 OpenAI 客户端指向固定的基础 URL,并将你的模型访问密钥作为 bearer token 传入:
from openai import OpenAI
import os
client = OpenAI(
base_url="https://inference.do-ai.run/v1/",
api_key=os.getenv("MODEL_ACCESS_KEY"),
)
resp = client.chat.completions.create(
model="game-designer", # 一个路由器名称,或者一个基础模型 ID
messages=[{"role": "user", "content": "总结一下这个仓库的架构。"}],
)
print(resp.choices[0].message.content)
相同的基础 URL、密钥和请求格式也适用于 cURL、Gradient Python SDK、LangChain 或 LlamaIndex——换掉后端,你现有的代码无需改动就能运行。
相关链接
相关产品与选型


