每个 AI Agent 最终都会撞上同一堵结构性的墙:模型虽然具备推理能力,但没有工具它就无法采取行动。总得有人去执行这些工具——比如抓取搜索结果、查询数据库、调用 API——而在通常情况下,这个“人”就是你写的代码。
大多数团队构建这一层的方式如出一撤:模型返回一个工具调用指令(Tool Call),你的代码拦截它、执行该工具、格式化结果,然后发回给模型。这个循环不断重复,直到模型获得回答所需的所有信息。这个循环虽然行得通,但意味着你的团队必须承载完整的工具层:网络连接、凭据管理、重试逻辑、错误处理以及可观测性。这些工作没一件是你的核心产品——它们只是幕后默默运转的底层基础设施。
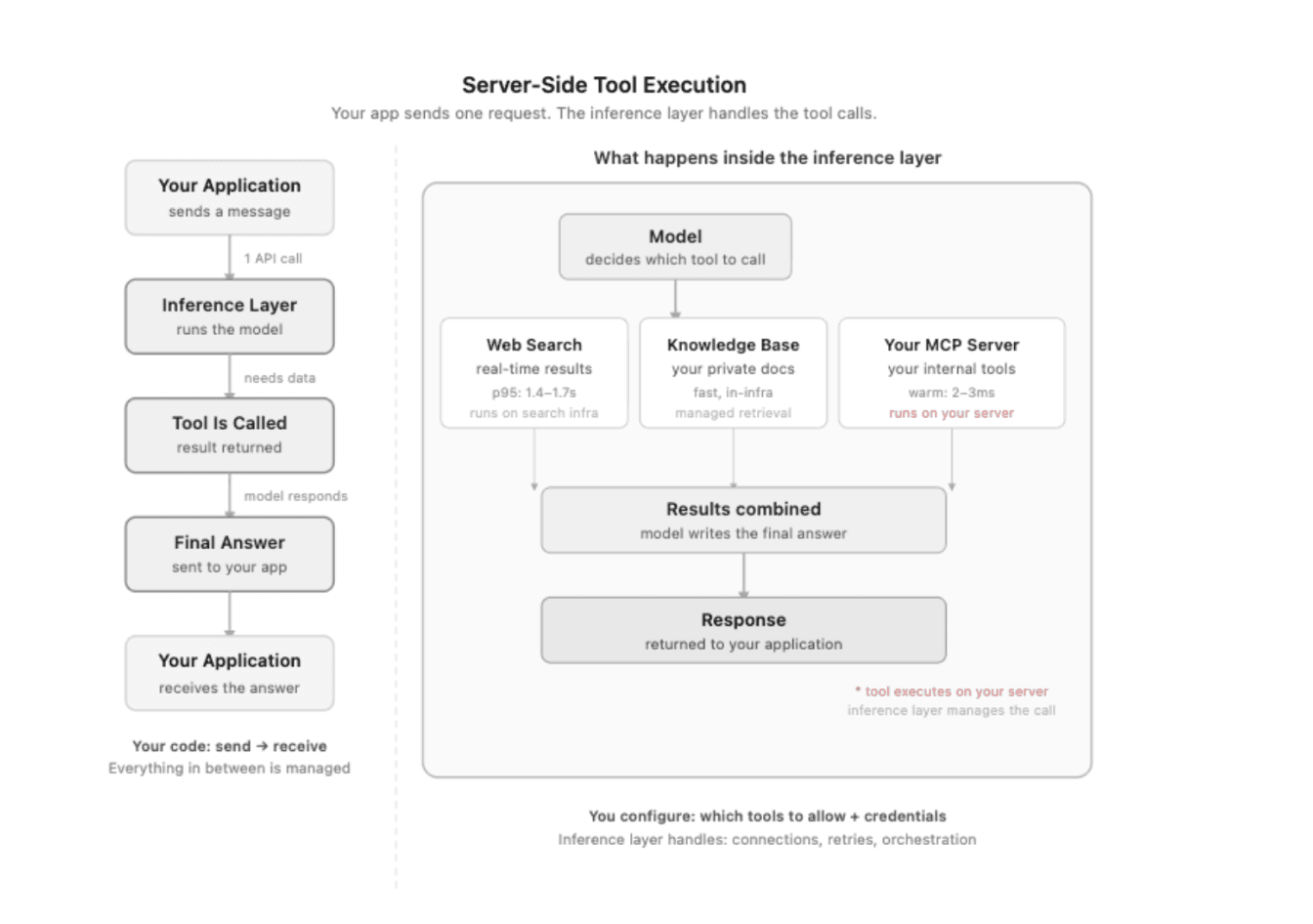
但现在有了另一种选择:将工具的执行直接移入推理层内部。让工具作为 API 调用的一部分来运行,而不是在多次 API 调用之间倒手。
DigitalOcean 用于推理引擎的服务端工具(Server-Side Tools) 实现的就是这种模式。本文将为你深度拆解这种转变究竟改变了什么、它的底层架构、延迟表现,以及哪些场景下它并不适用,从而帮你判断它是否符合你的业务场景。
核心要点(Key Takeaways)
-
你的代码会变得极简,但依然需要通盘考虑。 尽管 DigitalOcean 帮你接管了工具的执行,但应对故障、优化性能和确保重试安全(幂等性)的责任依然在你的肩上。
-
客户端执行适合开发期,服务端执行更适合生产期。 客户端模式为你提供了完全的可视化和本地调试便利;而当你准备正式上线时,服务端模式则能帮你彻底卸下基础设施的维护负担。
-
冷启动依然是你的战场。 DigitalOcean 负责管理连接,但如果你的 MCP(Model Context Protocol)服务器自身陷入了冷启动,那这段启动耗时依然会直接体现在响应时间上。请务必做好保活(Keep it warm)。
-
工具故障与 Agent 故障是两码事。 工具超时属于基础设施问题;而工具正常运转但模型回答得一塌糊涂,则是 Prompt(提示词)的问题。请务必将它们分开监控。
-
在出问题之前,先把链路追踪(Tracing)接上。 一旦生产环境出现故障,你绝对会想死磕到底是哪一次工具调用引发了崩溃。从第一天起,就把 Agent Tracing API 挂上。
-
服务端 MCP 服务器必须公网可达。 如果你的工具部署在私有网络内,请老老实实选择客户端 MCP 模式。
-
当工具定义超过 20 到 30 个时,工具搜索(Tool Search)将成为刚需。 在此之下,每次请求全量加载工具没啥问题;在此之上,利用工具搜索进行“懒加载”,能为你省下每一轮对话中高昂的输入 Token 成本。
什么是服务端工具
DigitalOcean 推理引擎的 服务端工具(Server-Side Tools) 允许你将工具执行直接嵌入到推理请求中。你可以沿用现有的模型访问密钥(Model Access Key),无需配置新的凭据,也不需要学习新的 API 接口。该功能目前已同时支持无服务器推理(Serverless Inference)和托管专用推理(Dedicated Inference)。
目前,你可以在单次推理请求中无缝接入以下五种外部能力:
1. 网页搜索(基于 Exa.ai 驱动) 依托 Exa 的神经搜索索引实现实时的网页搜索。模型自己决定何时发起搜索、运行查询,并将结果揉进回答中。你可以精准控制单次请求中搜索的最大次数(max_uses: 1 到 5 次)以及单次搜索返回的结果数量(max_results: 1 到 10 条)。该功能定价为每 1,000 次请求 10 美元。
2. 网页内容抓取(基于 Exa 驱动) 在推理过程中直接抓取并提取指定 URL 的具体内容。Exa 的提取技术能直接返回干净的、解析后的纯文本,而非冗余的原始 HTML,这极大地帮模型缩减了需要处理的 Token 数量。除了标准的 Token 计费外,不收取额外费用。
3. 知识库检索(Knowledge Base Retrieval) 赋予模型查询你私有数据的能力。你只需提供一个知识库 ID,API 就会自动检索相关内容并将其注入到模型响应中。
4. 用户自建的 MCP 服务器 将模型连接到你运行的任何远程模型上下文协议(Model Context Protocol)服务器。你只需在请求中传入服务器的 URL 和 Bearer Token。DigitalOcean 会搞定 MCP 的连接、工具发现和具体执行。你还能通过 allowed_tools 参数精细化控制允许模型调用你服务器上的哪些工具。
5. 工具搜索(支持 Anthropic 和 OpenAI 模型) 当你的工具定义超过 20 到 30 个时,每次请求都塞入所有定义会带来可观的输入 Token 开销。在需要对接多个内部系统(每个系统暴露若干工具)的复杂 Agent 中,工具数量轻松破 50 极其常见,这会导致每次请求的额外开销高达数百 Token。乘以每天成千上万次的调用,成本会像滚雪球一样吓人。
工具搜索(Tool Search)通过懒加载工具定义完美解决了这一痛点。被标记为 defer_loading: true 的工具不会在每次请求时都被死板地加载到上下文中,只有在模型明确需要它们时,才会动态加载。
对于 Anthropic 模型,该功能通过 Messages API 配合搜索工具实现(使用 tool_search_tool_regex_20251119 进行正则匹配,或使用 tool_search_tool_bm25_20251119 进行自然语言查询)。对于 OpenAI 模型,则通过 Responses API 配合 GPT-5.4+ 及 type: "tool_search" 来实现。
# Tool Search with Anthropic (Messages API)
import anthropic
client = anthropic.Anthropic(
base_url="https://inference.do-ai.run/v1",
api_key="your-model-access-key"
)
response = client.messages.create(
model="anthropic-claude-opus-4.8",
max_tokens=2048,
messages=[{"role": "user", "content": "What is the weather in zip code 94107?"}],
tools=[
# The search tool loads immediately
{
"type": "tool_search_tool_regex_20251119",
"name": "tool_search_tool_regex"
},
# These tools only load when the model searches for them
{
"name": "get_weather_by_zip",
"description": "Return current weather conditions for a US zip code.",
"input_schema": {
"type": "object",
"properties": {
"zip_code": {"type": "string"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["zip_code"]
},
"defer_loading": True
},
{
"name": "search_files",
"description": "Search through files in the workspace",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
},
"defer_loading": True
}
]
)
模型会自行搜索它需要的工具,仅加载那一个定义,然后发起调用。一旦跨过 20-30 个工具的门槛,这种机制省下的输入 Token 成本将会极其可观。
# Standard web search
from openai import OpenAI
client = OpenAI(
base_url="https://inference.do-ai.run/v1",
api_key="your-model-access-key"
)
response = client.chat.completions.create(
model="openai-gpt-4o",
messages=[{"role": "user", "content": "What changed in DigitalOcean pricing this month?"}],
tools=[{"type": "web_search", "max_uses": 3, "max_results": 5}]
)
# One request, one response
print(response.choices[0].message.content)
如果没有服务端工具,同样的内容你得折腾三步:把消息发给模型 $\rightarrow$ 接收到一个工具调用指令 $\rightarrow$ 在本地自己运行搜索 $\rightarrow$ 把搜索结果再发回给模型换取最终答案。而有了服务端工具,这一切都在单次 API 调用内完美闭环。
典型应用场景
1. 调研型 Agent
一个具备网页搜索和页面抓取能力的调研 Agent,能完美回答那些极度依赖实时信息的痛点问题:最新的价格政策、刚发布的产品变更、模型训练截止期之后爆发的新闻,或者任何需要聚合多源信息才能给出结论的任务。
服务端工具下的实现:
response = client.chat.completions.create(
model="openai-gpt-4o",
messages=[{
"role": "user",
"content": "Summarize the key changes to Kubernetes networking in the last 6 months and their implications for teams running microservices."
}],
tools=[{
"type": "web_search",
"max_uses": 5,
"max_results": 5
}]
)
模型自己决定什么时候去搜、搜什么关键词、搜几次,以及什么时候拿到了足够的信息来撰写这份总结。无论 Agent 在内部偷偷运行了多少次搜索,你的应用程序代码自始至终只需要写这一段。
2. 通过 MCP 对接内部系统的 AI 应用
如果你的团队已经为内部工具(如项目管理、排班系统、CRM 或内部私有 API)构建了 MCP 服务器,现在你可以直接将它们挂载到任何推理请求中,甚至不需要修改应用代码。
response = client.chat.completions.create(
model="openai-gpt-4o",
messages=[{
"role": "user",
"content": "Pull the open support tickets for our enterprise tier and draft a weekly digest for the team."
}],
tools=[{
"type": "mcp",
"server_label": "internal-crm",
"server_url": "https://tools.yourcompany.com/mcp",
"authorization": "Bearer your-mcp-token",
"allowed_tools": ["list-tickets", "get-ticket-details", "get-customer-info"]
}]
)
allowed_tools 列表控制了模型对你的 MCP 服务器拥有哪些权限。如果你不写这个参数,模型就能调用你服务器暴露的所有工具。因此,只列出当前任务必需的工具是最佳的安全生产实践。
注意: 你的 MCP 服务器必须允许公网访问。因为推理层是从 DigitalOcean 的网络发起连接的,而不是从你应用程序运行的本地网络环境发起的。
3. 混合使用多种工具
更复杂的 Agent 会在单个请求中组合多种工具。例如,一个尽职调查 Agent 可能会先通过网页搜索捞出某家公司的最新新闻,再抓取其官网的价格页面,同时查询内部知识库看自己公司和它有没有过历史交集——而这一切,都在一次推理调用中完成。
response = client.chat.completions.create(
model="openai-gpt-4o",
messages=[{
"role": "user",
"content": "We're evaluating Acme Corp as a vendor. What's their current product, recent news, and do we have any history with them?"
}],
tools=[
{
"type": "web_search",
"max_uses": 3,
"max_results": 5
},
{
"type": "knowledge_base_retrieval",
"knowledge_base_id": "vendor-history-kb"
}
]
)
模型会根据提示词(Prompt)中的具体任务,自主决定使用哪些工具以及它们的调用顺序。
核心博弈:延迟的权衡
-
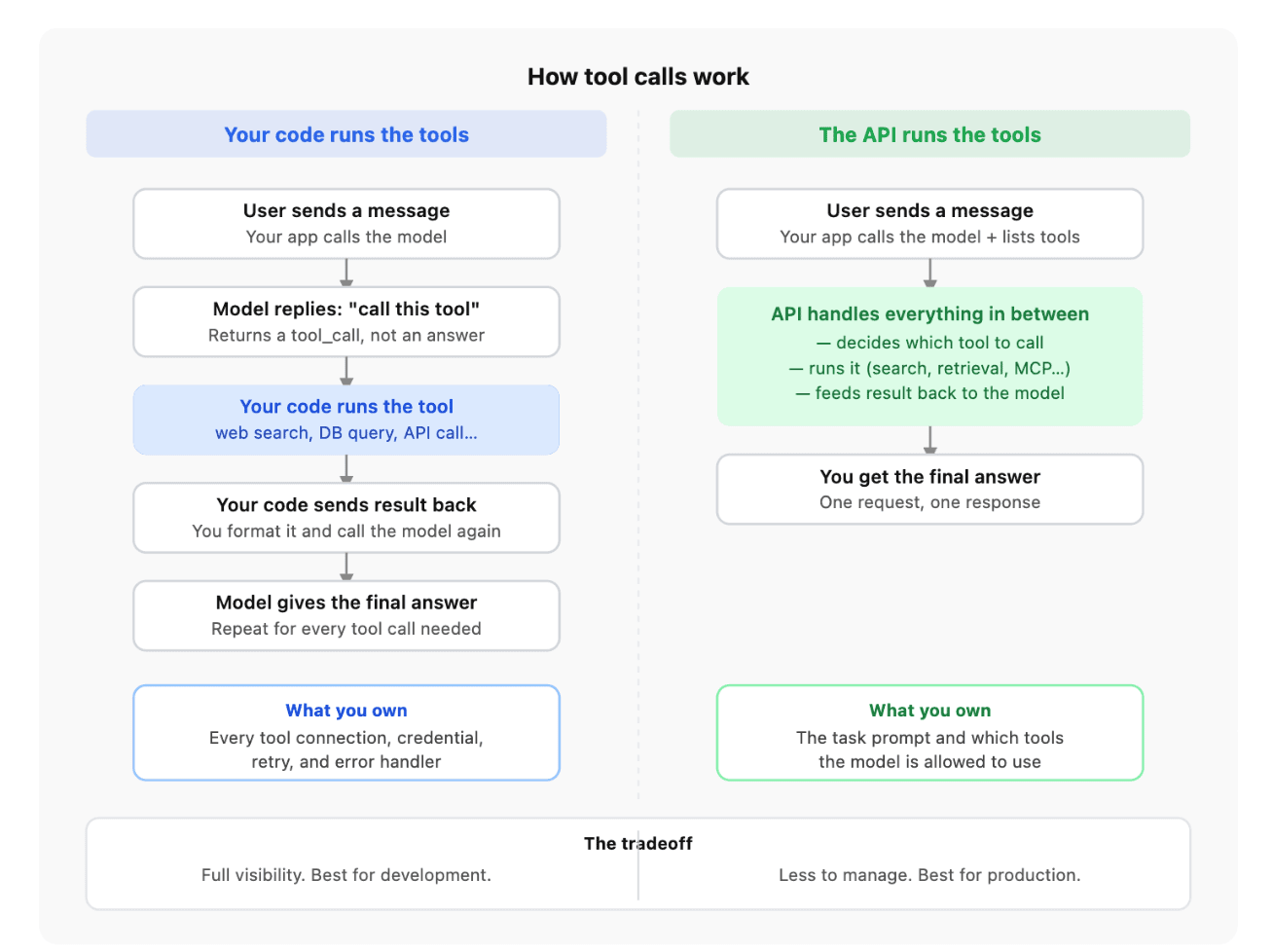
客户端执行(Client-side): 意味着你的应用代码亲自操刀工具。发消息 ->模型说“我要搜 X” -> 你的代码跑搜索->结果塞回模型 ->拿到最终答案。一切都在你的进程里,掌控度极高、本地极快,但你必须手写并维护每一步的脏活累活。
-
服务端执行(Server-Side): 意味着 DigitalOcean 把重活全包了。你只发一次请求,工具的调用、执行和结果回填在响应返回你之前就已经在云端闭环了。但代价是,外部网络的调用耗时现在转嫁到了这次请求内部,从而拉长了你的总响应时间。
客户端执行:数据表现
当你的代码自己跑工具时,耗时完全取决于工具在干嘛:
- 在自身进程里跑个函数(如输入验证、字符串格式化):< 1 ms
- 基于同机 stdio 连接运行的 MCP 服务器:根据生产环境部署实测,平均在 0.91 ms 到 1.10ms 之间。
- 跨网络调用外部 API 的 HTTP 请求:通常在 50ms 到 300ms 之间。
这些损耗在你的本地日志里一目了然。
服务端工具的数据表现
当 DigitalOcean 代劳调用工具时,这些调用耗时会被简单粗暴地累加到你的响应总时长中。不同工具的延迟画像截然不同:
- 网页搜索: DO 的网页搜索由 Exa 提供强力支持。Exa 维护的是一个预建的神经索引(Neural Index),而不是在收到请求时临时去爬网页。在 2026 年Proxyway对 15 家搜索 API 供应商的权威基准测试中,Exa 被归为索引类阵营:中位数延迟在 400ms 以下,且 p50 和 p95 之间几乎没有波动。相比之下,那些每次请求都要去实时抓取结果的传统 SERP API,中位数延迟普遍在 $600\text{ms}$ 到 700ms,且波动剧烈,部分供应商的 p95 甚至直接突破了 5 秒。
- 自建 MCP 服务器: 这里的阿喀琉斯之踵是冷启动(Cold Starts)。如果一个 MCP 服务器最近没干活,它在响应前必须重新初始化。对于一个基于 Node.js 的 MCP 服务器,光是加载运行时和基础模块就能吞掉 2 秒以上。如果你的服务器在多次请求之间没有做好保活,新对话的第一枪就得结结实实地吃下这笔冷启动保护费。
当延迟像多米诺骨牌一样累加
每一个工具调用都会把总耗时往上推。调用一次无伤大雅,真正要命的是 Agent 连续进行多次串行(Sequential)工具调用——耗时会疯狂叠罗汉。
举个例子,一个调研 Agent 使用 DO 托管的 Exa 搜索连续串行(in sequence)查了 3 次:按单次调用中位数 $< 400\text{ms}$ 来算,这 3 次一环扣一环的搜索,在模型甚至还没开始吐出第一个字之前,就已经悄悄给总响应时间叠加上了大约 1.2 秒的硬性搜索耗时。
这还是基于索引搜索的理想情况。换作传统实时搜索 API(中位数 600ms 至 700ms),一旦撞上 p95 超过 5 秒的极端长尾延迟,3 次串行下来可能直接奔着 15 秒去了。多加一次调用,你就多承担了一份撞上长尾延迟墙的概率。
如果你的 Agent 正在后台哼哧哼哧地做深度行业调研,多等几秒完全不是事。但如果你是在构建一个语音助手,或者用户眼巴巴等着一秒内给反应的实时应用,那每一毫秒都是钱。这种硬核实时场景下,客户端工具或极其精简的单步任务才是正解。
打造生产级 Agent 的三大军规
当工具执行移到服务端后,你虽然解放了双手不用管连接生命周期、重试和扩缩容,但别高兴得太早,上线前必须锁死这三件事:
1. 必须针对“工具调用失败”写死系统提示词
客户端模式下工具崩了会抛异常,你的代码可以拦截并走兜底逻辑。但服务端模式下,如果网页搜索查出来一坨空气,模型会假装无事发生,拿着空结果继续一本正经地瞎编,它可不会主动在返回的 JSON 里哭诉搜索失败。
解法简单粗暴:直接写进系统提示词(System Prompt)。例如:“如果知识库检索未返回任何相关结果,请如实告知用户,并引导用户换个换法重新提问。” 给模型一条清晰的退路,比让它在原地瞎猜强一万倍。
2. MCP 的“写操作(Write Operations)”必须具备幂等重试安全性
读操作(网页搜索、网页抓取、知识库检索)天生重试安全。请求超时了?再试一次,毫无副作用。
但通过自建 MCP 服务器搞“写操作”(比如扣款、改数据库、发邮件)就得打起十二分精神。如果请求超时了,你根本无从得知动作到底执行成功没有。标准姿势是为每个写操作分配一个全局唯一的请求 ID(Request ID),让你的 MCP 服务器据此去重。这样即使网络波动引发重试,也不会导致双重扣款或重复写入。
3. 告警必须能精准分清是哪一层工具塌房了
DO 托管的公共工具和你自建的私有 MCP 服务器走的是完全两条路。如果所有工具同时瘫痪,大概率是云端托管基础设施层挂了;如果网页搜索生龙活虎,但 MCP 调用全面溃败,那不用想,绝对是你自己的服务器崩了。
在搭建监控告警时,把这两者划清界限。把“工具故障”粗暴地归为一个告警大类会让运维人员无从下手。区分出 “DO 托管工具离线” 还是 “私有 MCP 服务器不可达”,能让你在半夜惊醒时一眼看清该去哪里接线救火。
选型指南:什么时候用客户端 工具vs 服务端工具?
优先选择【服务端工具】的场景:
-
你压根不想伺候基础设施。 网页搜索和数据检索的连接生命周期、凭据托管、失败重试、自动扩缩容,全都是实打实的工作量。当这些运维内耗超过了你对绝对控制权的渴望时,托管出去是明智的选择。
-
敏感凭据坚决不能下放到业务代码里。 Web API、内部敏感系统、第三方服务的 API Key 如果散落在应用代码各处就是安全灾难。服务端工具允许你把这些密码锁在更靠近执行端的地方。
-
团队内多个 Agent 或多名成员需要共享同一套工具。 客户端工具往往被死死限制在某一台机器或某一段特定的代码上下文里。而服务端工具直接挂在推理 Endpoint 上,任何只要有权限调用该模型的 Agent 都能无缝复用,免去重复配置的痛苦。
-
你正急需网页搜索和实时检索。 要不然你得自己去对接搜索服务商,还要手写那个恶心的 Tool Call 循环。
优先选择【客户端工具】的场景:
-
处于高频迭代的开发期,需要绝对透明的视野。 客户端执行是纯透明的。你可以打印每一次工具调用的 Payload、打断点、本地完美复现 Bug。而服务端模式下,你必须依赖追踪 API 才能勉强看清发生了什么。
-
工具本身极轻、极快,且不需要网络调用。 比如纯内存运行的 Schema 验证、字符串解析、数学计算。在客户端跑只要不足一毫秒,移到服务端反而白白搭进去一次网络往返的开销,纯属画蛇添足。
-
延迟预算被卡得死死的。 如果你在做语音助手,用户要求 400ms 内必须给动静,而模型推理本身就要吃掉 300ms,那对不起,你容不下任何一次多余的服务端网络绕行。
-
工具逻辑严重依赖你当前的应用程序状态。 比如工具要读取本地会话数据、内存状态,或者你服务器握着的数据库长连接。这些东西极难剥离成一个公网可达的 MCP 服务器,留在客户端是最好的解药。
最务实的落地路径
在生产环境中,基础设施的维护成本通常是核心痛点,因此服务端工具是极佳的默认方案。但在开发环境中,看清每一步细节才是头等大事,因此客户端工具是无可替代的利器。
最聪明的做法是:先在本地用客户端工具把 Agent 盘活,把观测链路调通,把各种失败边界摸透。等到准备正式部署上线、不想再为底层连接和服务器扩容操心时,再顺理成章地一键切换到服务端模式。
与 LangChain 及 OpenAI Function Calling 的横向对比
如果你之前是用 LangChain 或 OpenAI 原生 API 搭建 Agent 的,可以通过下表一眼看清它们哲学上的代差:
| 维度 | LangChain 工具机制 | OpenAI Responses API 内置工具 | DigitalOcean 服务端工具 |
|---|---|---|---|
| 执行位置 | 完全在你的客户端进程里 | 依托 OpenAI 云端执行 | 依托 DigitalOcean 云端执行 |
| 基础设施维护成本 | 极高(网络连接、重试、错误处理全得自己手写) | 极低(云端全包) | 极低(云端全包) |
| 模型绑定局限性 | 无(一套工具代码,后面换成任何模型都能跑) | 极度绑定(比如为了用它的内置网页搜索写的代码,想换成 Claude 就得全部推翻重写) | 无(解耦设计,工具配置一次,DO 模型目录里的 Claude、GPT 等任意模型无缝切换) |
| 生态开放度 | 取决于你本地怎么写 | 封闭在 OpenAI 自身生态及指定组件内 | 极其开放(除内置工具外,支持通过 MCP 标准无缝桥接任何自建基础设施) |
服务端 MCP vs 客户端 MCP
MCP(Model Context Protocol,模型上下文协议)是 AI 模型连接外部工具和数据源的标准方式。你可以把它看作是一个插件系统:你构建一个微型服务器,把数据库查询或 CRM 搜索等内部工具暴露出来,模型就能在对话过程中直接调用这些工具。
举个例子: 你有一个用于查询客户合同的内部 API。你把它打包成一个 MCP 服务器。当用户询问“帮我看看 Acme Corp 还有哪些生效的合同”时,模型会直接调用你这个工具,而不需要你死板地把合同查询逻辑写死在 Prompt(提示词)里。
这里的核心问题在于:到底由谁来管理这条连接?
客户端 MCP(Client-Side MCP)
在客户端 MCP 模式下,你的应用程序代码直接负责管理与 MCP 服务器的连接。模型转头告诉你的代码:“我需要调用这个工具”,你的代码亲自去调 MCP、拿结果,最后把结果倒手喂回给模型。
延迟表现画像:
-
如果 MCP 服务器和你的应用跑在同一台机器上: 连接是直接且极快的,单次调用只需 $0.91\text{ms}$ 到 $1.10\text{ms}$。这是性能的终极天花板(最理想的情况)。
-
如果 MCP 服务器是个独立的网络服务(远程连接,但处于常驻活跃状态): 跑一次“热调用(Warm Call)”大约需要 $2\text{ms}$ 到 $3\text{ms}$,这就是个典型的近距离服务器 HTTP 往返耗时。
-
如果 MCP 服务器很久没被临幸,需要冷启动(Cold Start): 新开一枪的第一轮调用可能要耗时 $2,000\text{ms}$ 以上(2秒+),光是初始化就能卡半天,之后才能干正事。
你可以记录每一次工具调用,看清发了啥、回了啥,还能自己拍板超时时间、随心所欲处理报错。一旦本地搞砸了,复现 Bug 极其方便。
典型案例: 你正在做一个代码助手,可以帮你检查代码库里有没有某个函数。你本地跑了一个 MCP 服务器来对仓库建索引。当开发者问“这个工具类函数存在了吗?”,模型直接调你本地的 MCP 服务器,服务器秒查索引并在 $1\text{ms}$ 左右返回结果。一切都在你本地机器上飙车,没有跨网调用,不用管密码凭据,模型要啥、回来啥你尽收眼底。
服务端 MCP(Server-Side MCP)
换到服务端 MCP,你直接当甩手掌柜。你只要在 DigitalOcean 的推理层配置好:“我的 MCP 服务器在公网这个 URL,它能调这几个工具。”当模型需要工具时,DO 会亲自跟你的服务器握手、调接口、回填结果,你的应用代码在中间全程当空气,啥都不用管。
延迟表现画像:
跨网络调用一个远程 MCP 服务器的“热连接”理论上只要 $2\text{ms}$ 到 $3\text{ms}$,这是低延迟 HTTP 连接的常规操作。但现实很骨感,真实世界里的 MCP 流量根本热不起来。根据对生产环境 MCP 部署的宏观研究表明:工具调用的延迟中位数(p50)在 $320\text{ms}$,p95 在 $1,840\text{ms}$,而 p99 则直接飙到了恐怖的 $6,200\text{ms}$(6秒多)。
这个巨大的长尾延迟几乎全是冷启动贡献的。当一个基于 Node.js 的 MCP 服务器冷启动时,光是加载大大小小的依赖模块就能在原地死卡 2 秒以上,这时连第一个工具调用的边都没摸着。
如果你的服务器没有提前预热,或者在多次会话间没做保活,那么新对话的第一枪就得结结实实地吃下这笔冷启动保护费。在 p99 的极端情况下,你的 Agent 还没憋出一个有用的字,6 秒就已经过去了。不过,这 6 秒并不是 MCP 协议本身无能,它只是客观反映了研究报告中各种参差不齐的服务器实现撞上冷启动的长尾怪相。一个维护良好、时刻保持“温热”的服务器,其实际跑出来的延迟会非常接近 $2\text{ms}$ 到 $3\text{ms}$ 的热调用基准线。长尾延迟从来不是 MCP 的错,那是冷启动没做好的锅。请务必让你的 MCP 服务器持续运行并保持连接活跃。
典型案例: 还是刚才的代码助手,但现在要部署上线给全公司用了。与其让每个开发都在自己电脑上跑个本地 MCP,不如直接在公网上搭一个全公司共享的 MCP 服务器。因为全公司都在高频调用它,这个服务器会自动维持在“温热”状态,调用耗时直接从 2 秒多暴降到 $2\text{ms}$ - $3\text{ms}$ 级别。每次推理请求只需把 URL 和 Token 顺过去,DO 的基础设施就能帮你打通一切,团队里的 Agent 都能无缝复用,谁也不用在自己电脑上折腾本地服务器。
{
"type": "mcp",
"server_label": "my-internal-api",
"server_url": "https://api.mycompany.com/mcp",
"authorization": "Bearer your-secret",
"allowed_tools": ["get-contract", "list-open-items", "search-customers"]
}
全方位博弈:核心维度对比(How they compare)
-
活儿是谁干的(Who does the work): 客户端 MCP 模式下,你的应用代码得承包全套:建连接、调工具、等结果、喂回模型。而服务端 MCP 模式下,这些包袱全甩给了 DigitalOcean 的基础设施。你的代码只管发一次请求,剩下的在云端全自动闭狂。
-
密码凭据存哪儿(Where your credentials live): 客户端模式下,你的 API Key 和 Secret 稳妥地呆在应用程序内部(环境变量、密钥管理器或配置文件)。服务端模式下,你通过 HTTPS 直接把凭据作为推理请求的一部分发过去。两路通车,怎么选取决于你们团队的安全规范。
-
你能看清多少细节(How much you can see): 客户端给你大权在握的完全可视性:每一个工具调用都躺在你的本地日志里,发了啥、回了啥一目了然,本地 Debug 极其方便。而到了服务端,工具调用直接在推理层内部黑盒化消化了,你必须借助 Tracing API 才能换回同等粒度的监控视野。
-
谁来为慢启动买单(Who is responsible for slow starts): 不管走哪条路,冷启动(Cold Starts)都是你避不开的雷。DigitalOcean 确实帮你在它那一侧管好了网络连接,但如果你的 MCP 服务器因为长时间没人调而偷偷睡着了(特别是 Node.js 服务器,重新拉起往往需要 2 秒甚至更久),这段卡顿依然会直接体现在响应时间上。不过,在服务端的多 Agent 共享配置下,各路汇聚过来的流量会自动给服务器“天然保活”。
-
服务器要不要挂到公网(Whether your server needs to be on the internet): 客户端 MCP 连接极其灵活,只要你应用能连过去就行:私有局域网、你自己的开发机、或是内网服务器都行。但服务端 MCP 是从 DigitalOcean 的网络发起外呼的,这意味着你的 MCP 服务器必须拥有一个合法的公网 URL。如果你的工具死死锁在防火墙后面或私有 VPC 里,在不做额外网络穿透的前提下,客户端是你的唯一通路。
-
多个 Agent 能否共享同一套工具(Whether multiple agents can share the same tools): 客户端工具是跟运行你代码的机器或进程死死绑定的。如果有三个不同的 Agent 都想调同一个工具,每个 Agent 都得自己去握手建一条连接。而服务端工具直接锚定在你的推理 Endpoint 上,任何有权访问该端点的 Agent 都能无缝复用,绝无重复配置的内耗。
-
工具崩了听谁的(What happens when a tool fails): 在客户端,你是重试逻辑、走备用数据源还是报特定错误码的绝对主宰。而在服务端,推理层会按照系统默认的策略自动处理重试。对绝大多数生产场景来说,默认策略完全够用;但如果你的 Agent 要求对工具失败后的下一步动作进行微秒级的精准控制,客户端才是你的归宿。
高能盲区:当工具脱离你的进程运行,如何做可观测性?
当工具运行在自己的代码里时,Debug 极其简单直观:哪里崩了报哪里,看清报错,上去修复。可一旦工具住进了云端推理层,你就失去了这种直观的视野。上线部署前,请务必死磕以下三件事:
1. 从第一天起,就把链路追踪(Tracing)接上
客户端工具的每一次调用都写在你的本地日志里,而服务端工具的执行细节全在 DigitalOcean 的大坝内部。务必接入 Agent Tracing API 来盘算每次工具调用的真金白银和耗时成本。否则,一旦某个请求响应极慢,你根本抓瞎:到底是因为模型本身推理慢?还是网页搜索卡了?亦或是 MCP 服务器正在冷启动?
2. 工具延迟必须跟总响应时间剥离、单独监控
对 Agent 而言,“总响应时间”是一个和稀泥的粗糙指标。你必须精准捕捉:单次工具调用耗时多久?单个请求到底疯狂套娃调用了多少次工具?工具返回空结果(无用功)的频率有多高? DigitalOcean 的控制面板(Control Panel)只能给你一堆聚合后的宏观指标,想看单个工具的微观拆解,必须死磕 Tracing API 或自己做埋点。
3. 必须把“工具故障”和“Agent 故障”划清界限
当业务反馈“Agent 不好使了”时,底层往往藏着两种截然不同的死法:
-
工具塌房了: 搜索超时,或者知识库检索回来一坨空气。
-
工具没毛病,但模型智商掉线了: 工具把正确的数据喂到了模型嘴边,模型还是把答案做错了。
这完全是两个维度的病因。前者是纯粹的基础设施问题,得修网络和服务器;后者是 Prompt 问题,得调优提示词。 如果把它们混在同一个指标里统计,最终结果就是两边都诊断不明白。
常见问题解答(FAQs)
-
Q:目前在服务端我能直接调用哪些工具?
- A: 网页搜索(Web Search)、网页抓取(Web Fetch)、知识库检索(Knowledge Base Retrieval)、用户自建的 MCP 服务器,以及支持 Anthropic 和 OpenAI 模型的工具搜索(Tool Search,即懒加载机制)。
-
Q:使用服务端工具需要额外掏钱吗?
- A: 知识库检索、MCP 以及工具搜索完全免费,只收取标准的模型推理 Token 费。唯独网页搜索是按量计费的,价格为每 1,000 次请求 10 美元。
-
Q:我能不能在一个 Agent 里既用客户端工具,又用服务端工具?
- A: 完全可以。 你完全可以在推理请求里捎带上服务端的工具定义,同时在自己的本地代码里拦截并处理另外一部分工具。它们互不干扰,配合默契。
-
Q:使用服务端 MCP,我的 MCP 服务器必须挂到公网上吗?
- A: 是的。 因为 DigitalOcean 的推理层要从它自己的云网络跨越公网来敲你服务器的门,你必须给它一个公网可达的 URL。如果你的企业合规策略不允许,请老老实实退回客户端 MCP 模式。
-
Q:如果服务端工具在请求进行到一半时崩了会怎样?
- A: 模型会拿着已经拿到的残缺、部分结果硬着头皮继续往下推理。而且它并不一定会老实告诉你工具有个地方没吐出数据。所以,一定要在系统提示词(System Prompt)里写死死:“如果工具返回空结果,应该如何应对”。
-
Q:服务端工具跑得慢,我该怎么 Debug?
- A: 接入 Agent Tracing API。它会把时间打散,精确还原每一段工具调用分别卡了多少毫秒,一眼就能看出罪魁祸首到底是模型推理本身卡了,还是某一个特定的外部工具拖了后腿。
-
Q:什么是工具搜索(Tool Search)?什么时候该开启?
- A: 工具搜索是一种对工具定义的懒加载(Lazy-loading)技术。凡是打了
defer_loading: true标签的工具,在初始请求时都不会被死板地塞进上下文,只有在模型明确发出搜索并需要它时才会动态加载。当你的 Agent 手握大几十个工具、且想疯狂压低输入 Token 成本时,闭眼开它。
- A: 工具搜索是一种对工具定义的懒加载(Lazy-loading)技术。凡是打了
-
Q:什么情况下我应该死守客户端工具不动摇?
- A: 项目还处于早期开发阶段需要频繁本地 Debug 时;工具所在的网络是绝对私密的内网环境时;或者你的延迟预算被压到了极限、容不下哪怕多一次云端网络绕行时。
技术背后真正值得看懂的“范式转变”
把工具执行移到服务端,本质上是重新划分了复杂度的归属。
那些原本需要你亲自肉搏的基础设施脏活(网络连接池、凭据托管、重试熔断、弹性扩缩容)全部被移交给了托管层。你的 Agent 业务代码变得前所未有的清爽,你们团队需要承担的运维暴露面也大幅收缩。
但是 ,构建 Agent 最难的那部分核心逻辑,并不会随着这种漂移而凭空消失。 如何优雅地为工具失败写兜底提示词、如何给 MCP 服务器做高频保活避免冷启动、如何打通指标把工具错误和模型幻觉精准剥离、如何科学地做埋点和监控——这些硬骨头依然是你的工作。
唯一的区别在于:以前你是在一边修着漏水的地暖水管、一边盖高楼;而现在,你终于可以站在坚实稳固的地基之上,全神贯注地去打磨你的上层 AI 建筑了。
无论你选哪家云厂商,这些技术博弈和底层逻辑都是完全通用的。架构的底层规律,从来不会因为你把推理模型托管在哪个机房而发生改变。
如果你此刻正在纠结选型,请参考这份极简版的判断方法:
如果你当前最大的痛点是基础设施的运维内耗(天天在跟凭据安全、连接断线、重试失败、扩容扛不住死磕),请果断上服务端工具。
如果你当前最大的痛点是看不清链路细节,或者要求极度变态的绝对控制权,请死守客户端工具。
如果你还在观望摸索,那就先从客户端写起。等到把所有的失败边界、长尾延迟都肉身踩过一遍,且基础设施的维护成本已经开始严重恶心到你的开发效率时,再顺理成章地重构上云。