
DigitalOcean AI推理云推出了无服务器推理(Serverless Inference)。它是一个托管 API,让你无需创建GPU云服务器、无需管理基础设施,即可运行 Claude、GPT-4o、DeepSeek、GLM、Qwen、Kimi 和 Mistral 等大语言模型。
它的设计初衷就是简单:无需配置 GPU、无需配置服务器,也无需管理扩缩容逻辑。 你只需要向一个端点(endpoint)发送请求即可。
该 API 支持来自 Anthropic、OpenAI、Meta、Mistral、DeepSeek 等大厂的模型——所有这些模型都统一在同一个 base URL 之后。
最方便的是,它与 OpenAI 的 API 完全兼容。
也就是说,如果你已经在使用 OpenAI Python SDK、LangChain 或 LlamaIndex 这类工具,或者 任何受支持的模型,它们都能直接运行。你只需更换后端,无需重写你的应用。
同样的方法也适用于 DigitalOcean 智能代理(Agents)——即与你自己的文档或知识库连接的模型。
为什么要用 DigitalOcean Inference?
这种方案有几个突出的优势——尤其是当你已经在 DigitalOcean 上构建应用,或者想要在大语言模型的使用上获得更多灵活性的时候。
- 一把钥匙开所有门:你不需要为 OpenAI、Anthropic、Mistral 等各自管理独立的密钥。一个 DigitalOcean API 密钥就能访问所有模型——Claude、GPT-4o、LLaMA 3、Mistral 等等。
- 更低的成本:对于很多任务来说,这比直接走模型厂商要划算得多。
- 统一计费:所有用量都体现在同一个账单里,和你的应用、Spaces、数据库以及你在 DO 上运行的其他一切一起出现在 DigitalOcean 的账单上。不同平台之间不会再出现意外费用。
- 开源模型的隐私保障:如果你使用的是开放权重模型(如 LLaMA 或 Mistral),你的提示词和补全内容不会被记录或用于训练。
- 无需改动 SDK:OpenAI SDK 直接就能用。你也可以用同样的方式使用 LangChain 或 LlamaIndex 等库——只需修改 base URL 即可。
无服务器推理的原理
底层一切操作都通过 OpenAI 的方法执行:
client.chat.completions.create()
你唯一需要更改的,是初始化客户端时的 base_url:
- 无服务器推理(通用模型):
https://inference.do-ai.run/v1/ - 智能代理(基于自有数据的上下文推理):
https://<your-agent-id>.agents.do-ai.run/api/v1/
就这么简单——接下来看看实际中怎么操作。
安装 OpenAI SDK
运行以下命令在你的机器上安装 OpenAI SDK:
pip install openai python-dotenv
示例 1:列出可用模型
这段代码会列出 DigitalOcean 无服务器推理的所有可用模型,跟你平时用 OpenAI 的代码完全一样——只是把目标地址指向了 DigitalOcean 的端点(base_url)。
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# List all available models
try:
models = client.models.list()
print("Available models:")
for model in models.data:
print(f"- {model.id}")
except Exception as e:
print(f"Error listing models: {e}")
示例 2:运行一次简单的对话补全
我们用的还是同一个 .chat.completions.create() 方法,区别仅在于 base_url 不同。
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# Run a simple chat completion
try:
response = client.chat.completions.create(
model="llama3-8b-instruct", # Swap in any supported model
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a fun fact about octopuses."}
]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error during completion: {e}")
示例 3:流式响应
想要逐 token 流式返回的响应?只需加上 stream=True,然后循环读取数据块即可。
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://inference.do-ai.run/v1/", # DO's Inference endpoint
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
# Run a simple chat completion with streaming
try:
stream = client.chat.completions.create(
model="llama3-8b-instruct", # Swap in any supported model
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a fun fact about octopuses."}
],
stream=True
)
for event in stream:
if event.choices[0].delta.content is not None:
print(event.choices[0].delta.content, end='', flush=True)
print() # Add a newline at the end
except Exception as e:
print(f"Error during completion: {e}")
那智能代理呢?
DigitalOcean 还提供了智能代理(AI Agents)——这些是搭配了自定义知识库的大语言模型。你可以上传文档、添加 URL、纳入结构化内容,甚至连接 DigitalOcean Spaces 对象存储桶或 Amazon S3 存储桶作为数据源。代理会结合这些上下文来给出回答。对于内部工具、文档机器人或特定领域的助手来说,非常实用。
你仍然使用 .chat.completions.create() —— 唯一不同的还是 base_url。不过现在,你的回答是基于自己的数据生成的。
注:使用DigitalOcean 无服务器推理时,base URL 是固定的。使用 Agents 时,它的 URL 取决于你的代理,并且需要追加 /api/v1。
python
client = OpenAI(
base_url="https://your-agent-id.agents.do-ai.run/api/v1/",
api_key=os.getenv("DIGITAL_OCEAN_MODEL_ACCESS_KEY")
)
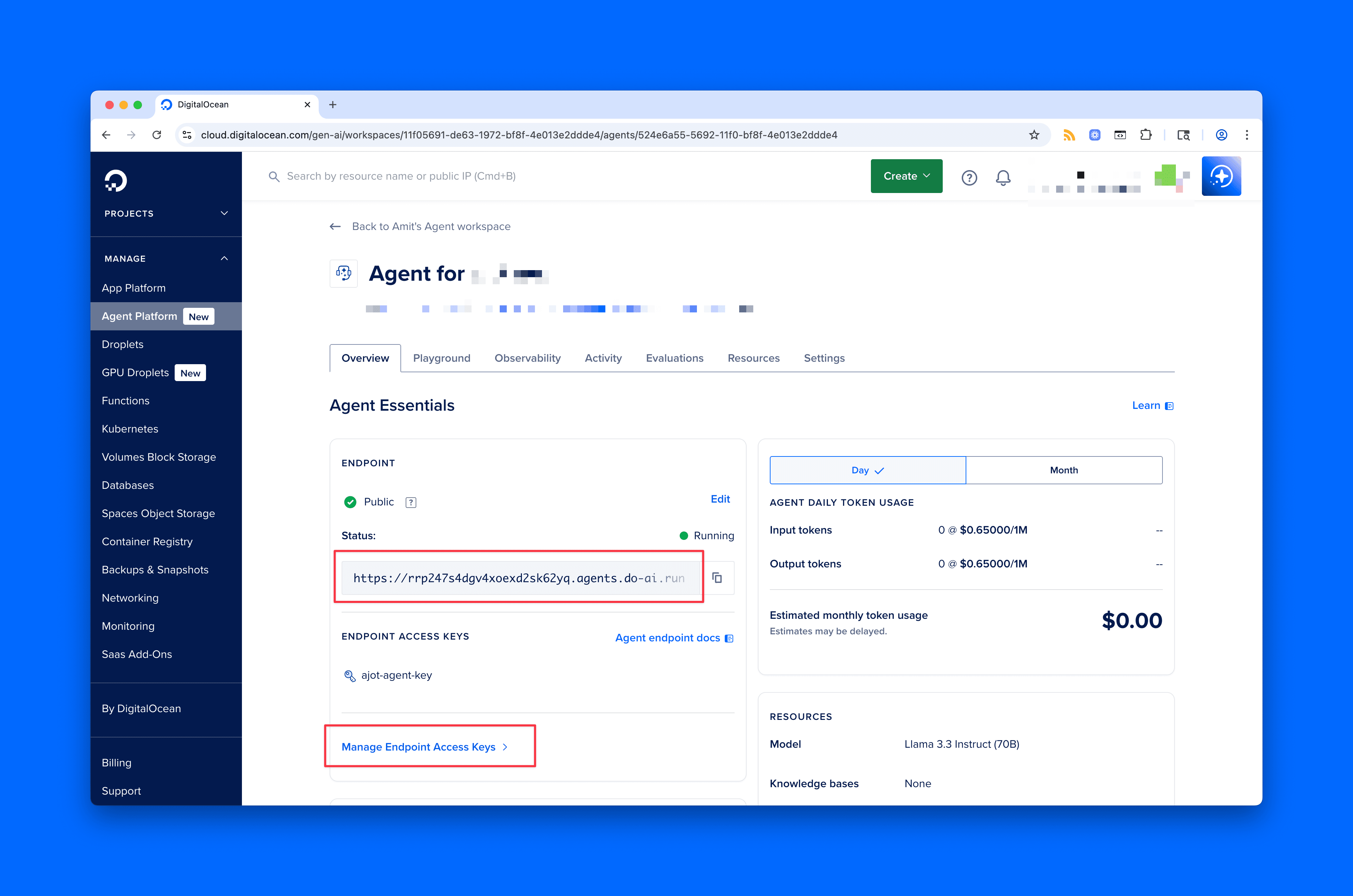
示例 4:使用智能代理(非流式)
这是一个标准的代理请求,用的还是 .chat.completions.create() ——跟之前的方法一样。
唯一的实际变化是 base_url,它指向你的代理专属端点(加上 /api/v1)。使用 Inference 时,base URL 是固定的;使用 Agents 时,它取决于你的代理,你只需在后面追加 /api/v1。
这里我们在请求体中还加上了 include_retrieval_info=True。这会告诉 API 额外返回代理从知识库中检索了哪些内容来生成回答的元数据。
from openai import OpenAI
from dotenv import load_dotenv
import os
import json
load_dotenv()
try:
# 创建一个指向智能代理端点的新客户端
agents_client = OpenAI(
base_url="https://rrp247s4dgv4xoexd2sk62yq.agents.do-ai.run/api/v1/",
api_key=os.getenv("AJOT_AGENT_KEY")
)
# 通过智能代理端点发送一条简单的文本请求
response = agents_client.chat.completions.create(
model="openai-gpt-4o-mini",
messages=[{
"role": "user",
"content": "你好!Amit 是谁?"
}],
extra_body = {"include_retrieval_info": True}
)
print(f"\n智能代理端点的响应:{response.choices[0].message.content}")
response_dict = response.to_dict()
print("\n完整的检索对象:")
print(json.dumps(response_dict["retrieval"], indent=2))
except Exception as e:
print(f"智能代理端点出错:{e}")
示例 5:使用智能代理(流式输出 + 检索信息)
这里唯一的改动是启用了 stream=True,让响应在生成的同时实时返回。其他一切不变。
from openai import OpenAI
from dotenv import load_dotenv
import os
import json
load_dotenv()
try:
# 创建一个指向智能代理端点的新客户端
agents_client = OpenAI(
base_url="https://rrp247s4dgv4xoexd2sk62yq.agents.do-ai.run/api/v1/",
api_key=os.getenv("AJOT_AGENT_KEY")
)
# 通过智能代理端点发送一条带流式的文本请求
stream = agents_client.chat.completions.create(
model="openai-gpt-4o-mini",
messages=[{
"role": "user",
"content": "你好!Amit 是谁?"
}],
extra_body = {"include_retrieval_info": True},
stream=True,
)
for event in stream:
if event.choices[0].delta.content is not None:
print(event.choices[0].delta.content, end='', flush=True)
print() # 末尾换行
except Exception as e:
print(f"智能代理端点出错:{e}")
总结
回顾一下重点:
- 你可以直接在 DigitalOcean 的无服务器推理和智能代理上使用 OpenAI SDK。
- 你唯一需要更改的只有 base_url——其他一切保持不变。
- 使用
https://inference.do-ai.run/v1/访问 LLaMA 3、GPT-4o、Claude 等通用模型。 - 使用你的代理专属 URL(加上
/api/v1)连接你自己的文档或知识库。 - 全部通过
.chat.completions.create()完成——无需学习新方法。 - 可以用
stream=True启用流式输出,用include_retrieval_info=True获取检索信息。
这样一来,你可以轻松测试多种模型、切换后端、或者将模型接入自己的内容——所有这一切都不需要改动现有代码。
更多资源
- 什么是无服务器推理?:无服务器推理的原理及适用场景的简要介绍。
- 如何使用无服务器推理:无服务器推理的官方文档。
- 受支持的模型列表:所有可用模型的完整清单(OpenAI、Claude、DeepSeek、Kimi、GLM、Qwen 等)。
- 创建并配置 DigitalOcean 智能代理:构建使用自有知识库回答问题的代理的教程。
- Inference API 参考:模式、端点及底层实现细节。
- OpenAI Python SDK:本文所有内容所依赖的官方 SDK。
相关产品与选型


