这是刚打到你们生产 API 的一个请求:
"这段代码有语法问题吗?
prices_usd = {'laptop': 1200, 'mouse': 25, 'monitor': 300}
expensive_items_eur = {k: v * exchange_rate for k, v in prices_usd.items() if v > 50}
print(expensive_items_eur)"
一个语法检查。
答案是:没有,没问题。
任何 $0.10/百万 token 档次的模型都能在一秒内正确回答。
现在,三秒后同一 agent 会话发了下一个请求:
"我们正在把单体应用拆成微服务。现有架构使用一个共享的 PostgreSQL 实例,有 47 张表。请识别出哪些表可以安全地拆分到独立的服务数据库中,而不引入分布式事务风险,并提出一个分阶段拆解方案。"
这完全是另一种类型的请求。它需要架构推理、对分布式系统权衡的理解,以及综合出多步迁移计划的能力。这是适合前沿模型处理的复杂任务。
大多数大规模生产级AI应用都会同等对待这两个请求。它们把两个请求都路由到同一个模型——通常是最强大的那个,因为要构建更智能的方案,需要的基础设施大多数团队没有时间去搭建。这样一来,你为每个请求都支付前沿模型的价格,包括绝大多数其实并不需要前沿能力的请求。
这种算力成本在生产环境中的累积速度是极其惊人的。 深入分析一个典型的编码 Agent 会话,你会发现其任务复杂度的分布极其不均:超过 70% 的请求其实都是低门槛的脏活累活——比如语法校验、短数据检索、或基础代码解释——它们构成了流量的绝对主体。而真正需要前沿大模型进行多步复杂推理的请求只占一小部分。如果你的架构缺乏弹性,被迫将 100% 的流量发给价格为 $15/M Output Tokens 的顶级模型,那么你就是把昂贵的旗舰算力,浪费在那些只要 $0.30/M Tokens 的平价模型就能轻松搞定的长尾任务上。
关键要点
- 把所有请求都交给同一个模型成本很高。 生产工作负载中的大多数请求都很简单——语法检查、短查询、基础解释。为所有请求支付前沿模型的价格,成本很快就上去了。
- Inference Router 自动为每个请求挑选合适的模型。 它读取每个请求,将其与你定义的任务类型匹配,然后发送到该任务可用的最经济的模型。
- 在 30B-A3B 模型上路由准确率达到 87.84% ——高于同一基准测试上的 GPT-5.1(86.93%)和 Claude Sonnet 4.5(86.11%)。
- 对于 agent 循环,使用会话固定。
X-Model-Affinity头信息将会话锁定到一个模型上,从而保留缓存的上下文,每轮将输入 token 成本降低 45-80%。 - 入门只需一行改动。 将现有 API 调用中的
"model": "gpt-5.2"替换为"model": "router:software-engineering"。其他一切保持不变。
为什么AI团队明知浪费,却依然全量调用Claude等前沿模型?
方案 1:在应用层硬编码路由逻辑。 手动编写条件分支(if-else)——如果 Prompt 包含“解释”或“总结”,就路由给轻量模型;否则,一把梭发给 Frontier 顶配模型。这种做法在生产环境中瞬间就会破产。例如,“解释一下这个竞态条件(Race Condition)是如何产生的并修复它”,会被错误地降级到轻量模型。而一句带有讽刺意味的“写个 Hello World”,却可能意外触发高昂的顶配模型路径。这种基于关键词的匹配根本无法理解上下文或真实语义。更致命的是,一旦模型更迭或任务变更,就必须重新进行代码部署。你直接把“模型路由”这个底层机制,绑架成了应用层必须无限期维护的业务功能。
方案 2:引入一个 LLM 分类器作为路由层。 使用 Claude Haiku 或 GPT-4o-mini 等轻量模型来做意图分类,然后再分发给目标模型。这在概念上虽然说得通,却引入了全新的原罪:用户的每次请求,你都必须支付“双重推理”的账单——一次分类,一次响应。更糟糕的是,强行用 Prompt 让一个通用模型去干分类的脏活,它根本没有经过专项优化。不仅边缘情况下的准确率令人堪忧,还直接导致首字延迟(TTFT)在关键路径上翻倍,极大地破坏了用户体验。
这两种方案都无法实现规模化扩展(Scale)。它们共同的硬伤是把路由逻辑放错了地方:要么耦合在脆弱的应用层代码里,要么寄生在一个压根不是为此而生的通用模型中。
路由真正需要什么
要想在大规模生产环境中实现精准的模型路由,你必须跨越三道技术壁垒:
1、语义意图解析。告别粗暴的关键词匹配,路由必须真正洞悉对话的真实诉求,并具备多轮上下文的推理能力。比如一句“在纽约也这么搞”,脱离了前序对话就是毫无意义的废话;再比如在写代码时用户丢一句“修一下”,它的真实意图是“干掉刚才讨论的 Bug”,而不是去“修正语法错误”。任何缺乏多轮上下文洞察力的路由系统,在面对真实的 Agent 生产流量时都会瞬间崩盘。
2、实时性能信号。 模型的成本和延迟从来都不是固定常数。服务商的定价在变,延迟更会随着全网流量负载产生 2–3 倍的剧烈波动——凌晨 2 点还快如闪电的模型,到了下午 2 点大流量压顶时可能就慢如蜗牛。基于静态配置构建的路由系统,其内置的假设往往撑不过几周就会失效。
3、基础设施层面的执行。 如果把路由逻辑写进应用代码,就意味着应用团队得当全职保姆。只要模型上线、下架或调价,你就得跟着重构路由逻辑;一旦上层的 Agent 框架升级,好不容易写的路由封装层就会直接报废。路由应该是一种底层基础设施原语(Primitive)——下沉到应用层之下,对业务完全透明,无需触碰任何业务代码即可原地升级。
这正是“推理时模型路由(Inference-time Routing)”走向基建化的核心逻辑。
研究基础是什么
使用不同的 LLM 来平衡成本和质量,有坚实的研究支持。
FrugalGPT(Chen 等人,2023)是最早提出这种新颖方法的论文之一:通过将请求从最弱到最强依次发送给模型,并在模型足够自信时停止,可以在标准基准测试上以最高降低 98% 的成本实现 GPT-4 级别的质量。核心洞察是:大多数查询并不需要最贵的模型;难的是知道哪些查询需要。
RouteLLM(Ong 等人,2024)则更进一步,摒弃了人工制定规则,转而通过人类偏好数据(Human Preference Data)来训练路由策略。其最优路由器在 Chatbot Arena 基准测试中实现了 2 倍的成本削减,同时焊死了 GPT-4 95% 的质量底线。该研究的核心发现是:术业有专攻,针对路由任务专门训练的小型分类器,其表现暴打直接用 Prompt 强喂出来的通用大模型
最近,LLMRouterBench(2026)引入了一个统一的路由方法评估框架,证实了学习的、任务特定的路由器在质量、成本和延迟维度上始终优于基于规则和基于提示词的方法。
智能路由的学术论据是清晰的。过往唯一缺失的,是工业级的生产基建——能把原本需要耗费数周的复杂工程项目,压缩成一梭子代码就能开箱即用的终极体验。
DigitalOcean 构建智能推理路由的方式
DigitalOcean 的 Inference Router 建立在与上述方案不同的前提之上。它不是一个通用分类器或一组应用层规则,而是使用一个专门构建的、针对多轮会话路由进行了微调的 混合专家(MoE) 模型。它使用一个名为 Plano-Orchestrator 的专用路由模型,由 Katanemo(现已被 DigitalOcean 收购)开发,有 4B 密集参数变体和 30B-A3B MoE 变体(后者每次路由决策仅激活约 3B 参数)。它运行在 Plano 内部——这个开源的 AI 原生代理是 Inference Router 基础设施层的核心。
使用方式如下:
from openai import OpenAI
import os
client = OpenAI(
base_url="https://inference.do-ai.run/v1",
api_key=os.environ["MODEL_ACCESS_KEY"]
)
# 之前:每个请求都打到 gpt-5.2,无论复杂度
response = client.chat.completions.create(
model="openai-gpt-5.2",
messages=[{"role": "user", "content": prompt}]
)
# 之后:MoE 路由器将每个请求分发到合适的模型
response = client.chat.completions.create(
model="router:software-engineering",
messages=[{"role": "user", "content": prompt}]
)
# 实际处理这个请求的是哪个模型?
print(response.model) # 例如 "openai-gpt-oss-120b" 或 "anthropic-claude-sonnet-4.5"
响应中的 model 字段会告诉你哪个模型实际处理了请求。路由决策是完全可观察的。应用代码除了一个字符串外没有任何变化。
为什么 MoE 被称为路由的大脑?
本文融合了两个核心概念:智能路由(Routing)与混合专家模型(Mixture-of-Experts, MoE)。在剖析二者如何完美结合之前,我们有必要先厘清各自的底色。
推理路由或智能路由是指自动决定哪个模型处理哪个请求,而不是把所有请求发送给一个硬编码的模型。路由器位于你的模型池前面,读取每个传入的 prompt,弄清楚它是什么类型的任务,然后分发给最适合该任务的模型。简单的语法检查交给便宜、快速的模型。复杂的架构问题交给前沿模型。应用代码不需要改,只需改动 model 字段里的字符串。
混合专家模型(MoE) 是一种模型架构:不是对所有输入都运行所有参数,而是模型拥有一组专门的子网络(专家)和一个小的门控网络,后者只激活最相关的几个。一个 30B 的 MoE 模型每次请求可能只激活 3B 参数——因此它拥有大模型的能力,但计算成本却小得多。
本节刻意精简了通用的 MoE 理论。这里的重点是使 MoE 在路由层内部作为 分类器 有用的那个特定性质。
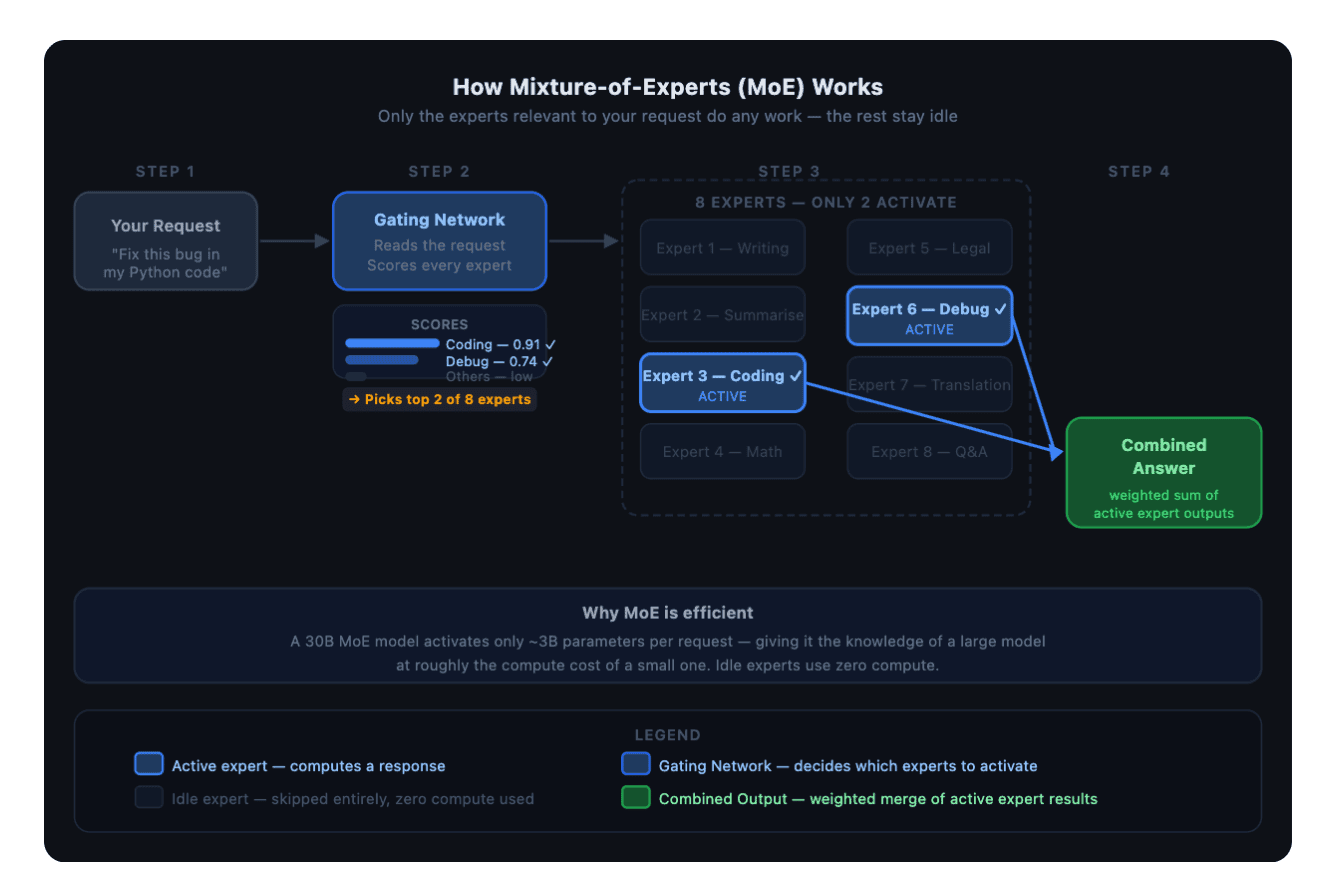
密集 vs 稀疏:AI 推理的核心分水岭
普通的 Transformer 架构(即通常意义上的“标准 LLM”)属于稠密模型(Dense Model)。其在前向传播(Forward Pass)时会激活每一个参数。如果模型身居 70B 体量,那么你每生成一个 Token,全量 70B 参数都必须被无条件“压榨”一遍。
而 混合专家模型(MoE) 则彻底颠覆了这种低效模式。它将传统的稠密前馈网络(FFN)层剥离,替换为 $N$ 个独立的专家网络和一个微型门控网络。在处理每个 Token 时,门控网络会实时计算并仅筛选出 Top-$k$ 个专家(通常 $k=2$)进行网络流转。其余的 $N-k$ 个专家在这一轮生成中则完全处于闲置(Sit Idle)状态,不消耗任何算力。
以驱动 DigitalOcean 推理路由器的底层模型 Plano-Orchestrator-30B-A3B 为例:其物理总参数高达 30B,但单次前向传播的实际激活量仅为 3B 左右。这正是其命名中 “A3B”(30B Total, 3B Active)的硬核奥秘所在。
Dense model (70B): [token] → all 70B parameters activated → output
MoE model (30B-A3B): [token] → gating network → top-2 experts (~3B) → output
↑
28B parameters sit idle for this token
总参数量 与 激活参数量的分离是关键特性。一个 MoE 模型可以拥有大模型的能力(因为总参数量很大),同时运行成本却小得多(因为每次前向传播只激活一小部分)。
门控网络如何选择专家
门控网络(Gating Network)本质上是一个可学习的线性层,它负责为每一个专家网络计算出一个匹配分,进而筛选出 Top-$k$ 个专家。用数学与伪代码的视角来拆解,其底层执行流如下:
scores = x · W_gate # 将 token 投影到专家分数空间
top_k_indices = TopK(scores, k) # 选择 k 个得分最高的专家
weights = Softmax(scores[top_k_indices]) # 归一化得到贡献权重
output = Σ weights[i] · Expert_i(x) # 所选专家输出的加权和
模型在训练过程中会学习每种类型的输入应该由哪些专家处理。。值得注意的是,这些专家并不会被人工打上‘主题标签’(如代码专家、翻译专家)——它们的专业化分工(Specialization)完全是通过梯度下降,在海量训练数据的冲刷下自发演化出来的。
然而,这也会带来的一个实际问题,即负载不均衡(Load Imbalance)。如果门控网络将大多数 token 都路由到同样的两个专家,其他专家就永远得不到训练,模型性能会下降。MoE 训练增加了一个辅助损失项(Auxiliary Loss)来惩罚不平衡的路由,促使 token 在专家之间更均匀地分布。
为什么 MoE 的特性使其成为路由的最佳载体
路由问题——对会话意图进行分类并将其映射到正确的模型——有一个特定的结构:
- 高容量需求:路由器必须在数百种不同的任务类型、用户措辞和会话模式之间泛化能力。一个 1B 的密集模型可能没有足够的表示能力来很好地处理这个问题。
- 低计算预算:路由决策必须在请求的黄金路径中完成。延迟每增加一毫秒,用户等待首字(TTFT)的时间就会同步延长。
MoE 直接解决了两者。30B-A3B 模型拥有 30B 模型的能力——足以很好地处理各种路由场景——但运行成本约为 3B 密集模型的计算量。这就是为什么它在推理时能在约 200ms 内解析意图。
常规 3B 稠密模型虽然响应迅速,但在面对复杂的多轮会话时泛化能力不足;而 30B 稠密模型虽然泛化表现优异,但在请求路径中又因耗时过长而无法落地。MoE 架构成功在这两者的中间地带找到了最佳解。
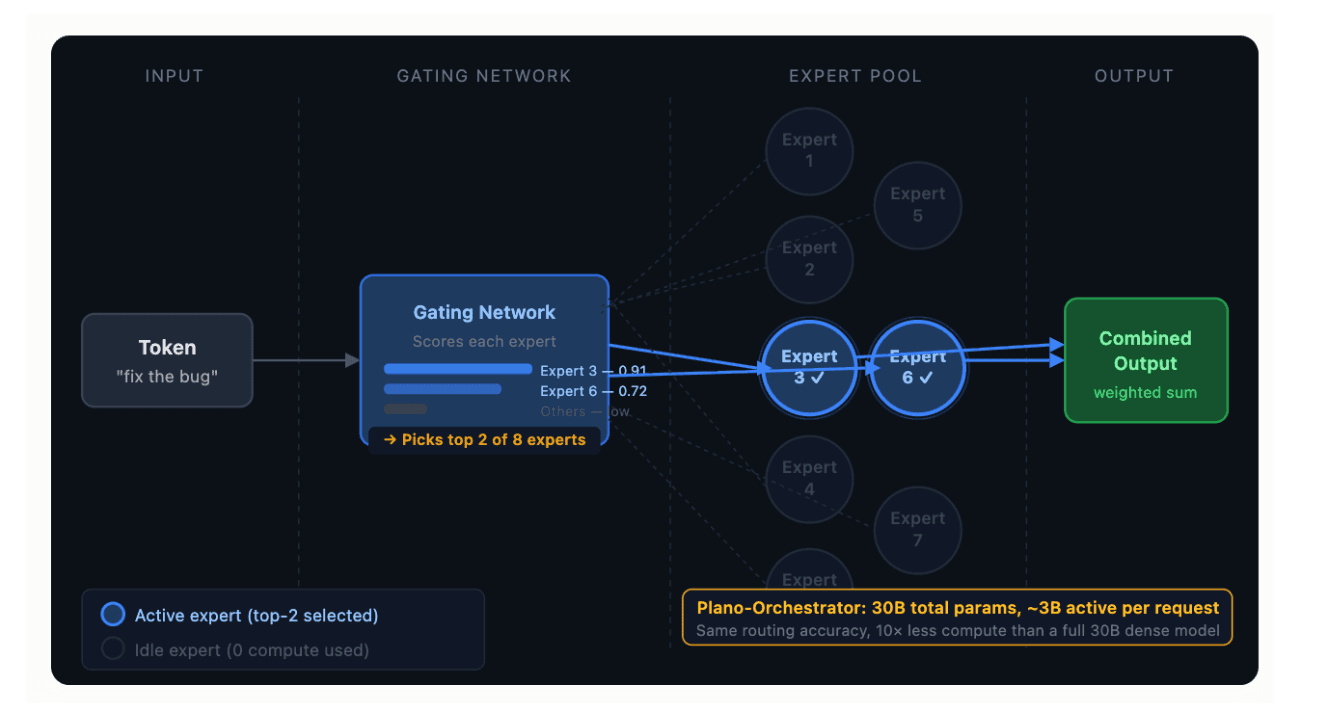
承上启下:从 Token 路由到请求级路由
在 MoE 模型内部,门控网络将 token 路由到 专家子网络。在 DigitalOcean 的推理路由(Inference Router) 中,一个 MoE 模型充当门控网络,将整个请求路由到独立的模型端点。
我们可以通过下面的对比清晰地看出二者在拓扑结构上的高度同构性:
1. 传统 MoE 模型内部(Token 级细粒度):
输入 Token ➔ 门控网络 ➔ 激活 Expert_2, Expert_7 (共 64 个专家) ➔ 权值融合输出
2. DigitalOcean 推理路由器中(Request 级粗粒度):
用户请求 ➔ Plano-Orchestrator (MoE 模型) ➔ 路由至 model_endpoint_A (共 N 个目标模型) ➔ 业务响应
两者的底层问题结构完全一致——对输入进行分类、将其导向最优处理单元、最终聚合或透传结果。唯一的区别在于操作的算力粒度。DigitalOcean 之所以选择 MoE 架构来做全栈路由器,绝非为了追逐技术时髦,而是看中了其“超大表征容量”与“极低激活算力”的物理特性,这与路由器的基建诉求形成了天然的闭环。
DigitalOcean Inference Router 的工作原理
每个发送到 router:software-engineering 或任何 自定义路由器 的请求,在到达模型之前都要经过两个阶段。
阶段 1:语义意图解析(Intent Resolution)
当一个请求到达时,Plano(支撑路由器的开源代理)将会话连同所有已配置任务的自然语言描述一起传入 Plano-Orchestrator 模型。模型的工作是输出一个 JSON 路由决策:
{"route": "code_generation"}
或者,如果没有匹配项:
{"route": "other"}
这就是全部逻辑。该模型拒绝废话(No Prose),也从不输出其推理过程。 它唯一的KPI就是速读对话、完成任务匹配、并在 $N+1$ 种分类结果($N$ 个预设任务 + $1$ 个兜底的 other)中做出绝对理性的单选。这纯粹是一个被极端特化(Specialized)的分类工程。正因如此,专门为此灌喂训练出来的 MoE 模型,其战力表现能轻松碾压通过 Prompt 强行赶鸭子上架的通用大模型。
一旦请求在阶段 1 锁定了明确的任务标签,路由器便会无缝杀入阶段 2:模型选择。
阶段 2:模型选择
意图落定后,路由器会立即检索该任务背后的目标模型池(Model Pool)。在 DigitalOcean 的 Web 控制面板中,架构师可以为每个模型池赋予不同的分发策略:
- 成本优先(Cost Efficiency - 默认): 系统会实时拉取可用模型,并按每百万 Token 的计费价格进行升序排列(便宜的模型置顶)。路由器默认选择价格最低的模型。为了防止由于微小的网络或价格波动导致请求在不同模型间“反复横跳”,系统内部集成了一个温度阈值机制,用于维持路由策略的稳定性,规避模型频繁振荡(Flapping)。
- 速度至上(Speed Optimization): 系统按实时的首字延迟(TTFT)进行升序倒排,最快的模型永远处于 Top 1。该策略是延迟敏感型业务的绝对福音。(注:按小时计费的专属推理端点默认不参与此策略,因为它们不采用基于 Token 的计费模型)。
- 自定义硬核排名(Custom Ranking): 允许工程师通过拖拽直接硬编码模型优先级。路由器将死死锁定列表顶部的存活模型。适合对特定模型有强依赖、需要绝对掌控力的保守型架构。
值得强调的是,模型池的重排和洗牌完全是在运行时(Runtime)实时发生的。每次路由查询都会触发重新评估,这意味着一旦服务商悄悄调价或遭遇网络风暴引发延迟飙升,路由网关会在毫秒级内自动完成洗牌。
延迟影响:那平白无故多出来的 200ms 算技术债吗?
不可否认,Plano-Orchestrator 会在同步请求路径中截留约 200ms 的处理开销。这笔“基建税”是否划算,取决于你的业务底色:
-
场景 A:200ms 几乎无感(绝大多数大模型应用)
Frontier 顶配模型在常规负载下的 TTFT(首字延迟)通常在 800ms 到 2s 之间波动。如果在 1.2s 的硬性延迟之上增加 200ms 的路由开销,最终的用户感知延迟将从 1.2s 变为 1.4s(微增 17%)。在常规的对话或异步 Agent 场景中,这种变化在人类感官中完全可忽略不计。
-
场景 B:200ms 沦为致命瓶颈(极度压榨延迟的实时业务)
如果你在构建一个高实时性的语音交互助手,用户体验死线要求 TTFT 必须压进 300ms 以内。此时单单路由决策就挥霍掉了 200ms(吃掉了 67% 的算力预算),这就是灾难。针对此类场景,要么降级使用 4B 级别的轻量稠密模型以缩短开销,要么直接使用免意图分类的预设单任务路由器。
-
场景 C:200ms 反而倒赚延迟(神级反转)
当路由机制帮你成功避开了“高延迟大坑”时,奇迹就发生了。 假设你的系统在静态配置下默认调用 GPT-5.2(日常 TTFT 约为 1100ms),而路由器敏锐地发现当前请求只是一个极简单的动作,进而将其重定向给更轻量、更敏捷的小模型(TTFT 仅 350ms)。
此时,你的净延迟为:350ms(模型TTFT) + 200ms = 550ms
相比于原本死板的静态配置,你不仅省了钱,整个首字响应速度甚至还白嫖了 50%!
静态路由: [请求] ──────────────────── GPT-5.2 ── TTFT:1,100ms
路由器: [请求] ── 200ms 路由 ─── 更便宜/更快的模型 ── TTFT:350ms
使用路由后的净 TTFT:550ms(比静态快 50%)
这种“以空间换时间,以智商换延迟”的巧妙反转,正是动态路由在工程上的迷人之处。而在实际的生产环境中,要捕获并复现这种净延迟红利,往往需要对供应商的价格和网络延迟进行毫秒级的动态重排。
DigitalOcean 的 Inference Router 团队显然在产品设计时深度考虑了这一点。它的控制面板允许你在“成本优先”与“速度至上”之间一键切换。如果遭遇某家 Frontier 模型服务商网络抖动或临时调价,底层的路由引擎会在运行时自动洗牌、秒级降级,把这种复杂的容灾和优化逻辑完全挡在业务层之外。如果你需要了解更多,可以联系咨询卓普云AI Droplet。
成本:一个实例计算ROI
我们用一个具体的研发实例来算一笔账。假设你麾下运营着一款高度活跃的AI产品(例如 AI Coding Agent),每天需要向外吐出 1000 万个输出 Token。根据 Agent 真实的业务监控,日常的任务谱系和占比分布通常如下:
| 任务类型 | 估计占比 | 示例 |
|---|---|---|
| 简单查询、语法检查、解释 | 35% | 语法检查、报错信息翻译、常识性概念解释(如“这个错误什么意思?”) |
| 中等复杂度代码生成 | 40% | 局部逻辑代码生成、单元测试编写(如“写个函数验证这段输入”) |
| 复杂推理、架构、调试 | 25% | 跨模块架构设计、深度 Debug、分布式系统调优(如“分析此处的竞态条件”) |
使用仅前沿模型的静态配置,价格 $15/百万输出 token(约为 GPT-5.2 定价):
1000 万 tokens/天 × $15/百万 = $150/天 → $4,500/月
使用路由方案:35% 简单任务发送到 $1/百万 token 的模型,40% 中等任务发送到 $5/百万的模型,25% 复杂任务保留在 $15/百万的模型上:
350 万 tokens × $1/百万 = $3.50/天
400 万 tokens × $5/百万 = $20.00/天
250 万 tokens × $15/百万 = $37.50/天
总计:$61/天 → $1,830/月
仅靠DigitalOcean的推理路由,输出 token 账单就降低了 59%,而复杂任务的模型完全没有变化。实际节省金额取决于你的任务组合和当前模型定价。
DigitalOcean 推理路由(Inference Engine)
推理路由(Inference Router) 是 DigitalOcean Inference Engine(运行基础模型的更广泛平台)中的一层。清晰勾勒这一全栈拓扑,能帮助架构师准确研判路由器可调度的模型边界与死角。
Inference Engine 有三种主流的算力托管服务模式:
Serverless Inference(无服务器推理): 采用按 Token 计费模式,无需预留任何 GPU 算力。 请求完全由共享 GPU 算力池动态承载。该模式是突发性、不可预测流量的终极救星,让企业无需为闲置的专用硬件买单。路由器默认对其提供完美的分发支持。
Dedicated Inference(专用推理):为特定业务独家预留的 GPU 专属算力。 延迟可预测,没有冷启动开销,适合有合规需求、需要隔离计算资源的场景。当选择策略为 "Speed Optimization" 或 "Manual Ranking" 时,路由器可以分发到专用推理端点(专用实例被排除在 "Cost Efficiency" 自动排序之外,因为它们的定价模式是按小时而非按 token)。
Batch Inference(批量推理):专为离线、高吞吐工作负载设计的异步处理通道。 该模式独立于路由器的实时关键路径(Critical Path)之外,批量作业需通过专用的 Batch API 单独提交并调度。
目前DigitalOcean平台的模型(Model Catalog)已扩容至 40 多款顶配模型,横跨文本、图像、音频与视频等多模态,全面覆盖 OpenAI、Anthropic、Meta、Mistral 以及前沿开源社区。请务必注意:当前的 Inference Router 仅支持对文本(Text/Chat)模型进行动态路由分发。
深度可观测性:分析仪表盘指标
当你的路由器开始接收流量后,DigitalOcean 控制面板的 "Analyze" 标签页会显示:
- 每个时间窗口内路由的请求总数
- 所有被路由模型的 token 使用总量(输入 + 输出)
- 任务匹配率:匹配到已配置任务的请求百分比(相对于落入回退的情况)
- 回退率:命中回退模型池的请求百分比
一个健康的路由器通常显示超过 85% 的任务匹配率。如果你的回退率高于 20%,很可能你的任务描述(Task Descriptions)太窄了——本应匹配某个任务的请求落空了。
上线之前的评估
在将生产流量切换到路由器之前,使用DigitalOcean 后台的 Playground 的比较模式:将一组测试 prompt 同时通过路由器和单个前沿模型进行路由。每个响应会显示所选模型、端到端延迟和每次请求的成本。Evals 功能将此扩展到数据集——上传 50-100 个代表性 prompt,运行评估,获得路由器与静态基准的 LLM 裁判正确性和完整性评分。
如何写出真正有效的任务描述
从 Inference Router 的生产运行中获得的一个不太明显的发现是:路由精度对任务描述的写法高度敏感。路由模型直接读取这些描述来匹配每个请求;如何编写它们决定了路由的效果。
这里从技术角度解释为什么重要:Plano-Orchestrator 模型使用语义匹配(而非关键词匹配)将每个传入消息与你的任务描述进行比较。这意味着你的描述需要足够具体以区分不同的任务,但又足够宽泛以覆盖用户表达同一意图时的各种措辞变化。
对齐名称和描述
任务的 name 和 description 应该一致:名称是标签,描述是展开说明。如果两者相互矛盾,模型会收到矛盾信号。
// Good: name and description reinforce each other
{
"name": "bug_fixing",
"description": "Identify and fix errors, exceptions, or incorrect behavior in user-supplied code"
}
// Bad: name says "math" but description is vague and could match almost anything
{
"name": "math",
"description": "handle anything related to numbers or calculations"
}
足够具体以便区分任务
如果两个任务描述高度重叠,路由器将难以区分它们。当两个任务指向非常不同的模型池时,这个问题尤其严重。
// Problematic: these two descriptions match many of the same prompts
[
{
"name": "technical_writing",
"description": "Write technical content, documentation, or explanations"
},
{
"name": "code_documentation",
"description": "Document code, write docstrings, or create API references"
}
]
// Better: make the distinctions explicit
[
{
"name": "technical_writing",
"description": "Write tutorials, blog posts, or conceptual explanations for technical audiences, not involving direct code documentation"
},
{
"name": "code_documentation",
"description": "Write inline docstrings, function comments, README files, or API reference documentation directly tied to code"
}
]
使用名词中心描述
以 任务类型(名词)而非 任务感觉(形容词)为中心的描述能产生更稳定的路由。路由模型是在任务类型模式上训练的,而非情感风格的信号。
// Less stable: "creative" and "engaging" are vague modifiers
{
"description": "Write creative, engaging content that users will enjoy"
}
// More stable: describes the actual task structure
{
"description": "Write blog posts, social media copy, marketing emails, or promotional content"
}
用真实流量测试后再调优
找出任务描述中漏洞的最快方法是查看路由器的回退率。如果回退率高于 15-20%,抽取一部分落入回退的请求并问自己:这些请求本应匹配我的某个任务吗?如果是,描述漏掉了它们——添加相关的措辞。如果不是,回退处理正在正常运转。
# Use the response header to track routing decisions in your own logs
import httpx
response = httpx.post(
"https://inference.do-ai.run/v1/chat/completions",
headers={
"Authorization": f"Bearer {os.environ['MODEL_ACCESS_KEY']}",
"Content-Type": "application/json"
},
json={
"model": "router:my-coding-router",
"messages": [{"role": "user", "content": user_message}]
}
)
route_selected = response.headers.get("x-model-router-selected-route")
model_used = response.json()["model"]
# Log these for analysis
print(f"Route: {route_selected}, Model: {model_used}")
从一天的流量中构建一个 (prompt, route_selected, model_used) 的电子表格。查看"fallback"行——那就是你描述的缺口所在。
生产注意事项
回退行为
每个路由器都有回退模型。它们处理两种不同的情况:
- 没有任务匹配:路由模型将请求分类为
other——没有已配置的任务是合适的匹配。 - 选中模型不可用:排名最高的模型宕机、返回错误或被限流。
在情况 2 中,路由器会按排序顺序依次遍历任务池中剩余的模型,然后才落入回退模型。回退模型按照你指定的顺序尝试。如果全部失败,请求返回一个错误。
实际含义:你的回退模型应该是一个你愿意用它来服务 任何 请求的模型——因为它是你的兜底选择。像 openai-gpt-oss-120b 这样的通用模型是个常见选择,因为它能充分处理多样化的输入,且比前沿模型有更低的每 token 成本。
模型别名和命名
定价 API 和路由配置可能对同一个模型使用不同的名称。例如,定价目录可能列出 openai-gpt-5.2,而你的 YAML 使用 openai/gpt-5.2。Plano 的 model_aliases 映射起到了桥梁作用:
# 在自托管部署的 Plano 配置中
model_aliases:
"openai/gpt-5.2": "openai-gpt-5.2"
"anthropic/claude-sonnet-4": "anthropic-claude-sonnet-4.5"
在 DigitalOcean 的托管路由器上,这是自动处理的——请使用DigitalOcean文档中心里模型目录中的模型别名。如需帮助可直接咨询卓普云(aidroplet.com)的工程师团队。
常见问题(FAQ)
Q1:Inference Router 或者是做什么的?
它本质上是一个前置的动态分流网关。 系统会根据您传入的请求内容,自动挑选最匹配的 AI 模型来接管。它彻底终结了“无论任务多简单,都一律无脑调用 Frontier 顶配模型”的资金与技术浪费,让对的模型去处理对的请求。
Q2:它是如何精准识别并判断该调用哪个模型的?
依靠底层的智能门控机制。 在请求流转的核心路径上,系统部署了一个特化训练的轻量 MoE 模型 —— Plano-Orchestrator。它会秒读您的 Prompt 上下文,将其与您在控制面板配置的任务类型(如“代码审查”或“通用问答”)进行语义向量匹配。匹配成功后,它会实时调取该任务绑定的模型池,并依据您偏好的策略(成本优先或速度优先)动态下发给最优模型。
Q3:这套前置路由会拖慢应用的首字响应(TTFT)吗?
它会在生成第一个响应 Token 之前,带来约 200ms 的同步开销。 在绝大多数 Agent 或 Chat 业务中,这笔开销完全可以忽略不计 —— 因为 Frontier 顶配模型在常规负载下的 TTFT 已经高达 800ms 到 2s。
- 如果您的应用有极其严苛的实时性死线(例如语音助手),您可以选择无意图解析的预设单任务路由器,或切换到更轻量的 4B 模型变体以进一步压缩这部分开销。
Q4:接入后,最终能帮我的项目降低多少成本?
根据 DigitalOcean 的生产线真实审计数据显示,相较于全量死磕 Frontier 单一顶配模型的传统架构,智能路由方案可实现 40%–60% 的 Token 净账单降幅。最终的投资回报率取决于您业务中“轻量/复杂任务”的真实混配比例以及模型服务商的实时定价。
Q5:一旦选中的后端大模型突然宕机或不可用,系统会崩溃吗?
绝对不会。整个容灾重试流程对上层业务完全透明。 路由器会自动尝试该任务模型池中的下一顺位模型;如果全部不可用,则会平滑降级至您配置的 Fallback 兜底模型。您的应用层不需要编写任何异常捕获代码,确保生产环境零丢包、零丢请求。
Q6:如果用户的 Prompt 没有命中任何预设任务怎么办?
请求会平滑滑入您配置的“Fallback(兜底)模型池” —— 这是一组作为保底防线的通用大模型。路由器拥有极高容错度,绝不会仅仅因为意图未命中最优任务就向前端抛出错误。
Q7:对现有架构而言,迁移和接入的成本有多高?
仅需改动一行字符串。 您不需要重构任何业务逻辑或应用代码,只需在现有的 API 调用中,将原本硬编码的特定模型名称更换为路由器的代号(例如 "router:software-engineering" 或其他预设代号)即可。
更详尽的自定义路由器策略配置与端点接入指南,请参见 DigitalOcean Inference Router 文档,或咨询卓普云(aidroplet.com)。
结论:基于 MoE 的路由真正解决了什么
将所有请求路由到同一个模型是一个成本问题——而团队历史上采用的解决方案(静态模型选择或应用层分类器)都有根本性的问题。前者为每个请求都多付了钱。后者在每个请求之上增加了一次额外的推理调用,并且引入了需要有人维护的路由逻辑。
DigitalOcean Inference Router 采用的方法在一个重要方面有所不同:它将一个专门构建的 MoE 模型置于基础设施层,使其成为请求路径的一部分,而非应用层的一部分。30B-A3B 的 Plano-Orchestrator 模型激活约 3B 参数,在约 200ms 内解析意图——快到不会对交互式工作负载的延迟产生有意义的影响,准确度(87.84% 对比 GPT-5.1 的 86.93%)足以在复杂的多轮编码和长上下文会话中正确路由。
来自生产的数据支持这一前提:在混合工作负载上正确路由,搭配合理的任务分布,可将推理成本比单个前沿模型降低 40-60%。
对于大多数生产环境中的 agent 工作负载——即任务组合确实多样化、流量足够大使成本成为考量因素、且延迟要求至少有 200ms 余量的场景——这个权衡是有利的。
从预设路由器开始,如果你的工作负载属于软件工程、写作、知识库或通用模式。模型池和选择策略经过了 DigitalOcean 数据科学团队的基准测试,你只需改一个字符串,几分钟内就能开始路由。
构建自定义路由器,当你的任务分类法特定于你的领域时——法律文档分析、医学问答、金融建模——这些情况下预设类别无法精准对应。
参考资源
DigitalOcean 资源
- 我们如何构建 DigitalOcean Inference Router
- Inference Router 文档
- DigitalOcean AI Native Cloud 发布
- Inference Engine 产品页
- Plano(开源项目)
研究论文
- Arch-Router:将 LLM 路由与人类偏好对齐
- RouteLLM:用偏好数据学习 LLM 路由
- FrugalGPT:如何在降低成本和提升性能的同时使用大型语言模型
- LLMRouterBench:LLM 路由的大规模基准测试和统一框架
- 高效 LLM 推理的通用模型路由
- Signals:Agent 交互的轨迹采样与分流
- Shazeer 等人,2017——超大神经网络:稀疏门控混合专家层
- Fedus 等人,2021——Switch Transformers:将模型扩展到万亿参数
Plano-Orchestrator 模型(HuggingFace)
相关产品与选型


